


 雷达卡
雷达卡






拥有十年供应链从业经验,我想聊聊,为什么这个领域能让数据科学家的专业能力真正体现价值。

踏入2026年,我的领英收件箱里塞满了数据科学家的咨询消息。
大家的问题和顾虑如出一辙:投身供应链数据科学,到底是不是正确的选择?
深耕供应链数据科学领域十载,同时坚持撰写博客五年,我对这个问题有非常明确的看法。
供应链,堪称数据科学家的绝佳实践场。

这里不仅有丰富的业务难题、精妙的数学模型,更能创造实实在在的业务价值。
但我并不想替你规划职业方向。
在这篇文章里,我会坦诚分享这个领域中那些让我满怀热忱的机遇,以及时常让人困扰的挑战。
更重要的是,我会结合博客中分享的教程与案例,教你如何亲自探索这个领域。
你可以借此判断,供应链分析是否真的适合自己。
为什么我们需要供应链分析?
什么是供应链?
供应链的定义通常是:多方主体围绕物料、信息、资金的流转开展协作,最终实现满足客户需求的目标。

工厂、仓库与计划团队通过各类系统沟通协作、交换信息。

这些系统会将供应链全流程的业务活动,以交易数据的形式存储在数据库中。
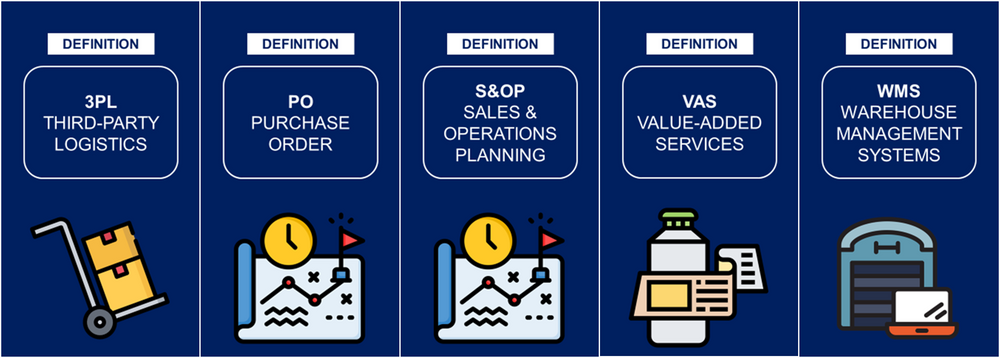
仓库管理系统(WMS):记录所有入库(进入仓库的货物流)和出库(运出仓库的货物流)交易数据。
企业资源规划系统(ERP):存储面向供应商的采购订单与面向客户的发票信息。
运输管理系统(TMS):追踪所有从仓库发出的货物,并在送达时发送通知。
由于无法对供应链中的每一批货物进行实时追踪,这些数据就成了监控运营状况的唯一抓手。
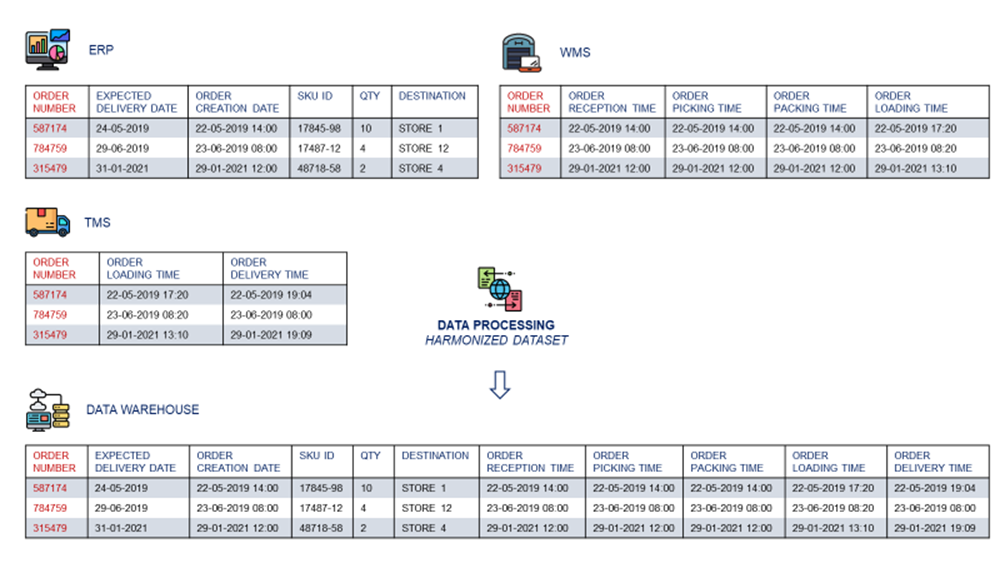
正因如此,供应链分析应运而生。它是企业从价值链各环节的数据中挖掘价值、提炼洞见的方法论。
我们需要对这些数据加以利用,但具体要实现什么目标呢?
一、描述性分析:为业务团队提供运营可视化能力
企业的首要需求,是实现运营可视化。
我曾有过这样一段经历:合作的一位物流总监,甚至无法说清公司最大的配送中心里有多少个托盘的货物。
而这,正是2026年绝大多数企业的真实写照。
我承认,这听起来远不如机器学习或高级优化算法那般酷炫。
但这却是大多数企业供应链分析之路的起点,也是你能快速创造价值的切入点!
(配图:桑基图:一种可输出战略洞见的简洁可视化图表——由萨米尔·萨西制作)
在我担任供应链解决方案设计师的初期,我发现业务团队往往淹没在海量数据中,却无法从中识别规律。
他们知道业务出现了问题,却找不到问题的根源。
比如运营经理会困惑:“我们想尽办法提高单日订单处理量,但始终没有效果,根本不知道问题出在哪!”
曾经有一家美妆零售商的仓库找到我,希望我协助优化仓库运营流程,提升电商订单的处理能力。

每年双十一期间,中国的电商购物节会让订单量暴增十倍。
运营经理反馈:“我们扩招了大量操作人员,但订单处理能力并没有明显提升。”
为了找到根本原因,我决定亲自到仓库一线,观察高峰期的作业班次。
很快我就发现,仓库的部分巷道里挤满了操作人员,大家都在排队等待拣货。
我推测这就是问题的症结,但我需要用数据证明这一点,并清晰地呈现给运营经理。
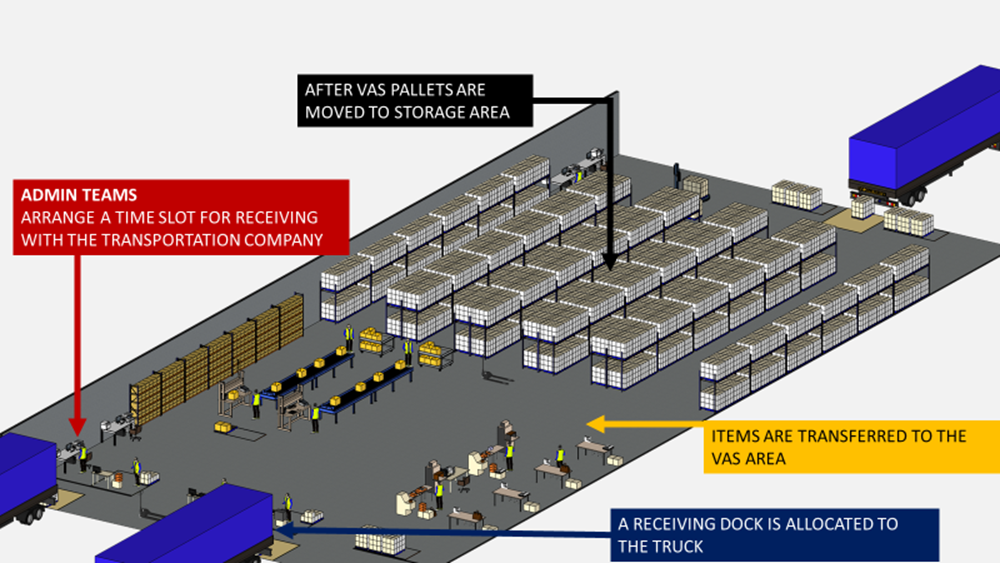
这张热力图展示了各存储区域的订单占比,正是借助它,我们迅速锁定了问题根源。
业务团队原本就知道部分区域的SKU周转率较高,但没想到竟达到了如此悬殊的程度。
运营经理当即决定:“必须把高周转率的SKU分散到仓库各个区域,避免巷道拥堵。”
这个简单的可视化图表,是我从Kaggle的探索性数据分析(EDA)中学到的技巧。而它,正是后续一系列复杂优化研究的开端,相关内容我已整理成系列文章发布。

即便没有深度学习或复杂的优化模型加持,也绝不要低估“选对可视化方式解决实际业务问题”的价值。
正是从这个简单的图表出发,我们完成了整个运营流程的重构,不仅成功续签了与这家客户的合作协议,还为公司带来了数百万欧元的收入增长。
二、诊断性分析:用数据支撑根因分析
如果想要迎接更高的技术挑战,我们可以更进一步。
接下来我要介绍一套方法论,它也是我在供应链数据科学领域最青睐的实践工具:精益六西格玛。

精益六西格玛是一套结构化的流程改进方法论,它借助统计工具验证假设,驱动流程优化。
为什么我推崇精益六西格玛?因为它要求所有假设都必须有统计数据支撑,能倒逼我们保持严谨的分析态度。
业务团队每天都会基于经验做出各种判断,但这些判断往往缺乏数据支持——毕竟他们深陷于繁杂的日常运营工作中,无暇兼顾数据分析。
而我们可以运用精益六西格玛的方法,用统计数据为他们提供决策依据。
我第一次运用这套方法,是为北美一家工厂的运输团队提供支持。

这家工厂的原料运输经理负责两条运输路线的物资接收工作:
路线1:路况复杂,交通拥堵频发;
路线2:全程畅通,道路条件优良。
外部的物流服务商负责将运输订单分配给一组司机(D1、D2、D3)。
问题出在哪?
当订单被分配至北部区域配送中心时,订单确认的前置时间比南部配送中心高出35%。
运输经理推测:“我们怀疑司机们都在刻意回避北部的运输路线。”
在仓促下结论(甚至与司机团队产生冲突)之前,我们决定先分析过往的运输订单确认数据。
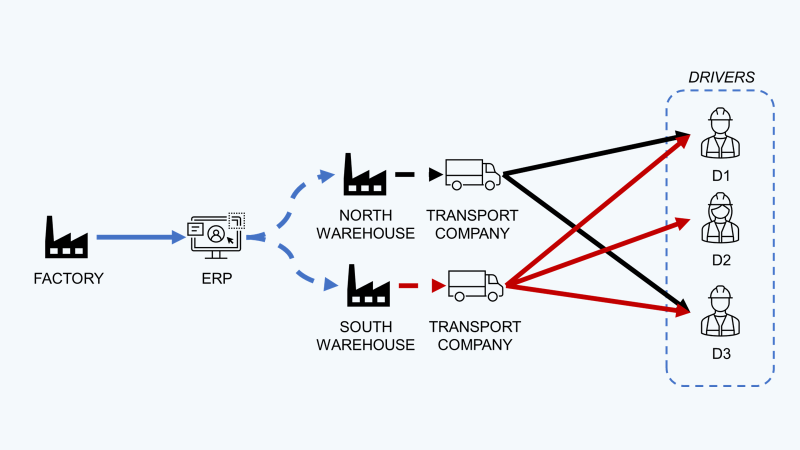
我们运用交叉验证和卡方检验展开分析,结果表明:没有显著的统计证据能证明,司机分配与配送中心的地理位置存在关联。
这个结论帮助团队排除了司机偏好的因素,转而探索其他可能的根本原因。
如果你想了解更详细的分析方法(包括带源代码的案例),可以观看这些短视频教程:
Lean Six Sigma with Python | Kruskal-Wallis Test Lean Six Sigma with Python | Chi-Squared Test Lean Six Sigma with Python | Logistic Regression
掌握了描述性分析和诊断性分析这两类工具,你就能定位仓库、工厂、计划部门等绝大多数业务场景下的运营问题根源。
比如:为什么调整操作人员班次后,生产效率反而下降了?为什么某一区域的拣货差错率上升了20%?为什么某条货运路线的前置时间莫名增加了一天?
用有统计依据的方法论解答这些问题,能帮助业务团队制定切实可行的改进方案。
三、规范性分析:用优化模型辅助决策
规范性分析的核心目标,是构建优化模型,解决与关键绩效指标相关的业务问题。
这类问题在供应链场景中随处可见:
团队主管需要优化临时工的招聘计划,控制人力成本;
计划员希望提高货车的装载率,降低运输成本;
仓库经理需要压缩仓储空间,提升空间利用率。
本质上,我们的目标就是在满足特定约束条件的前提下,最大化或最小化某个目标函数。
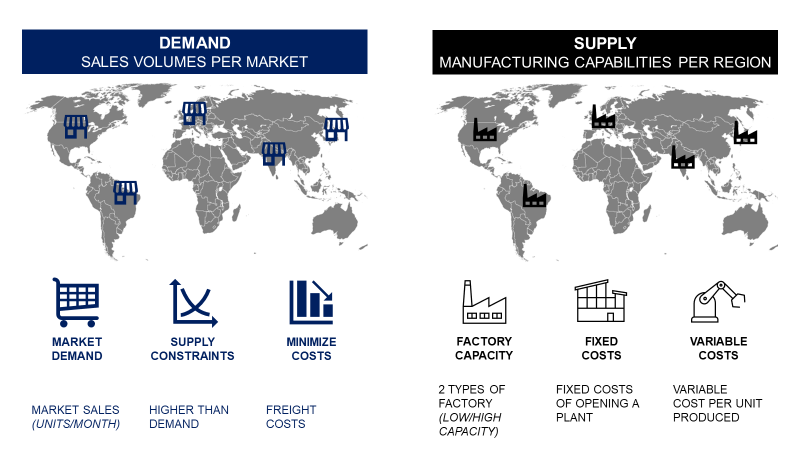
在我的博客中,有数十个运用线性规划和非线性规划优化业务流程的案例。
接下来,我将以供应链网络设计问题为例,带你了解这类研究可能面临的挑战。
[供应链网络设计问题示意图——由萨米尔·萨西制作]((https://file.haoxueai.cn/haoxue/img/d490ab19-f8a7-4e57-951b-10a2f0f67272.png)
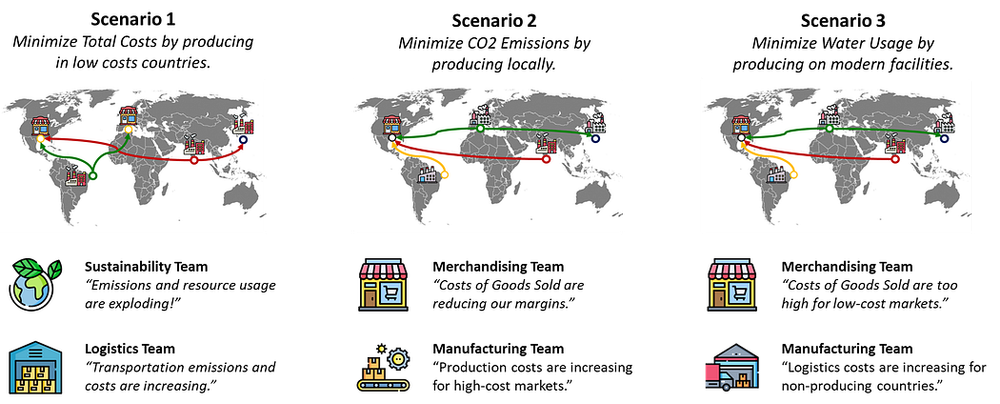
一家跨国企业在全球多个国家设有市场和工厂,他们希望重新设计供应链网络,在降低成本的同时减少环境足迹。

供应链总监希望我们能给出建议:应该在哪些地区新建工厂,才能实现整体生产成本的最小化。
这些工厂的选址,就是我们需要在优化模型中求解的决策变量。我们可以用Python的PuLP库来构建这个模型。
在项目执行过程中,我在数据收集和目标函数设定这两个环节遇到了不少难题。
真正的挑战是什么?
事实上,在绝大多数实际场景中,业务问题的描述往往是模糊且不完整的。
比如,在为一家时尚零售商做项目时,我们花了数周时间才最终确定目标函数。
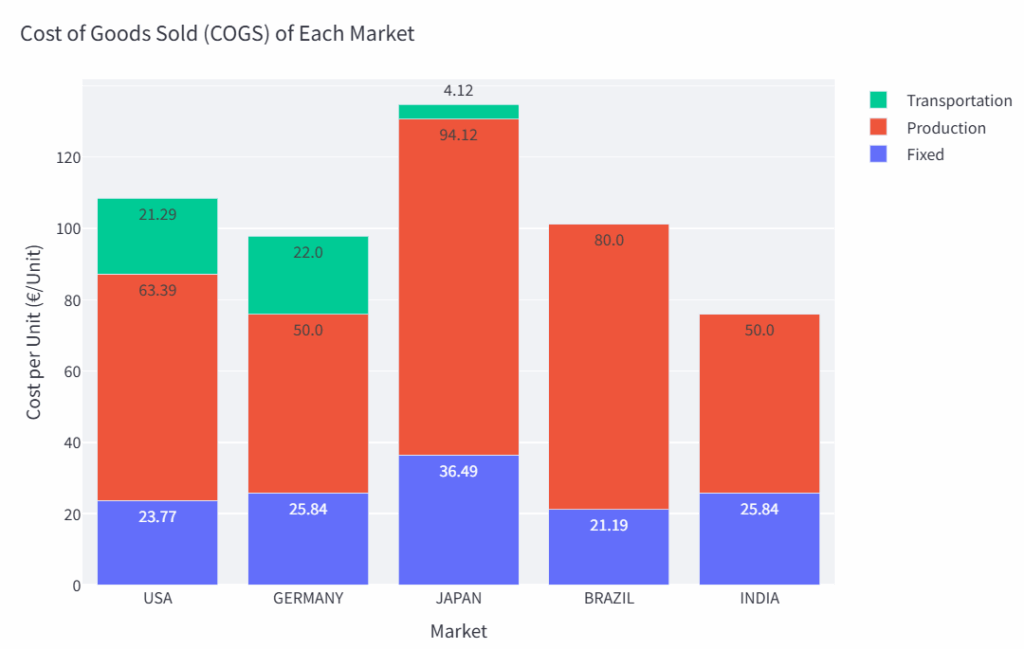
在提交初步分析结果后,我们发现一个关键问题:如果单纯追求“全球整体生产成本最低”,可能会导致部分市场的销货成本(COGS)大幅上升。
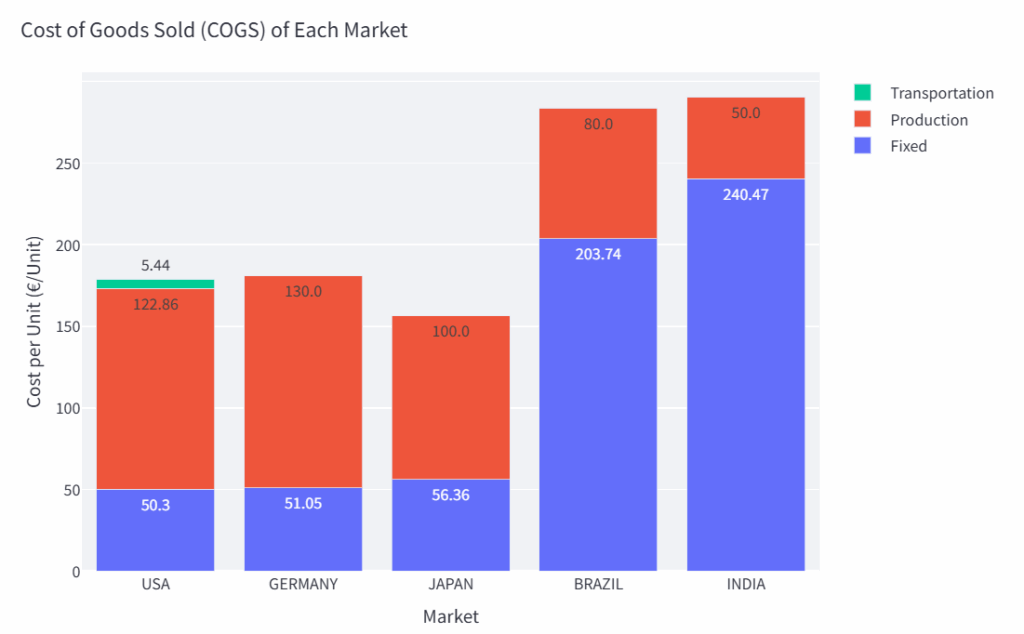
显然,“印度的生产成本高于美国”这类情景是绝对不能出现的。 正是在这个节点,我凭借对模型的理解,协助客户调整了业务假设和运营约束条件。
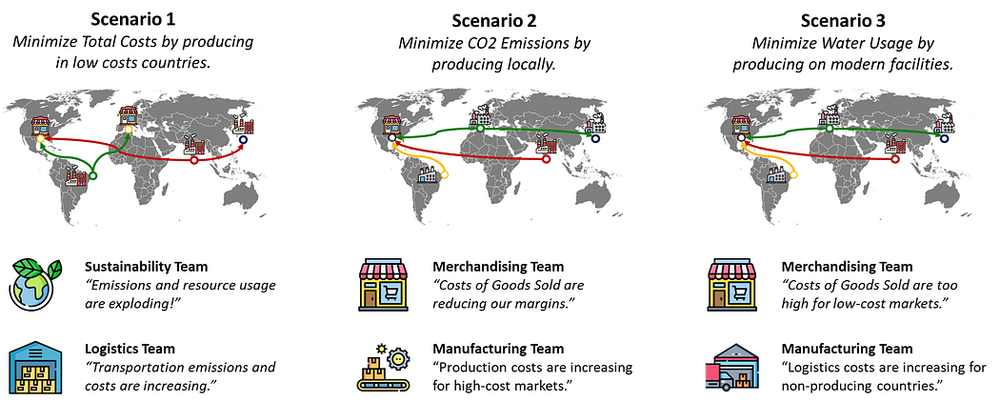
这类战略级项目,能让你的专业能力脱颖而出——因为你直接对接企业决策者,解决的是影响企业盈利能力的核心问题。
我们的核心价值,从来不是写出多少行代码,而是搭建起业务需求与优化手段之间的桥梁。
如果你想了解更多细节,可以观看这段视频:我是如何通过连接Claude Desktop的MCP服务器,借助人工智能解决这个问题的。
你也可以在Towards Data Science的这篇文章中找到完整的案例分析:《用数据科学驱动可持续的商业战略》。
要胜任这类工作,你需要在掌握数据科学技能的基础上,对供应链的实际运营逻辑有基本的理解。
关于这一点,我也准备了相关学习资源。
如何入门供应链数据科学?
我在管理分析师和数据科学家团队时,发现了一个最普遍的问题:很多人对供应链的实际运营流程知之甚少。
这会直接导致业务团队对数据科学家产生信任隔阂。
在业务人员眼中,有些数据科学家就像“从没进过仓库的理论派”,提出的方案脱离实际。
想要在供应链分析领域站稳脚跟,运营知识是必修课。
你不需要成为供应链专家,但必须具备足够的认知——这样才能与业务团队高效沟通、准确界定问题,设计出真正能落地的解决方案。
具体来说,你需要学习这些基础知识:仓库和工厂的运作流程、运输网络的搭建逻辑、库存在供应链中的流转机制。
以下是我的入门建议:
1. 通过5分钟科普视频,学习供应链核心流程
我整理了一个包含40多个短视频的播放列表,浓缩了我十年的行业经验——无论是作为解决方案设计经理,还是物流绩效经理的实战心得,都包含在内。
课程从最基础的仓储和运输运营知识讲起。
这些视频能帮你掌握以下核心内容:
仓储流程:收货(入库)、存储(库存管理)、发货(出库)的全流程操作规范;
运输管理:整车运输(FTL)与零担运输(LTL)的区别、核心绩效指标、成本结构解析。
内容聚焦于运营实操和财务逻辑——这是物流运营的核心关注点,也是我作为供应链解决方案经理的核心专长领域。
掌握这些基础知识后,你就能轻松理解博客中绝大多数物流相关的案例分析。
每篇文章都附带了可直接运行的源代码(托管在GitHub仓库),以及总结案例核心内容的科普视频。
2. 如何活用这些学习资源?
我的建议是:尝试调整案例中的输入数据、参数和业务场景,把解决方案适配到你所在公司的实际问题中。
你可以充分发挥想象力,也可以借助大语言模型(LLM)生成新的业务场景,进行模拟分析。
请记住,学习的目标是同步提升技术能力和运营认知。
3. 推动解决方案产品化,提升落地率
在我的博客中,我们始终致力于打造能真正影响运营的解决方案。
想要让业务团队愿意采纳我们的方案,就必须实现友好的产品化部署。
因此,我专门撰写了多篇教程和文章,分享如何将算法和可视化成果转化为可落地的产品。
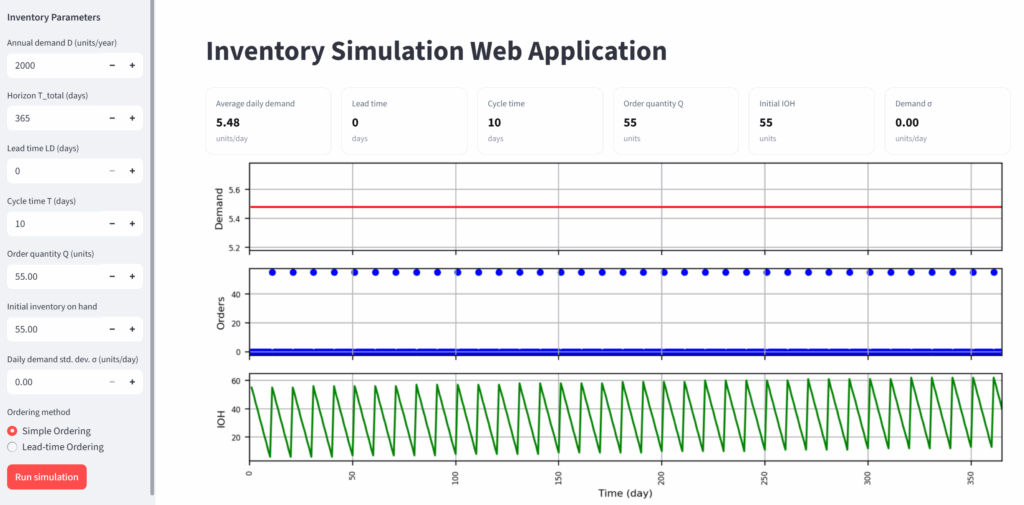
在我最新发布的文章中,详细讲解了如何使用Python的Streamlit库,部署一个库存模拟应用。
这套方法,适用于博客中分享的50多个供应链分析解决方案。
下一步该怎么做?
我希望读完这篇文章后,你能确信:自己已经拥有了成为一名“能创造运营价值”的供应链数据科学家的全部资源。
作为一名刚创办公司、专注于提供供应链分析产品的创业者,我可以负责任地说:市场对这类专业人才的需求非常旺盛。
而且,投身这个领域,你能在解决实际问题的过程中收获满满的乐趣!
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 京公网安备 11010802022788号
京公网安备 11010802022788号







