


 雷达卡
雷达卡






本文反映的是2026年2月Claude技能、MCP和子智能体的发展状态。人工智能领域发展迅速,因此在你阅读本文时,部分细节可能已过时。但本文聚焦的核心概念是具有时效性的。
如果你使用大型语言模型(LLMs)开发已有一段时间,可能会反复经历这样的循环:你花时间精心设计一个能产生出色结果的提示词,几天后又需要相同的行为,于是不得不重新开始编写提示词。重复几次后,你可能会意识到这种方式效率低下,于是决定将提示词模板存储在某个地方,以便日后调用,但即便如此,你仍需找到该提示词、粘贴它,然后针对当前对话进行调整。这过程实在太过繁琐。
这就是我所说的“提示词工程仓鼠轮”——一种从根本上存在缺陷的工作流。
Claude技能(Claude Skills)是Anthropic为解决这一“可复用提示词”问题而提出的方案,且其价值远不止于此。它不仅能让你摆脱重复编写提示词的困扰,还引入了一种全新的上下文管理、令牌经济学以及AI驱动开发工作流的架构思路。
在本文中,我将拆解技能和子智能体的实际内涵、它们与传统MCP的区别,以及技能/ MCP /子智能体组合的发展方向。
一、什么是技能(Skills)?
从本质上讲,技能是可复用的指令集,像Claude这样的AI智能体在对话中遇到相关场景时,会自动访问这些指令集。你只需创建一个包含元数据和指令主体的文件,将其放入指定目录,Claude就能自动处理后续操作(文件路径示例:.claude/skills/skill.md)。
1.1 技能的形式
最简单的技能是一个markdown文件,包含名称、描述和指令主体,格式如下:
---
name: <技能名称>
desc ription: <技能简短描述>
---
<技能详细说明>
1.2 技能的优势
技能的核心优势在于自动调用功能。启动新对话时,智能体仅读取每个技能的名称和描述,以节省令牌。当它判断某个技能与当前任务相关时,才会加载该技能的主体内容。如果技能主体引用了其他文件或文件夹,智能体也会在需要时读取这些内容。本质上,技能是“懒加载”的上下文——智能体不会预先加载完整的指令集,而是逐步向自己披露信息,只获取当前步骤所需的内容。
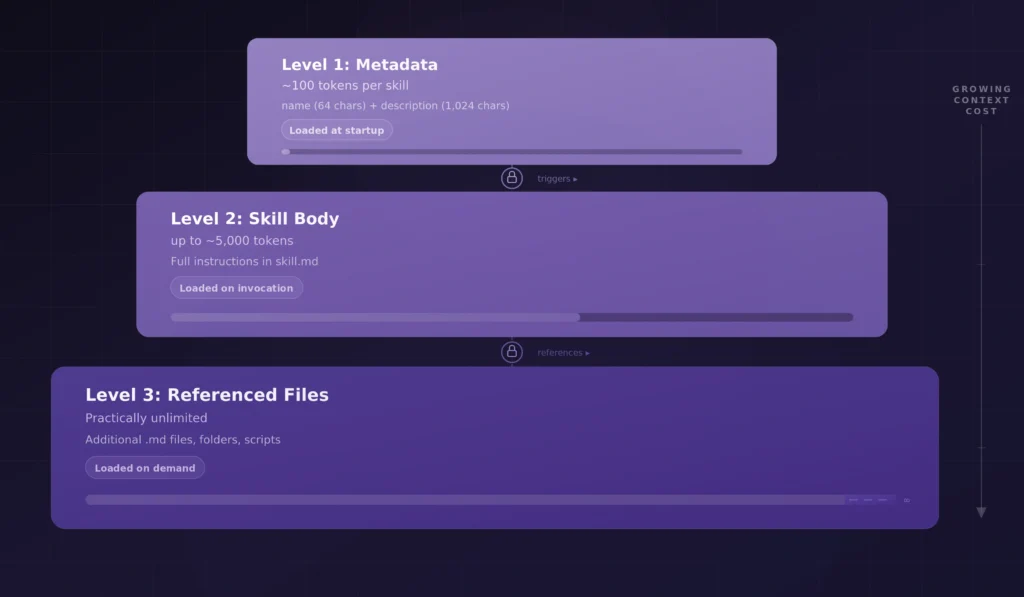
这种逐步披露机制分为三个层级,每个层级都有其自身的上下文预算:
元数据(启动时加载):技能名称(最长64个字符)和描述(最长1024个字符)。每个技能大约消耗100个令牌,即使注册数百个技能,其开销也可以忽略不计。
技能主体(调用时加载):skill.md文件中包含的完整指令集,最长约5000个令牌。只有当智能体判断该技能相关时,这部分内容才会进入上下文窗口。
引用文件(按需加载):技能目录中的其他markdown文件、文件夹或脚本。这部分内容几乎没有限制,智能体仅在指令引用且当前任务需要时才会读取。
核心洞察:技能是可复用、懒加载且自动调用的指令集,通过元数据、主体和引用文件三个层级实现逐步披露。这种机制通过避免将所有内容一次性倒入上下文窗口(点名批评MCP 👀),最大限度地降低了前期令牌成本。
二、令牌经济学中的核心问题
2.1 成本构成
这已经不是什么秘密:智能体的上下文窗口空间并非免费,填充它会产生累积成本。上下文窗口中的每个令牌,都会从三个方面产生成本:
直接成本:最明显的是按令牌付费,既可以是直接通过API使用付费,也可以是间接通过使用限额产生的成本。
延迟成本:你还会付出时间成本,因为输入令牌越多,响应速度越慢。这一点随着上下文窗口长度的增加,扩展性会变得越来越差(与注意力机制相关)。
质量成本:最后,长上下文窗口会导致模型性能下降。有明确证据表明,当LLM的上下文被无关信息充斥时,其表现会变差。
2.2 MCP的高昂开销
我们通过一个简单的估算来直观感受这一点。我在编程时常用的MCP选择如下:
AWS(用于基础设施部署):三个服务器(aws-mcp、aws-official、aws-docs)合计成本约8500个令牌(13个工具)。
Context7(用于文档查阅):元数据约750个令牌(2个工具)。
Figma(用于将设计落地到前端开发):元数据约500个令牌(2个工具)。
GitHub(用于搜索其他仓库的代码):元数据约2000个令牌(26个工具)。
Linear(用于项目管理):元数据约3250个令牌(33个工具)。
Serena(用于代码搜索):元数据约4500个令牌(26个工具)。
Sentry(用于错误跟踪):元数据约12500个令牌(22个工具)。
以上工具元数据总计约32000个令牌,会加载到每一条消息中——无论你是否在使用这些工具。
我们来算一笔经济账:Claude Opus 4.6的收费标准是每百万输入令牌5美元。这32000个闲置的MCP元数据,会为你发送的每一条消息增加0.16美元的成本。这听起来不多,但你要知道,即使是一个简单的5条消息对话,纯开销就已达到0.8美元。而大多数开发者发送的消息远不止5条;再加上一些简短的澄清和上下文收集问题,很快就会达到数十条甚至上百条。假设你平均每天发送50条消息,每月工作20天,那么每天的纯开销就是8美元,每月约160美元*——这仅仅是为了让工具描述停留在上下文窗口中。更不用说这还没计算延迟和质量影响。
*补充说明:大多数模型对缓存的输入令牌收取的费用会大幅降低(折扣90%)。但需要注意的是,有些模型在启用缓存时会额外收费,而且默认情况下(API)缓存并不总是开启(咳咳,说的就是Claude)。
2.3 技能的成本效益优势
技能的加载模式从根本上改变了这三个成本构成。一开始,智能体仅看到每个技能的名称和简短描述,每个技能大约消耗100个令牌。这样一来,即使我注册300个技能,消耗的令牌也比我的MCP设置少。完整的指令主体(约5000个令牌)仅在智能体判断其相关时才会加载,而引用文件则仅在当前步骤需要时才会加载。
在实际应用中,一次典型的对话可能只会调用1-2个技能,其余技能则不会进入上下文窗口。这就是关键区别:MCP的成本随注册工具的数量(跨所有服务器)增长,而技能的成本则更贴近实际使用情况。
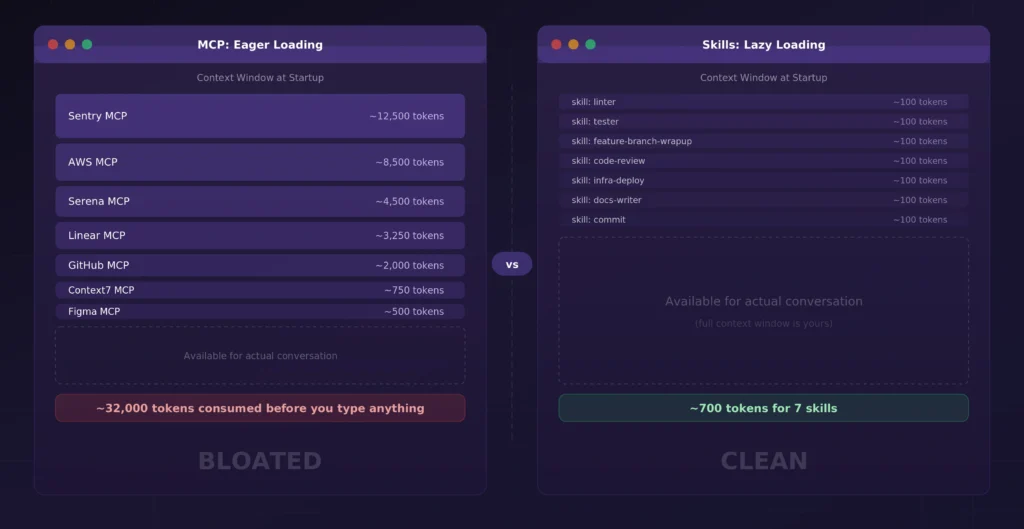
核心洞察:MCP是“饥饿式”的,会预先加载所有工具元数据,无论是否使用;技能是“懒加载”的,会逐步且仅在相关时加载上下文。这种差异对成本、延迟和输出质量都有着重要影响。
三、注意:这种说法有误导性?技能和MCP完全是两回事!
如果上面的内容让你觉得“技能是更新、更好的MCP”,那我需要纠正这个认知。我之前的意图是聚焦于它们的加载模式及其对令牌消耗的影响;从功能上来说,它们其实有很大不同。
MCP(模型上下文协议,Model Context Protocol)是一种开放标准,让任何LLM都能与外部应用程序交互。在MCP出现之前,将模型与工具连接需要自定义集成。而MCP将这种复杂度简化为:每个模型只需实现一次协议,每个工具只需暴露一次协议,就能实现所有模型与工具的互操作。这是一个简单的基础设施层面的改进,但确实非常强大(难怪它迅速风靡全球)。
另一方面,技能在某种程度上可以说是“高级提示词”——我这么说完全是褒义。它们为智能体提供处理任务的专业知识和指导:如何处理任务、遵循哪些规范、何时使用哪种工具、如何结构化输出。它们就是可复用的指令集,在相关时按需获取,仅此而已。
核心洞察:MCP赋予智能体“能力”(即“能做什么”),技能赋予智能体“专业知识”(即“怎么做”),因此它们是互补的。
我们通过一个例子来具体说明。假设你将GitHub的MCP服务器连接到你的智能体,MCP会赋予智能体创建拉取请求(PR)、列出问题、搜索仓库的能力。但它不会告诉智能体,例如,你的团队如何结构化PR、是否需要包含测试部分、如何按变更类型标记、是否需要在标题中引用Linear工单——这些都是技能的作用。MCP提供工具,技能提供操作手册。
因此,之前我提到技能比MCP加载上下文更高效,真正的结论不是“用技能替代MCP”,而是“懒加载作为一种模式是有效的”。由此引出一个值得思考的问题:为什么MCP工具访问不能也采用懒加载?这就是子智能体的用武之地。
四、子智能体:兼具两者优势
子智能体是具有独立上下文窗口和已连接工具的专用子智能体。有两个特性让它们极具价值:
独立上下文:子智能体启动时拥有干净的上下文窗口,预先加载自身的系统提示词和仅分配给它的工具。它读取、处理和生成的所有内容都保存在自己的上下文中,主智能体仅能看到最终结果。
独立工具:每个子智能体可以配备自己的MCP服务器和技能集。主智能体无需了解(也无需为其付费)它从未直接使用过的工具。
子智能体完成任务后,其整个上下文会被丢弃。工具元数据、中间推理过程、API响应——所有内容都会消失,只有结果会反馈给主智能体。这实际上是一件好事:我们不仅避免了主智能体的上下文被不必要的工具元数据膨胀,还防止了不必要的推理令牌污染上下文。举个例子,假设一个子智能体负责研究某个库的API,它可能会搜索多个文档来源、阅读数十页内容、尝试多个查询,最终才找到正确答案。你仍然需要为子智能体自身的令牌使用付费,但所有中间工作(走的弯路、无关页面、搜索查询)都会在子智能体完成任务后被丢弃。核心优势在于,这些内容都不会累积到主智能体的上下文中,因此对话中后续的每一条消息都能保持简洁且成本低廉。
这意味着你可以设计这样的架构:MCP服务器仅通过特定的子智能体访问,完全不加载到主智能体上。不再需要在每一条消息中携带约32000个令牌的工具元数据,主智能体的令牌开销几乎为零。当它需要创建PR时,只需启动一个GitHub子智能体,由子智能体完成PR创建并返回链接即可。与技能是懒加载上下文类似,子智能体是懒加载的“工作者”:主智能体知道自己可以调用哪些专家,只有在任务需要时才会启动对应的子智能体。
4.1 实际示例
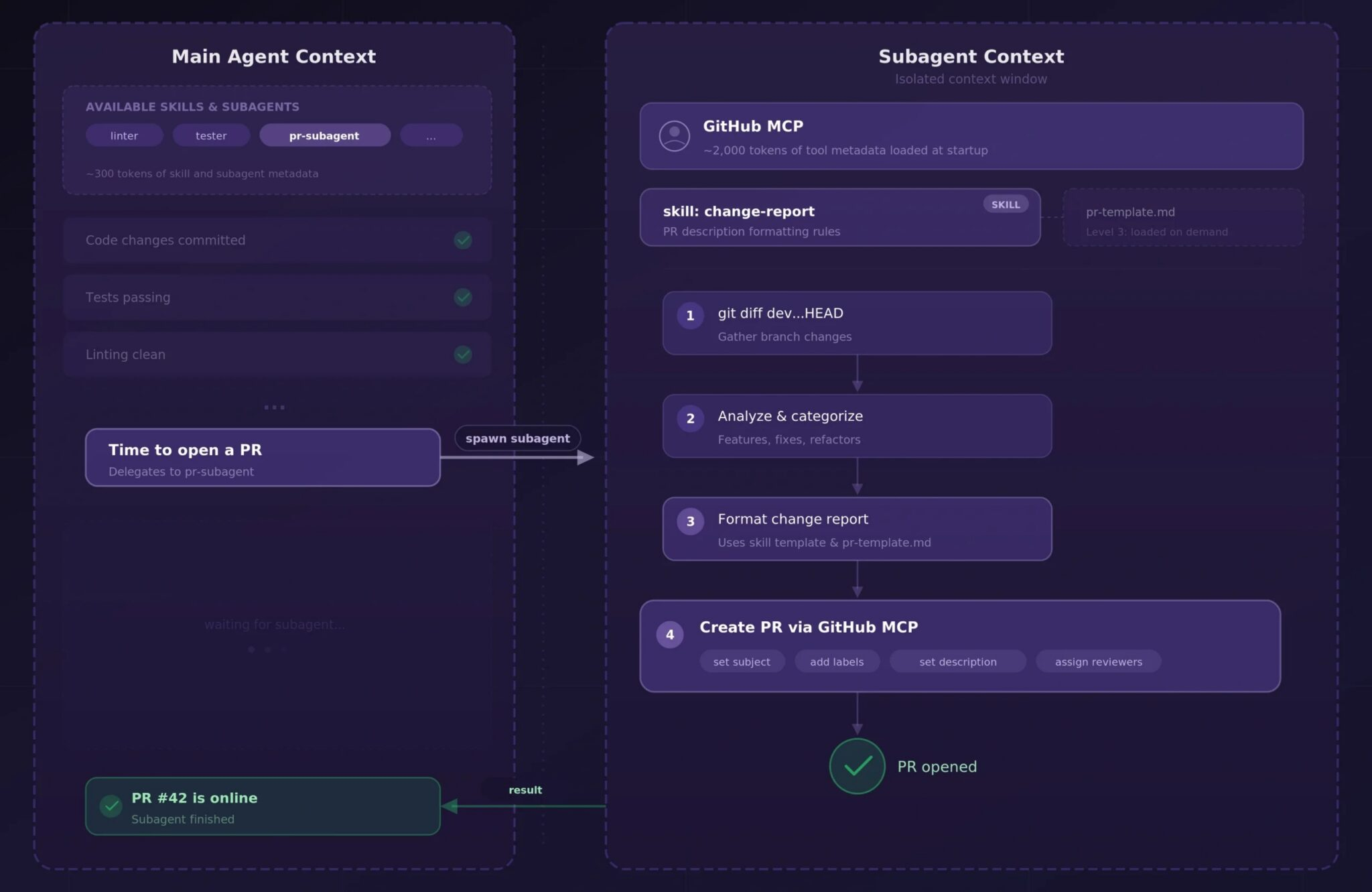
我们来让这个概念更具体。我每天都会使用一个“功能分支收尾”工作流,它能自动化我开发周期中一个非常繁琐的环节:创建PR。以下是技能、MCP和子智能体如何协同工作的。
当主智能体和我完成编码工作后,我会要求它收尾功能分支。主智能体不会自己处理这件事,而是将整个PR流程委托给一个专用的子智能体。这个子智能体配备了GitHub MCP服务器和一个定义了我们团队PR结构的“变更报告”技能(change-report skill.md),其内容大致如下:
---
name: change-report
desc ription: 生成PR变更报告时使用。
定义团队的PR结构、分类规则和格式规范。
---
1. 确保没有未提交的暂存更改,否则向主智能体反馈
2. 运行 `git diff dev...HEAD --stat` 和 `git log dev..HEAD --oneline`
收集该功能分支上的所有变更
3. 分析差异,并按类型(新功能、重构、bug修复或配置变更)
对最关键的变更进行分类
4. 按照 `pr-template.md` 中的模板生成结构化变更报告
5. 通过GitHub MCP创建PR,将标题和正文填充为生成的报告内容
6. 返回PR链接
同一目录下的pr-template.md文件定义了我们团队的PR结构:包含摘要、变更明细和测试说明等部分。这就是逐步披露的第三层级:子智能体仅在步骤4要求时才会读取该文件。
这个架构之所以能生效,核心在于:技能提供了团队如何报告变更的专业知识,GitHub MCP提供了实际创建PR的能力,子智能体提供了执行所有这些工作的上下文边界。而主智能体只需调用子智能体,等待其完成,然后接收确认信息或错误反馈即可。
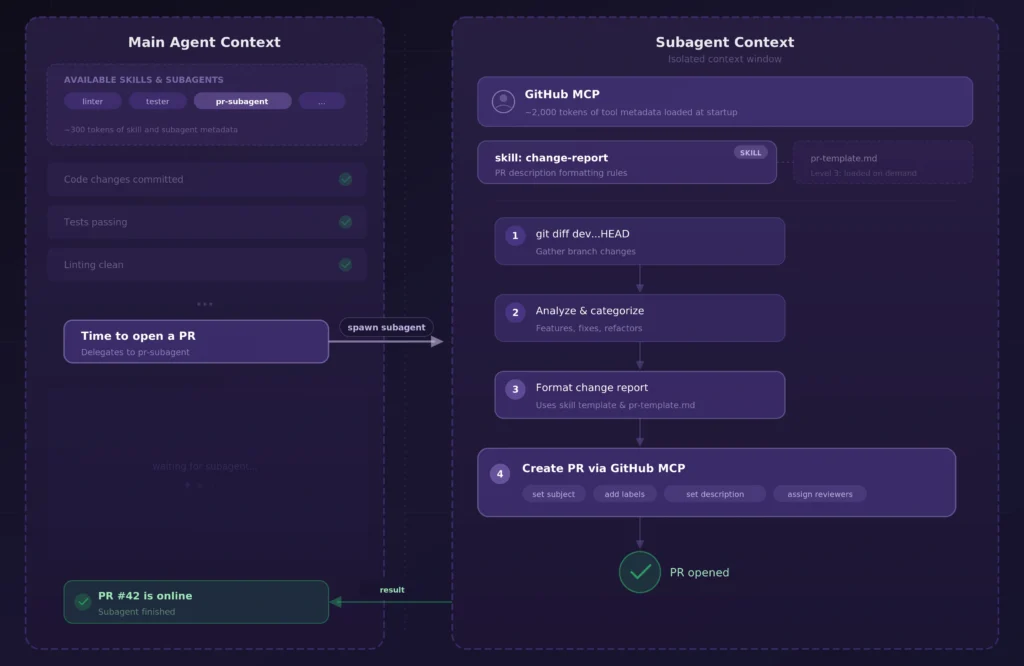
核心洞察:技能、MCP和子智能体协同工作、相得益彰。技能提供专业知识和指令,MCP提供能力,子智能体提供上下文边界(保持主智能体上下文干净)。
五、更宏观的视角
在LLM发展的早期,竞争焦点是打造更好的模型:更少的幻觉、更敏锐的推理、更具创造性的输出。这场竞争并未完全停止,但重心显然已经转移。MCP和Claude Code确实具有革命性意义,而将Claude Sonnet从3.5版本升级到3.7版本,说实话并没有带来质的飞跃。如今我们获得的模型增量改进,远不如我们围绕模型构建的基础设施重要。技能、子智能体和多智能体编排,都是这一转变的体现:从“如何让模型更聪明”转向“如何从现有模型中获取最大价值”。
核心洞察:AI开发的价值重心已从“更好的模型”转向“更好的基础设施”。技能、子智能体和多智能体编排,不仅仅是对开发者体验的改进;它们更是让智能体AI在经济上和运营上实现规模化可行的核心架构。
5.1 当前发展现状
技能通过将你最优质的提示词转化为可复用、自动调用的指令集,解决了提示词工程的无尽循环问题。子智能体通过将工具访问和中间推理隔离到专用工作者中,解决了上下文膨胀问题。两者结合,让你能够一次性将专业知识编码,然后在未来的每一次交互中自动应用。这正是遵循最佳实践的工程团队已经在做的事情——通过文档、风格指南和操作手册沉淀知识,而技能和子智能体只是让这些成果变得机器可读。
子智能体模式还解锁了多智能体并行能力。不再是单个智能体按顺序处理任务,你可以同时启动多个子智能体,让它们独立工作,然后收集结果。Anthropic自己的多智能体研究系统已经实现了这一点:Claude Opus 4.6负责编排,而Claude Sonnet 4.6子智能体并行执行任务。这自然会导向异构模型路由:由昂贵的前沿模型负责编排和规划,而更小、更便宜的模型负责执行。编排者负责推理,工作者负责执行。这种模式可以在保持输出质量的同时,大幅降低成本。
这里有一个重要的注意事项:并行模式在读取任务中表现良好,但在涉及共享状态的写入任务中会变得困难。例如,你同时启动一个后端子智能体和一个前端子智能体,后端智能体重构了一个API端点,而前端智能体基于重构前的快照生成了调用旧端点的代码。两个智能体单独来看都没有问题,但结合在一起就会产生不一致的结果。这是一个典型的并发问题,来自近未来的AI工作流,目前仍是一个未解决的问题。
5.2 未来发展方向
我预计技能组合将变得更加复杂。如今,技能相对扁平化:一个带有可选引用的markdown文件。但该架构天然支持分层技能——即引用其他技能的技能,形成类似专业知识继承体系的结构。比如,一个基础的“代码审查”技能,可扩展出特定语言的变体,进而再扩展出特定团队的规范变体。
如今大多数多智能体系统都是严格的层级结构:主智能体委托任务给子智能体,子智能体完成后,控制权返回给主智能体。目前,子智能体之间的对等协作还很少。Anthropic最近为Opus 4.6推出的“智能体团队”功能,是朝着这个方向迈出的早期一步,它允许多个智能体直接协作,而无需所有操作都通过编排者路由。在协议层面,谷歌的A2A(智能体到智能体协议,Agent-to-Agent Protocol)可能会将这种模式标准化,跨供应商推广——MCP负责智能体与工具的通信,A2A负责智能体与智能体的通信。尽管如此,与MCP的爆发式增长相比,A2A的采用速度一直很慢。这是一个值得关注的方向,但目前还不适合作为重点投入。
5.3 智能体将成为新的“函数”
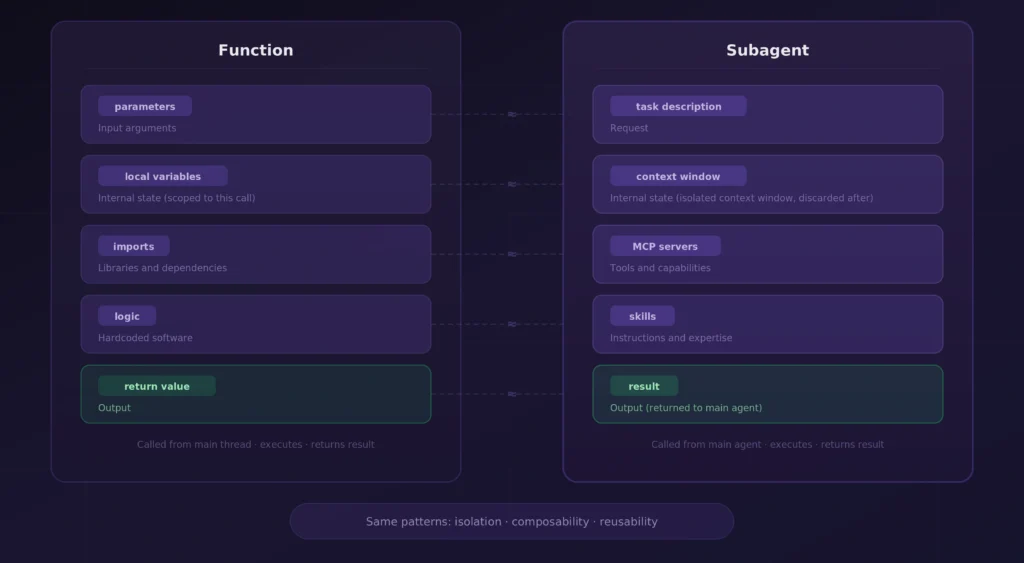
这里正在出现一种更广泛的抽象,值得我们退后一步去审视。安德里亚·卡帕西(Andrej Karpathy)那条著名的推文——“最热门的新编程语言是英语”,准确捕捉了我们与LLM交互的本质。但技能和子智能体将这种抽象又提升了一个层次:智能体正在成为新的“函数”。
一个子智能体就是一个独立的工作单元:它接收输入(任务描述)、拥有自己的内部状态(上下文窗口)、使用特定工具(MCP服务器)、遵循特定指令(技能),并返回输出。它可以从多个地方被调用,具有可复用性和可组合性——这正是函数的特性。主智能体则成为执行线程:负责编排、分支、委托,并汇总来自专用工作者的结果。
除了这种类比,它还能带来与函数对软件工程相同的实际价值。隔离性限制了智能体失败时的影响范围,不会导致整个系统崩溃,并且可以通过try-except机制捕获失败。专业性意味着每个智能体都可以针对其特定任务进行优化。可组合性意味着你可以从简单、可测试的组件中构建越来越复杂的工作流。可观测性也会自然随之而来:由于每个智能体都是具有明确输入和输出的独立单元,追踪“系统为什么会做X”就变成了检查调用栈,而不是盯着一个20万令牌的上下文 dump。
六、结论
从表面上看,技能似乎只是简单的“可复用提示词”,但实际上,它是对AI工具中一些最棘手问题的深思熟虑的解决方案:上下文管理、令牌效率,以及原始能力与领域专业知识之间的差距。
如果你还没有尝试过技能,不妨从小处着手。挑选你最常重复的提示词模式,将其提取到一个skill.md文件中,看看它如何改变你的工作流。一旦你感受到它的价值,就可以迈出下一步:找出哪些MCP工具不需要部署在主智能体上,或者哪些子流程需要大量推理(而这些推理在找到答案后就不再需要),并将它们分配给专用的子智能体。你会惊讶地发现,当每个智能体只携带它实际需要的内容时,你的架构会变得多么简洁。
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 京公网安备 11010802022788号
京公网安备 11010802022788号







