


 雷达卡
雷达卡






一、引言:过参数化、泛化能力与SAM
现代深度学习(尤其是在计算机视觉和自然语言处理领域)的显著成功,建立在“过参数化”模型的基础上:这类模型拥有足够多的参数,能够完美记忆训练数据。从功能上看,若一个模型在特定任务中能轻松实现接近100%的训练准确率和接近零的训练损失,就可判定为过参数化模型。
然而,这类模型的实用性取决于其在“留出测试集”上的表现——测试集与训练集服从相同分布,但在训练过程中未被模型见过。这种“在新样本上保持性能的能力”被称为“泛化能力”,它是任何深度学习模型具备实际应用价值的核心前提。
经典机器学习理论告诉我们,过参数化模型会发生灾难性过拟合,因此泛化能力较差。但过去十年中最令人惊讶的发现之一是:这类模型往往具有出色的泛化表现。
这一高度反直觉的现象已在一系列论文中得到研究,最早可追溯到Belkin等人(2018年)和Nakkiran等人(2019年)的开创性工作。这些研究表明,泛化能力存在一条“双下降”曲线:随着模型规模增大,泛化能力首先会如经典理论预测的那样变差,随后在超过某个临界阈值后再次提升——前提是模型采用合适的优化方法进行训练。
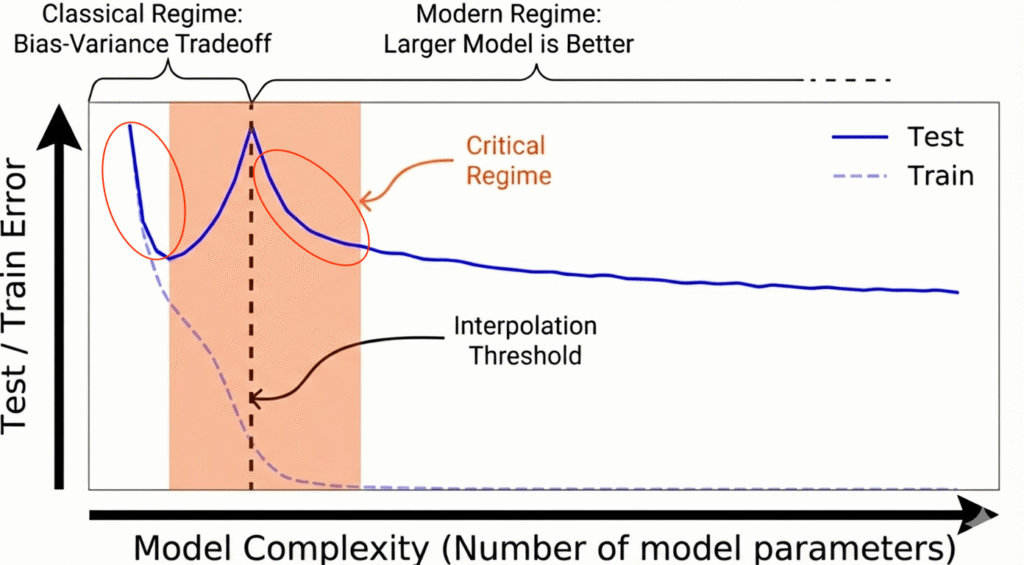
图1展示了双下降曲线的示意图。纵轴表示测试误差(衡量泛化能力的指标,误差越低表示泛化能力越好),横轴表示模型参数数量。正如预期的那样,随着模型规模增大,训练误差(蓝色虚线)迅速趋近于零。
测试误差(蓝色实线)则表现出更有趣的行为:它最初随模型规模增大而下降——即第一个下降阶段(左红色圆圈标注),随后在垂直虚线标记的“插值阈值”处上升至峰值,此时模型的泛化能力最差。然而,超过该阈值后,在过参数化区域,测试误差再次下降——即第二个下降阶段(右红色圆圈标注),并随着参数数量的增加持续降低。这正是现代深度学习模型所关注的区域。
在机器学习中,我们通过最小化训练数据集上的损失函数来寻找模型参数。但对于过参数化模型类别而言,仅仅最小化我们常用的损失函数(如交叉熵),就能保证其具有令人满意的泛化性能吗?答案——通常来说——是否定的!无论你是对预训练模型进行微调,还是从零开始训练模型,优化训练算法以确保模型具备足够的泛化能力都至关重要。这也使得优化器的选择成为一项关键的设计决策。
锐度感知最小化(Sharpness-Aware-Minimization, SAM)由Foret等人在2019年的论文中提出,是一种专为提升过参数化模型泛化能力设计的优化器。本文将对SAM进行通俗化综述,包括以下内容:
直观理解SAM的工作原理及其提升泛化能力的原因;
深入解析算法,说明涉及的关键数学步骤;
SAM优化器类在训练循环中的PyTorch实现,包括针对含BatchNorm层模型的重要注意事项;
通过ResNet-18模型在图像分类任务上的实验,快速证明该优化器在提升泛化能力方面的有效性。
二、锐度(Sharpness)的概念
首先,我们尝试直观理解:为什么仅仅最小化损失函数,对于实现最优泛化能力来说可能不够。
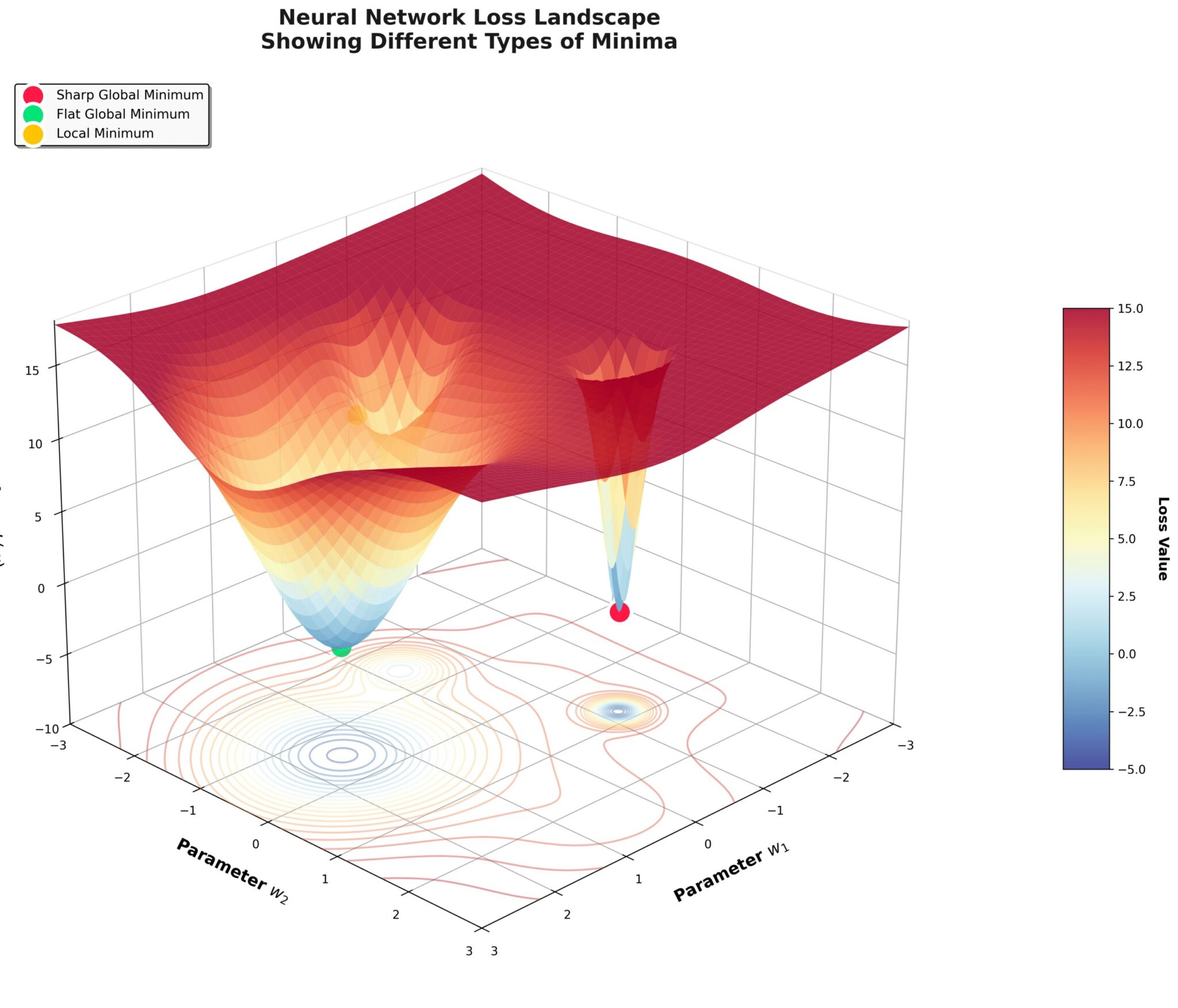
一个有用的类比是“损失曲面”。对于大型过参数化模型,其损失曲面存在多个局部最小值和全局最小值。这些最小值周围的局部几何结构在整个曲面上可能存在显著差异。例如,两个最小值的损失值可能几乎相同,但局部几何结构却截然不同:一个可能是“锐度最小值”(狭窄的山谷),而另一个可能是“平坦最小值”(宽阔的山谷)。
用于比较这些局部几何结构的一种正式指标是“锐度”。在损失函数为L(w)的损失曲面上,任意一点w的锐度S(w)定义为:
我们来拆解这个定义。假设你处于损失曲面上的点w,对参数进行扰动,使得新参数始终位于以w为中心、半径为ρ的球内。那么,锐度就定义为在这一系列扰动中,损失函数的最大变化量。在文献中,它也被称为“最坏方向锐度”,原因显而易见。
我们很容易理解:对于锐度最小值(陡峭、狭窄的山谷),参数在某些方向上的微小扰动就会导致损失函数发生显著变化,从而产生较高的锐度值;而对于平坦最小值(宽阔的山谷),参数的微小扰动只会导致损失函数发生相对缓慢的变化,因此锐度值较低。因此,锐度是衡量损失曲面上某个最小值“平坦程度”的指标。
最小值的局部几何结构(尤其是锐度指标)与所得模型的泛化能力之间存在深刻关联。过去十年中,大量理论和实证研究致力于阐明这种关联。例如,Keskar等人(2016年)的论文指出,损失值相近的全局最小值,其泛化能力可能因锐度指标的不同而存在显著差异。
这些研究得出的基本结论是:更平坦(锐度更低)的最小值与模型更好的泛化能力呈正相关。具体而言,模型要实现良好的泛化,就必须避免在训练过程中陷入锐度最小值。因此,要训练出泛化能力良好的模型,优化过程不仅需要最小化损失函数,还需要尽可能最大化最小值的平坦程度(或等效地最小化锐度)。
这正是SAM优化器旨在解决的问题,接下来我们将详细介绍SAM。
补充说明:上述类比也从概念上解释了过参数化模型为何能够潜在避免过拟合问题。这是因为大型模型拥有丰富的损失曲面,提供了多个具有出色泛化能力的平坦全局最小值。
三、锐度感知最小化(SAM)算法
我们先回顾一下模型的标准优化过程:它需要找到能够最小化迷你批次B上损失函数的模型参数。在每个时间步,计算损失函数相对于参数的梯度,并根据以下规则更新参数:
与SGD(随机梯度下降)或Adam不同,SAM并不直接最小化损失函数L。相反,在损失曲面上的某个给定点,它首先扫描半径为ρ的邻域,找到能最大化损失函数的扰动;第二步,再最小化这个最大损失函数。这种方式能让优化器找到位于“损失值均匀较低”邻域内的参数,从而降低锐度值,获得更平坦的最小值。
我们更详细地讨论这一过程。SAM优化器的损失函数为:
其中ρ表示扰动大小的上界。能最大化损失函数L的扰动(通常称为“对抗性扰动”,因为它最大化了常规损失)可通过以下推导得出:
其中第二个等式是通过对扰动函数进行一阶泰勒展开得到的近似,最后一个等式则源于前一步中括号内第一项与ε无关。对最后一个等式求解对抗性扰动,可得:
将其代入SAM损失函数的表达式,可计算出SAM损失相对于ε的一阶导数梯度:
这是优化过程中最关键的等式。在ε的一阶导数近似下,SAM损失函数的梯度可通过在对抗性扰动点处计算常规损失函数的梯度来近似。利用上述梯度公式,即可执行标准的优化器步骤:
这就完成了一次完整的SAM迭代。接下来,我们将该算法从理论转化为PyTorch代码。
四、训练循环中的PyTorch实现
代码块sam_training_loop.py给出了含SAM优化器的训练循环示例。为具体说明,我们选择了一个通用的图像分类问题,但该结构广泛适用于各类计算机视觉和自然语言处理任务。SAM优化器类如代码块sam_optimizer_class.py所示。
需要注意的是,定义SAM优化器需要指定两个参数:
基础优化器(如SGD或Adam),因为SAM最终需要执行一步标准的优化器更新;
超参数ρ,用于限制可接受扰动的大小上限。
优化器的一次迭代包含两次前向传播和两次反向传播。我们来梳理sam_training_loop.py代码中的关键步骤:
第5行:计算当前迷你批次B的损失函数L(w, B)——第一次前向传播;
第6行:计算损失函数L(w, B)的梯度——第一次反向传播;
第7行:调用SAM优化器类中的sam_optimizer.first_step函数(见下文),根据上述公式计算对抗性扰动,并按之前的讨论扰动模型权重;
第10行:计算扰动后模型的损失函数——第二次前向传播;
第11行:计算扰动后模型损失函数的梯度——第二次反向传播;
第12行:调用优化器类中的sam_optimizer.second_step函数(见下文),将权重恢复为w_t,然后使用基础优化器,利用在扰动点计算的梯度更新权重w_t。
4.1 注意事项:含BatchNorm层的SAM使用
如果模型包含批量归一化(BatchNorm)层,在训练循环中部署SAM时需要特别注意一点。训练过程中,BatchNorm使用当前批次的统计信息进行归一化,并在每次前向传播时更新运行统计信息;评估过程中,则使用已保存的运行统计信息。
如前所述,SAM每次迭代包含两次前向传播。第一次前向传播时,BatchNorm按标准方式工作;但第二次前向传播时,我们使用扰动后的权重计算损失,而代码块sam_training_loop.py中的朴素训练函数会允许BatchNorm层在第二次前向传播时也更新运行统计信息——这是不可取的。因为运行统计信息应仅反映原始模型的行为,而非作为梯度计算中间步骤的扰动模型。因此,必须在第二次前向传播时显式禁用运行统计信息的更新,并在下一次迭代前重新启用。
为此,我们将在训练循环中使用两个显式函数disable_bn_stats和enable_bn_stats——代码块running_stat.py给出了这类函数的简单示例,它们用于切换PyTorch中BatchNorm函数的track_running_stats参数(第4行和第9行)。修改后的训练循环见代码块mod_train.py。
五、实验演示:基于ResNet-18的图像分类
最后,我们通过一个具体示例演示SAM优化如何提升模型的泛化能力。我们将使用Fashion-MNIST数据集(MIT许可证)进行图像分类任务:该数据集包含60,000张训练图像和10,000张测试图像,分为10个不同的互斥类别,每张图像为28×28像素的灰度图。
分类器模型我们选择未经过预训练的PreAct ResNet-18。虽然ResNet-18的具体架构与本文目的关联不大,但我们简要说明:该模型由一系列构建块组成,每个构建块包含卷积层、BatchNorm层、ReLU激活函数和跳跃连接。PreAct(预激活)表示每个构建块中的激活函数(ReLU)位于卷积层之前;而标准ResNet-18则相反。关于架构的更多细节,建议读者参考He等人(2015年)的论文。
但需要注意的是,该模型约有1120万个参数,因此从经典机器学习的角度来看,它是一个过参数化模型,参数与样本的比例约为186:1。此外,由于模型包含BatchNorm层,使用SAM时需注意在第二次前向传播时禁用运行统计信息的更新。
我们准备进行以下实验:首先使用标准SGD优化器在Fashion-MNIST数据集上训练模型,然后使用以SGD为基础优化器的SAM优化器训练同一模型。我们采用简单的实验设置:固定学习率lr=0.05,动量和权重衰减均设为0。SAM中的超参数ρ设为0.05。所有实验均在单张A100 GPU上执行。
由于SAM的每次权重更新需要两次反向传播步骤——一次用于计算扰动,另一次用于计算最终梯度——为了公平比较,每个非SAM训练轮次的epoch数必须是SAM训练轮次的两倍。因此,我们需要将SAM训练1个epoch的指标与非SAM训练2个epoch的指标进行比较。我们将这种比较单位称为“标准化epoch”,在标准化epoch记录的指标标记为metric_st。实验限制为150个标准化epoch,即SAM训练150个epoch,非SAM训练300个epoch。我们还将SAM优化的模型额外训练50个epoch,以观察模型在长期训练中的表现。
为了验证哪种优化器的泛化能力更好,我们将在每个标准化训练epoch后比较以下两个指标:
测试准确率:模型在测试数据集上的性能;
泛化差距:训练准确率与测试准确率的差值。
测试准确率是衡量模型在经过一定训练epoch后泛化能力的绝对指标;而泛化差距则是诊断模型在特定训练阶段过拟合程度的指标。
我们首先比较图3所示的training_loss_st(标准化训练损失)和training_accuracy_st(标准化训练准确率)曲线。正如过参数化模型的预期,SGD优化的模型在150个epoch内达到接近零的损失和接近99%的训练准确率。显然,SAM的训练速度比SGD慢,需要更多的标准化epoch才能达到接近完美的训练准确率——这一点从SAM优化的模型在150个规定epoch后,训练损失和训练准确率仍在持续提升就可以看出。
5.1 测试准确率
SGD优化的模型在约50个epoch时达到92%的测试准确率,并在接下来的100个epoch中保持稳定。SAM优化的模型在训练初期(约前80个epoch)泛化能力较差——从该阶段测试准确率低于SGD曲线即可看出。然而,在约80个epoch时,它追上了SGD曲线,并最终以微弱优势超过SGD。
在本次具体实验中,150个epoch结束时,SAM的测试准确率为test_SAM = 92.5%,而SGD的测试准确率为test_SGD = 92.0%。值得注意的是,此时SAM训练的模型在训练准确率和训练损失上仍远低于SGD训练的模型。如果将SAM模型再训练50个epoch,测试准确率会略微提升至92.7%。
5.2 泛化差距
SGD模型的泛化差距随训练持续增大,150个epoch后达到gap_SGD = 6.8%;而SAM模型的泛化差距增长速度慢得多,150个epoch后仅为gap_SAM = 2.3%。再额外训练50个epoch后,SAM的泛化差距上升至约3%,但仍远低于SGD的数值。
虽然在Fashion-MNIST数据集上,两种优化器的测试准确率差异较小,但泛化差距存在显著差异,这表明使用SAM优化能带来更好的泛化能力。
六、结论
本文对SAM优化器进行了通俗化综述,它能显著提升过参数化深度学习模型的泛化能力。我们讨论了SAM的设计动机和直观原理,逐步拆解了算法流程,并通过一个简单示例证明了其相较于标准SGD优化器的有效性。
SAM还有几个有趣的方面本文未能涵盖,这里简要提及两点。首先,作为一种实用工具,SAM在小数据集上微调预训练模型时特别有用——Foret等人(2019年)在CNN类架构中对此进行了详细探索,后续许多研究也将其扩展到了更通用的架构中。其次,由于我们开篇讨论了损失曲面中平坦最小值与泛化能力的关联,自然会提出一个问题:经SAM训练、泛化能力显著提升的模型,是否确实收敛到了更平坦的最小值?这是一个非平凡的问题,需要仔细分析训练后模型的海森矩阵谱,并与SGD训练的模型进行比较——但这就是另一个故事了!
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !



 京公网安备 11010802022788号
京公网安备 11010802022788号







