


 雷达卡
雷达卡






开篇:一个悖论
Agent 赛道,此刻两个互相矛盾的观点正在同时成立。
判断一:Agent 不是一个赛道。 今年 3 月,Melly 在一篇微信文章里聊到:Agent 产品只是时间差套利。所有寄生在 LLM 之上的 Agent,做的都是同一件事:趁模型还不够强,用外部编排弥补缺口。但大模型的演进方向是向上吞噬一切。于是缺口会被填平,套利窗口终将关闭。
判断二:Harness 是效果的决定性变量。 也是今年 3 月,OpenAI 公开了一组数据:3 个工程师,5 个月,100 万行生产级代码,零行手写。用的是同一个模型,差异全部来自围绕模型搭建的那套工程系统,即 Agentic Harness。研究者 Nate B Jones 的独立 benchmark 佐证了这一点:同一模型,配备 harness 得分 78%,不配备只有 42%。
那问题来了:如果 Agent 没有护城河,Harness 为什么这么重要?如果 Harness 决定效果,它又为什么不能成为护城河?
这两个判断其实不矛盾。但要解释清楚,需要一个比"有 / 没有护城河"更精细的框架。
其实如今各类 Agent 独立产品确实没有持久壁垒。而 Agentic Harness,也就是围绕模型搭建的约束、反馈闭环与上下文工程系统,却又的确是当下效果差异的核心变量。注意"当下"两个字。也就是说,这个优势有保质期,而且不同层面的保质期差异很大:有些会在下一代模型发布时迅速归零,有些反而会随模型进步而增值。
所以本文要回答的问题是:这个保质期的结构长什么样,以及在窗口关闭之前,AI赛道的产品或技术决策者,又该押注在哪。
一、Harness 到底是什么?——从"包一层壳"到"设计环境"
1.1 Harness 的词源与隐喻
Harness 这个词来自马具——缰绳、鞍、嚼子——一整套引导马匹的装备。马很强壮、跑得快,但它自己不知道该往哪走。Harness 不增加马的力量,它让力量变成有用功。
这个隐喻套到 AI Agent 的工程系统上也成立。模型是马,Harness 是让它产出有用结果的那套系统。
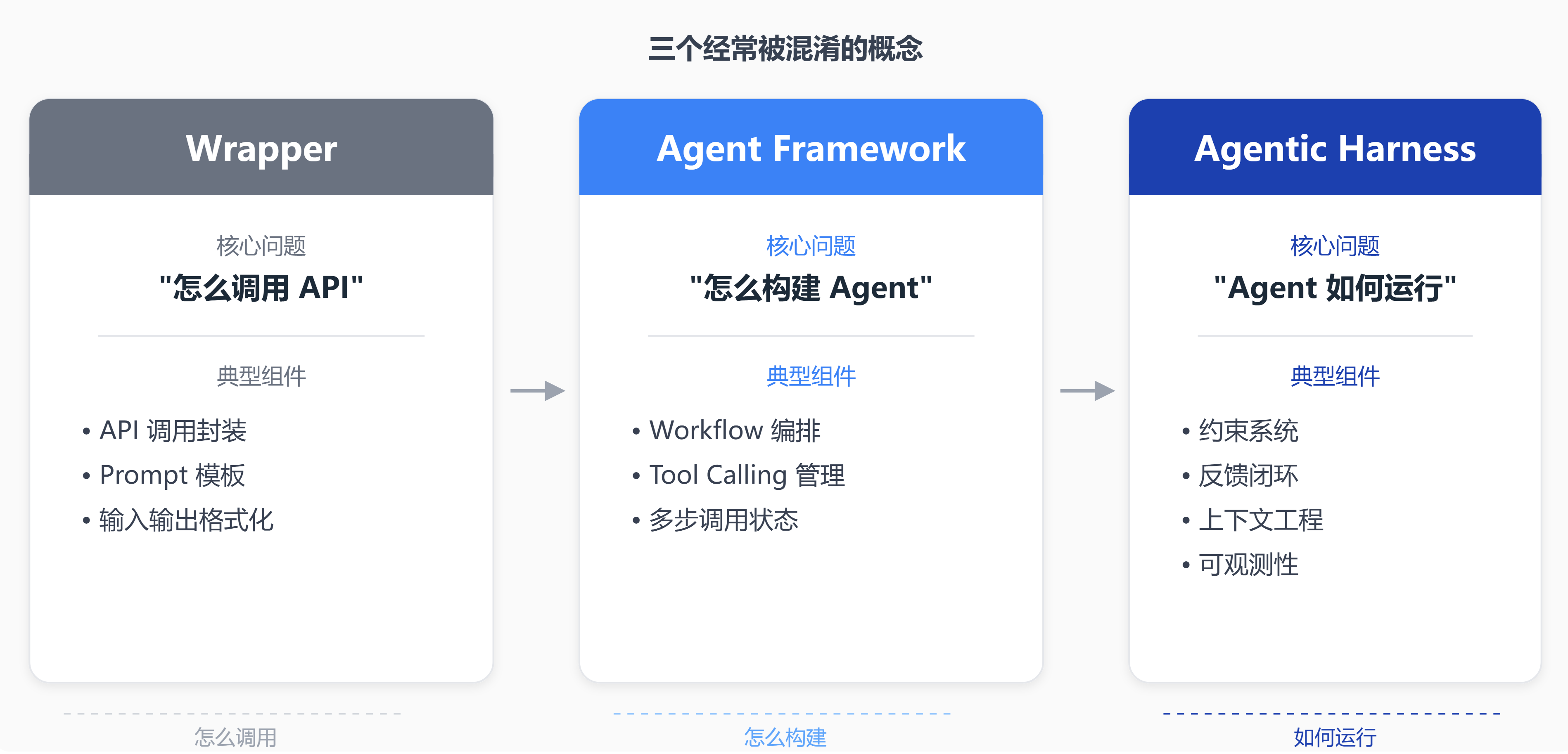
但行业里对这个概念的理解差异很大。三个经常被混用的词,其实指向三件不同的事:
Wrapper,字面意思,包一层壳。调用 API,加点 prompt,处理下输入输出格式。回答的问题是"怎么调用 API"。
Agent fr amework(LangChain、CrewAI 这类),往上走了一层:定义 workflow、编排多步调用、管理 tool calling。回答的问题是"怎么构建一个 Agent"。
Agentic Harness,再往上一层。约束系统、反馈闭环、上下文工程、可观测性——目标不是让 Agent 跑起来,而是让它跑对。回答的问题也不一样:"Agent 如何运行"。
前两者和 Harness 的分界线在于:SDK、fr amework、Scaffolding 解决的是构建问题——把零件拼成一个能跑的 Agent。Harness 解决的是运行问题——在真实环境里怎么跑、出错了怎么纠、怎么知道自己做对了。
1.2 OpenAI 的证明:往 Harness 里"加"什么
OpenAI 在今年 2 月发布的 Harness Engineering 一文里,提到一个反直觉的发现:早期 Codex 产出质量不行,瓶颈不在模型本身,而在运行环境太粗糙(原文用的词是 underspecified)。
于是工程师的工作内容变了。写代码不再是主要任务,取而代之的是三件事:设计运行环境、指定意图、构建反馈闭环。Agent 失败时,修复方式不是"再试一次",而是追问一个具体问题——"它缺了什么能力"——然后把这个能力补进环境。
OpenAI 的方法论方向是加法。接入 Chrome DevTools Protocol,Agent 就能直接操作浏览器;搭本地可观测性栈,运行状态一目了然;做 agent-to-agent review,一个 Agent 审查另一个的产出。一项一项补进去,Agent 能触达的世界越来越大。
1.3 Anthropic 的证明:从 Harness 里"减"什么
Anthropic 的方向恰好反过来——减法。
核心原则是 "find the simplest solution possible, and only increase complexity when needed"。不是往 harness 里堆东西,而是反复追问:哪些组件是真正必要的。
这个原则落到实处,最典型的做法是消融实验——逐一移除 harness 中的组件,观察对结果的影响。Anthropic 在今年的一篇 harness 设计文章中写道:
"harness 中的每一个组件都编码了一个关于模型自己做不了什么的假设。这些假设值得不断压力测试——既因为它们可能本身就是错的,也因为随着模型进步它们会很快过时。"
”
Anthropic 自己就在不断拆除和重建 Claude Code 的 harness——从最初的极简 CLI,到后来加入 Skills、Hooks、Sub-agents 形成完整体系,再到旧组件不断被拆掉。
Vercel 在构建 AI agent 时走过同一条路:砍掉 80% 的工具后,效果反而大幅提升。减法不是 Anthropic 一家的偏好,它是 harness 设计中的通用规律。
本节小结
OpenAI 证明了 harness 能创造多大的价值,Anthropic 证明了 harness 必须随模型演进不断被简化。两件事同时成立,这正是 Harness 区别于"静态 wrapper"的地方:它不是写好就不动的配置文件,而是一个需要持续演进的活系统。
它是模型能力和现实生产力之间绕不开的一层。但这一层长什么样,取决于模型本身——而且必须随模型持续演变。
二、Harness 效果与模型能力的深度绑定
有些 Harness 效果好,有些差。差异的来源往往不是 Harness 本身的工程水平,而是它与底层模型之间的适配深度。这种适配发生在三个层面。
2.1 格式亲和性(Format Affinity):模型在训练时已经"选边站"了
Harness 效果的第一决定因素,是模型在训练阶段所接触的指令格式、工具调用 schema、输出结构,与 Harness 实际提供的格式之间的匹配度。模型在训练时就对某种格式产生偏好,这个偏好直接影响它在不同 Harness 上的表现。
OpenAI 为 Codex 专门训练的 codex-1 模型,在训练阶段和 apply_patch 这个特定的文件编辑工具深度绑定。开源项目 OpenCode 为了让 Codex 在自己的 harness 上跑出好效果,不得不专门加了一个 apply_patch 工具来模仿 Codex 原生 harness 的格式。而 Claude 等其他模型在同一个 harness 上继续使用普通的 edit/write 工具就够了,完全不需要这层适配。
同一个 harness,对不同模型需要暴露不同的工具接口。
类似的情况也出现在别处。GLM-5 在 Claude Code 上的表现显著优于 OpenCode,原因不是 Claude Code 本身更好,而是 GLM-5 在训练时更多接触了 Claude Code 风格的格式。
所以最强的 Harness 不是独立于模型存在的,而是和模型协同演进的。"通用 Agent 框架"的叙事在这里遇到了一个实际的障碍——没有"万能 Harness",只有"和特定模型最匹配的 Harness"。
格式亲和性还有一个不太显眼的效应:隐性 lock-in。当开发者生态围绕某种 Harness 格式建立了大量的 AGENTS.md、Skills、Hooks,切换到另一个 Harness 的成本就不仅是技术迁移,还包括重新适配模型对新格式的理解。格式本身成了一种粘性。
2.2 能力补位 vs 能力发挥:一条动态的价值曲线
格式亲和性是静态的,由模型训练阶段决定。但 Harness 的价值还有一个动态维度:随着模型能力的演进,Harness 的角色会从"补模型不会的"转向"让模型做得更好"。
当前阶段,补位为主。 现在的模型普遍还缺一些能力:UI 操作(browser use)、文件系统交互、长链调用的状态管理、跨 session 的记忆。Harness 在这些领域的补位价值很直接——给模型接上浏览器它就能操作 UI,给它 sandbox 它就能安全执行代码,给它 memory 系统,它就能跨会话保持上下文。
OpenAI 在 Harness Engineering 中做的就是补位:把 Chrome DevTools Protocol 接入 Agent runtime,让 Codex 能直接操作浏览器、复现 bug、验证修复。Anthropic 在长时 Agent 的实践中方向一致,用 initializer agent 设置环境、维护 progress file,本质上是在补"跨 session 记忆"这个缺失能力。
但补位有保质期。 OpenAI 今年 3 月发布的 "From model to agent" 一文,已经在讲如何把工具能力内化到 Responses API 中。一旦模型原生支持 browser use,Harness 里那个 browser adapter 就从核心资产变成了可能的干扰项。
到了那个阶段,Harness 的价值转向"发挥"——谁能让模型的新能力释放得更充分。这需要更精细的约束设计和更高质量的反馈闭环。不是补缺,是放大。
这种从补位到发挥的转变有一个极端案例。Sora 本质上是把视频生成能力外挂成独立产品。上线第一天登顶 App Store,六个月后被 OpenAI 亲手关停。技术并没有死——负责人 Bill Peebles 透露,研究方向转向了"世界模型",目标是通过高保真环境模拟服务于机器人技术。Sora 死于产品形态:能力需要被更大的系统包含,独立存在没有稳态。
这条规律的一般形式是:任何在 Harness 中被证明有价值的能力模块,归宿要么是被模型权重吸收,要么是被更大的 Harness 系统吸收。
这就引出了一个设计原则——可撕裂性(Rippability):好的 Harness 应该让每个模块都能被轻松移除。当模型变强时,Harness 里那些曾经"聪明"的逻辑可能反而成为干扰。Anthropic 的消融实验(见 1.3 节)就是在实践中做这件事:逐一关掉组件,看效果是否下降。如果不降反升,说明那个组件该拆了。
2.3 反馈闭环的质量:Harness 的隐性差异化
在格式匹配、能力互补都到位的前提下,Harness 之间真正的效果差异来自第三个因素:反馈信号的质量。
什么是高质量反馈?结构化的 lint 结果、typed test output、精确的 error location、可执行的验收场景。什么是低质量反馈?把 stderr 原样丢回去,只告诉"失败了"不告诉"在哪失败的",没有可复现的验证路径。
两种做法的差距在实践中很具体。OpenAI 让 Codex 能直接读取 logs、metrics、traces,不是"告诉模型出了什么问题",而是"让模型自己看到问题的全貌"。Anthropic 要求 agent 每完成一个 feature 就跑 end-to-end 测试、把结果写进 progress file——下一个 session 的 agent 不需要猜,直接看到验证状态。
反馈质量和模型能力是耦合的。模型越强,它从结构化反馈中提取的信息就越多,高质量反馈的投入就越值得。反过来,如果模型对 structured error 的理解能力弱,再精细的 lint 结果也只是在浪费 context window。反馈系统的设计需要随模型能力同步演进。
Martin Fowler 的团队在评论 OpenAI Harness Engineering 一文时,指出了文中一个缺失:"功能和行为的验证"。有了约束和上下文还不够,还需要闭环的验证机制来确认产出确实满足意图。这个缺失本身说明了反馈闭环在 Harness 设计中的位置:它是最难做到位的部分,也正因如此,是最有区分度的部分。
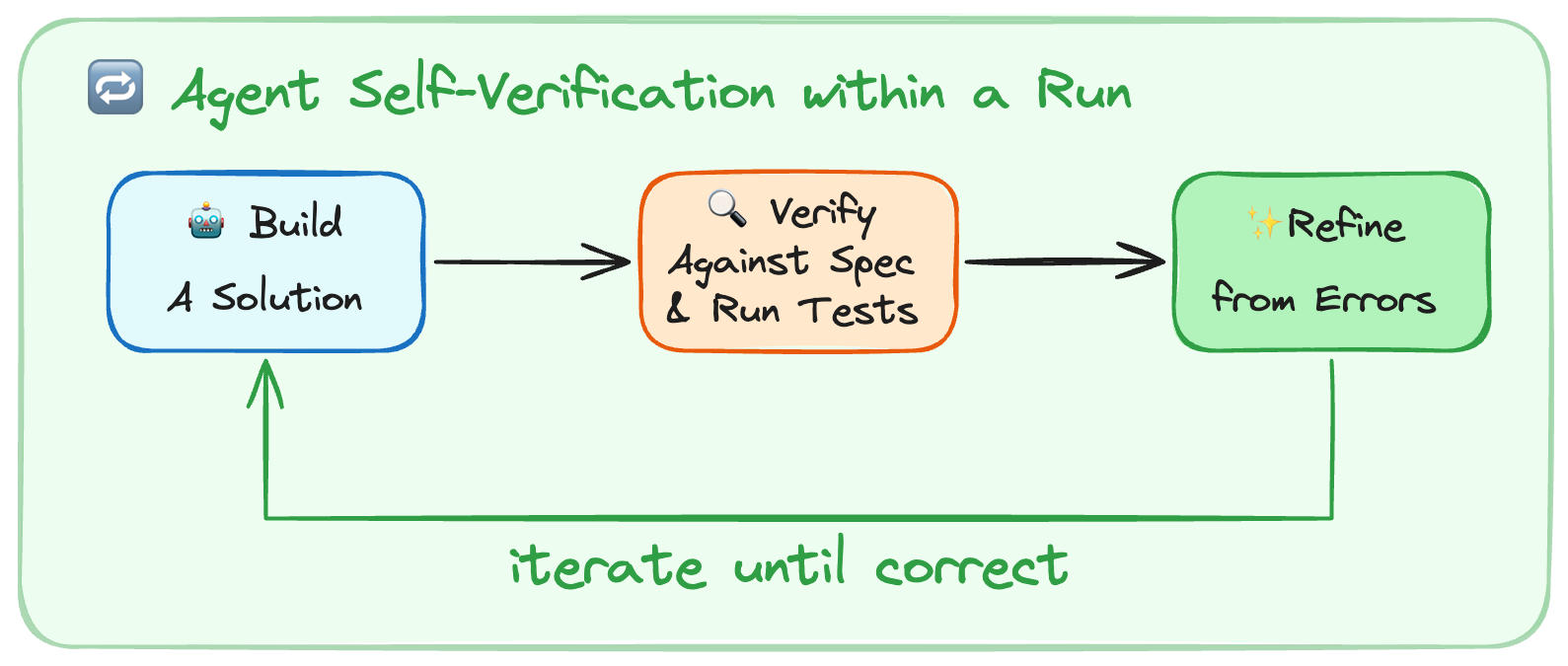
Agent 自验证循环:构建 → 对照规格验证并运行测试 → 从错误中修正,反复迭代直至通过。图源:LangChain — Improving Deep Agents with Harness Engineering
”
2.4 三层因素的整合:Harness 价值衰减曲线
三层因素——格式亲和(训练时决定)、能力匹配(随模型演进动态变化)、反馈质量(Harness 自身的工程深度)——逐层深入,且每一层都和模型的能力状态深度绑定。
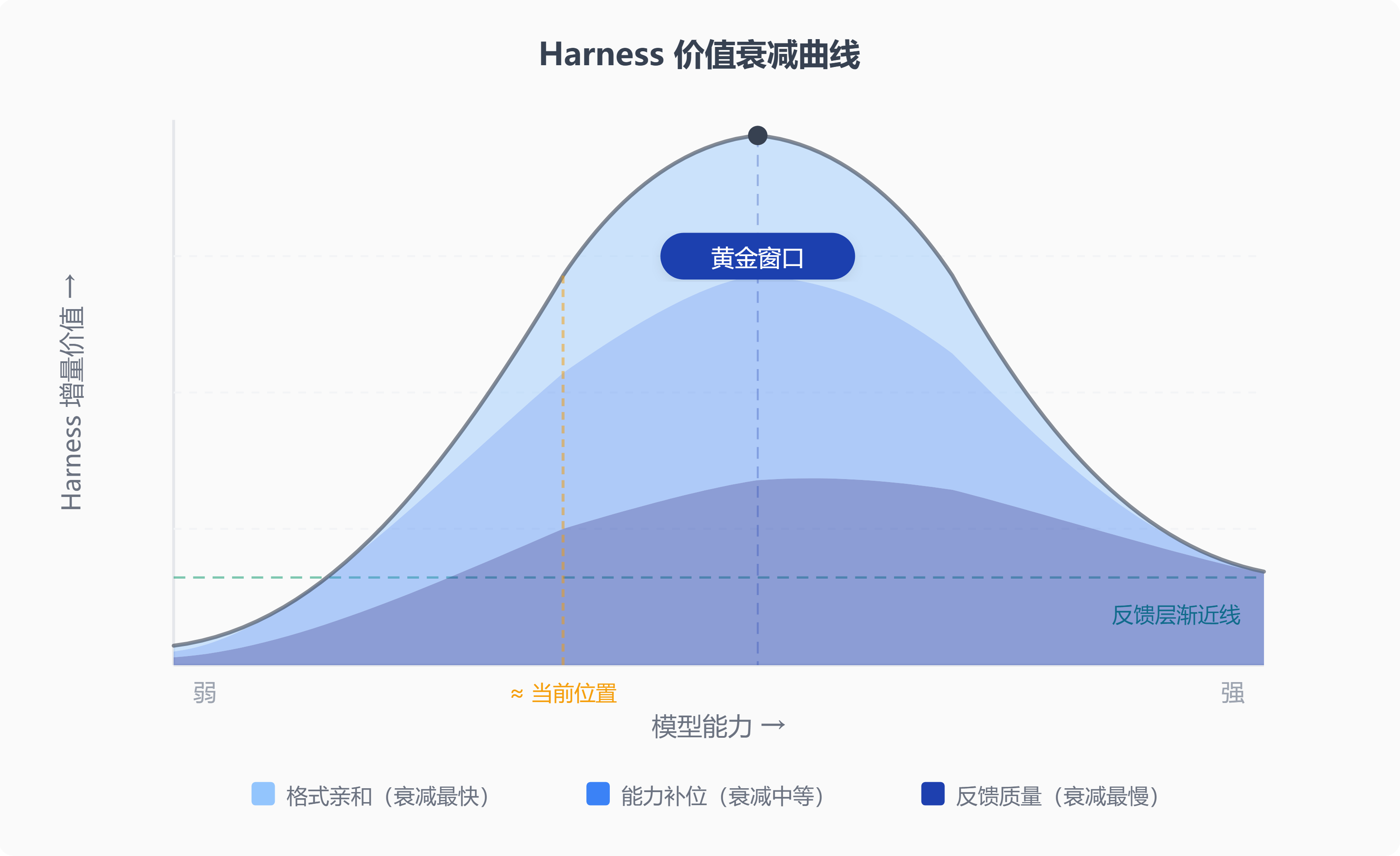
这三层可以整合为一条Harness 价值衰减曲线:以模型能力为横轴、Harness 带来的增量价值为纵轴,曲线呈倒 U 型。在模型能力较弱时,Harness 的补位价值随模型能力提升而增大——模型越强,Harness 能释放的潜力越多。但越过某个拐点,模型开始内化 Harness 曾经提供的能力,增量价值开始下降——格式亲和性被泛化能力抹平,补位空间被原生能力挤压,只剩反馈质量这一层仍然有持久价值。
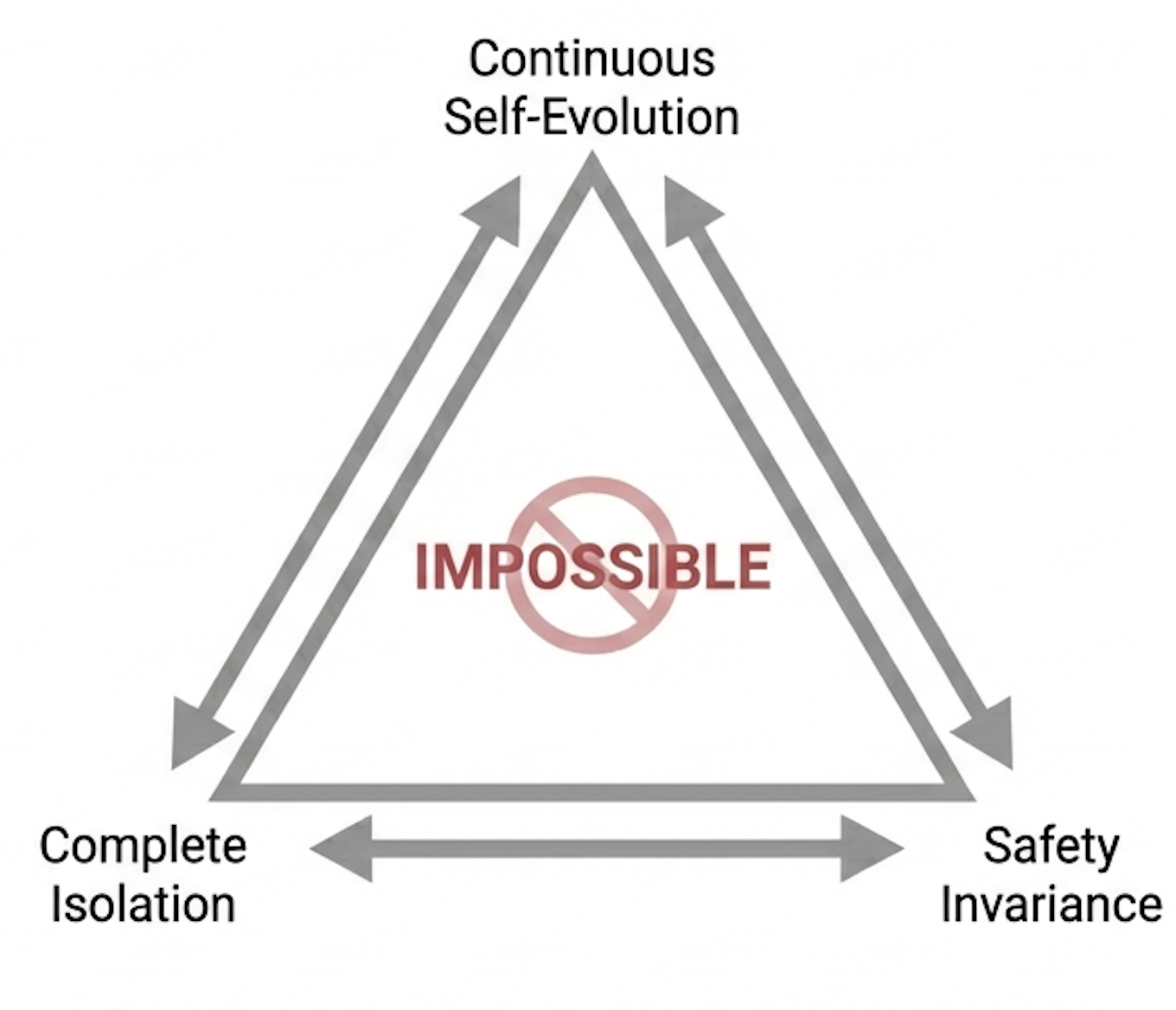
反馈质量的持久性有比"领域知识难以吸收"更根本的原因:AI 安全领域的一项研究(arXiv:2602.09877)揭示了一个结构性约束:如果模型在完全封闭的环境中持续自我进化,对齐会不可逆地降解。研究者将其概括为"自进化三难困境"——连续自进化、完全隔离、对齐不变性,三者最多取其二。换言之,外部反馈信号不是工程上的权宜之计,而是模型保持对齐的结构性需求。反映在衰减曲线上,右侧存在一条渐近线:无论模型能力如何增长,反馈基础设施的价值不会归零。
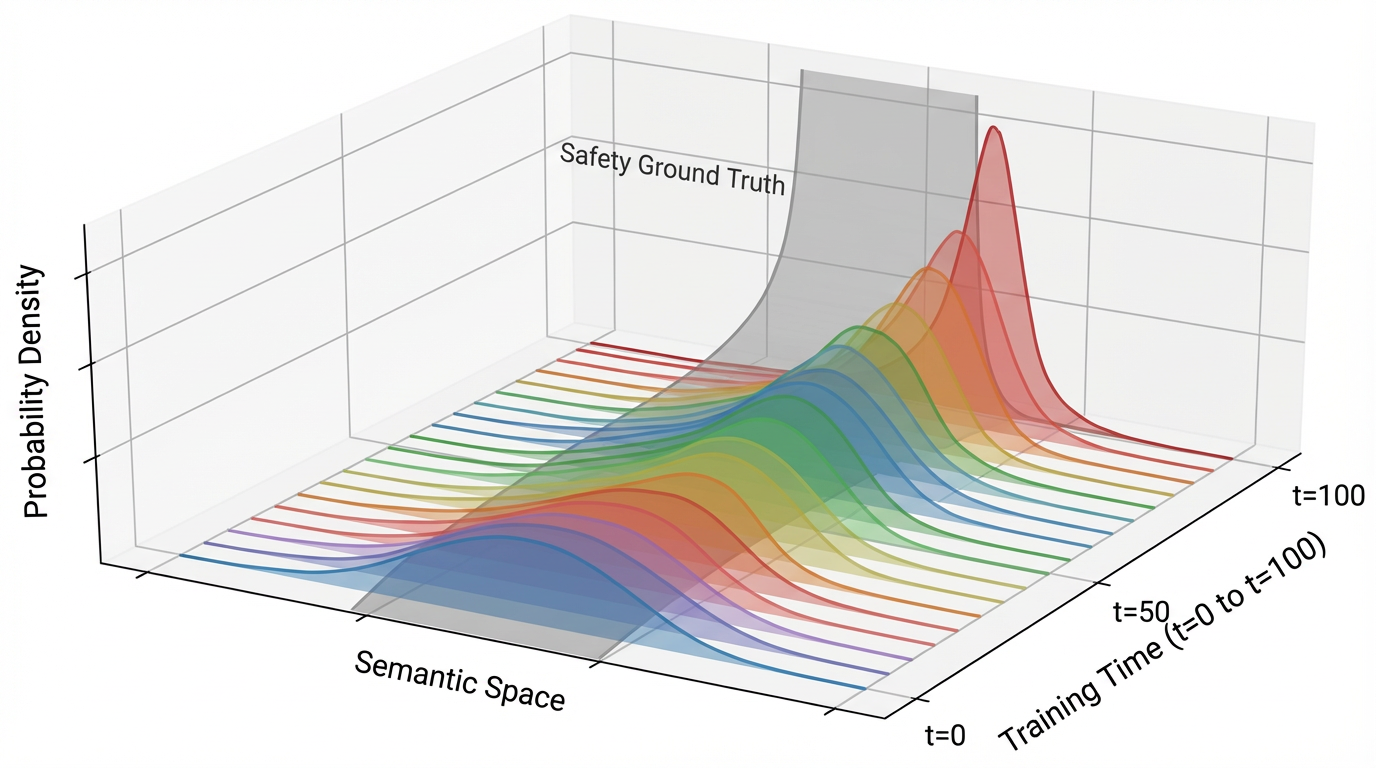
这条曲线的峰值,就是 Harness 的"黄金窗口"。每一代模型的发布会把峰值向右推移——窗口不会永远关闭,但窗口内 Harness 能做的事会越来越少、越来越精细。
本节小结
Harness 效果的差异,根源不在 Harness 自身的工程水平,而在它与底层模型的适配深度。这种适配会随模型演进而衰减,但衰减速度在三个层面上截然不同。
曲线描述的是"是什么"。接下来的问题是:如果价值注定衰减,Harness 到底能不能构成护城河——以及在窗口关闭之前,该怎么办。
三、为什么 Harness 重要但不构成持久护城河
3.1 先看反方:有人说 Harness 就是护城河
有一派观点认为,Harness 正是新的护城河。Aakash Gupta 的一段话概括了这个立场:"Model quality is converging... New moat: harness quality. You can't download harnesses from Hugging Face."
工程积累方面的证据确实存在。Manus 重写了五次 harness,LangChain 重构了四次 Deep Research,每一次迭代都踩过前一版的坑。这些经验不是几周能复制的。

但工程积累和结构性壁垒是两件事。工程积累意味着"我比你多走了几步"——后来者可以追赶。结构性壁垒意味着"即便你知道怎么做,你也做不了"——网络效应、数据飞轮、独占资源属于后者。Harness 的积累属于前者。
3.2 再看数据:效果差异可能比想象中小
METR 和 Scale AI 联合发布的 SWE-Atlas 评测给了一组数据:Opus 4.6 在 Claude Code 中的得分,只比通用 SWE-Agent 高 2.5 个百分点。GPT 5.2 的情况更反直觉——它反而在通用 scaffold 中表现更好,专用 harness 没有带来额外优势。
METR 的另一项研究进一步揭示了 benchmark 数据的局限性:即便代码通过了自动化评测,约半数 PR 会被仓库维护者拒绝合并——实际通过率与 benchmark 得分之间存在系统性落差。
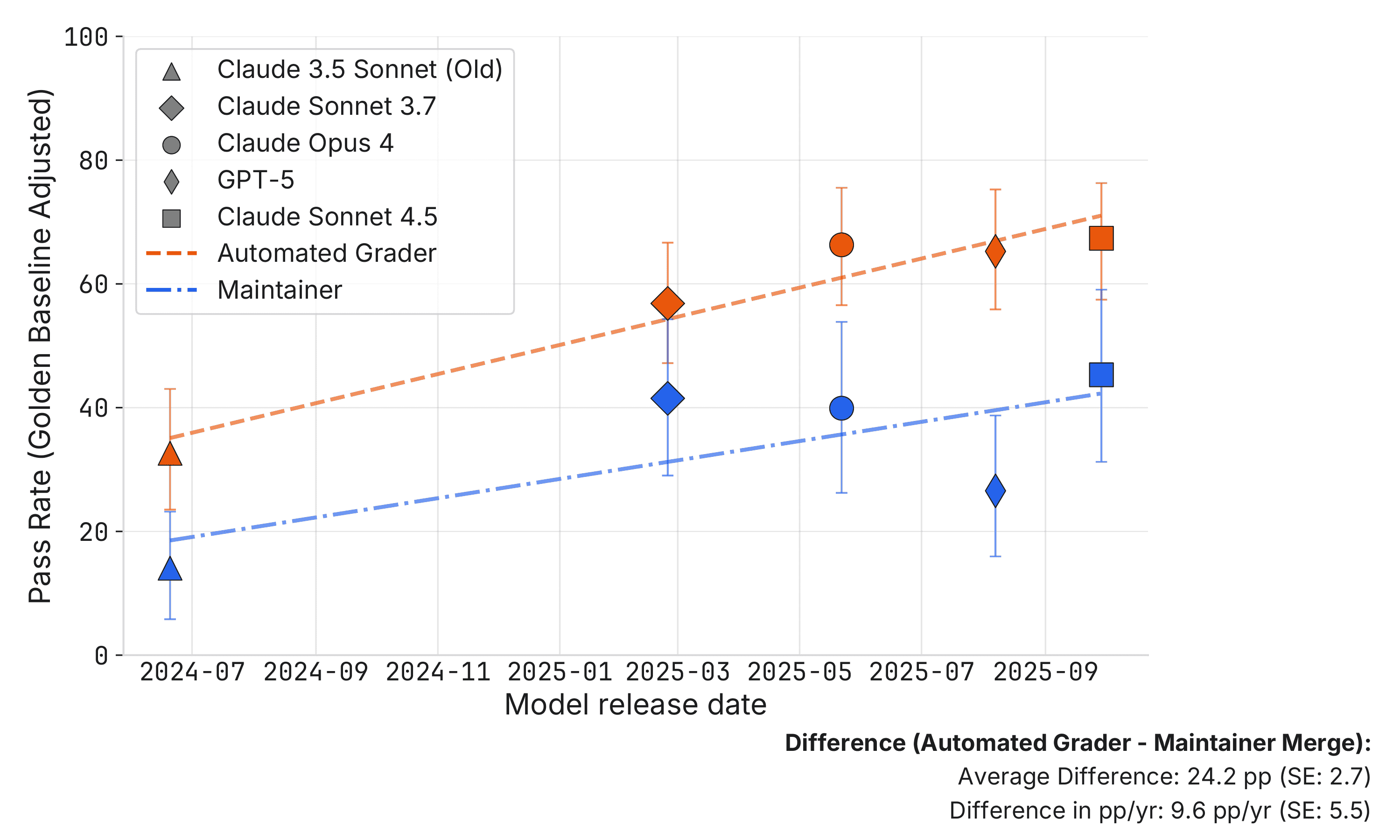
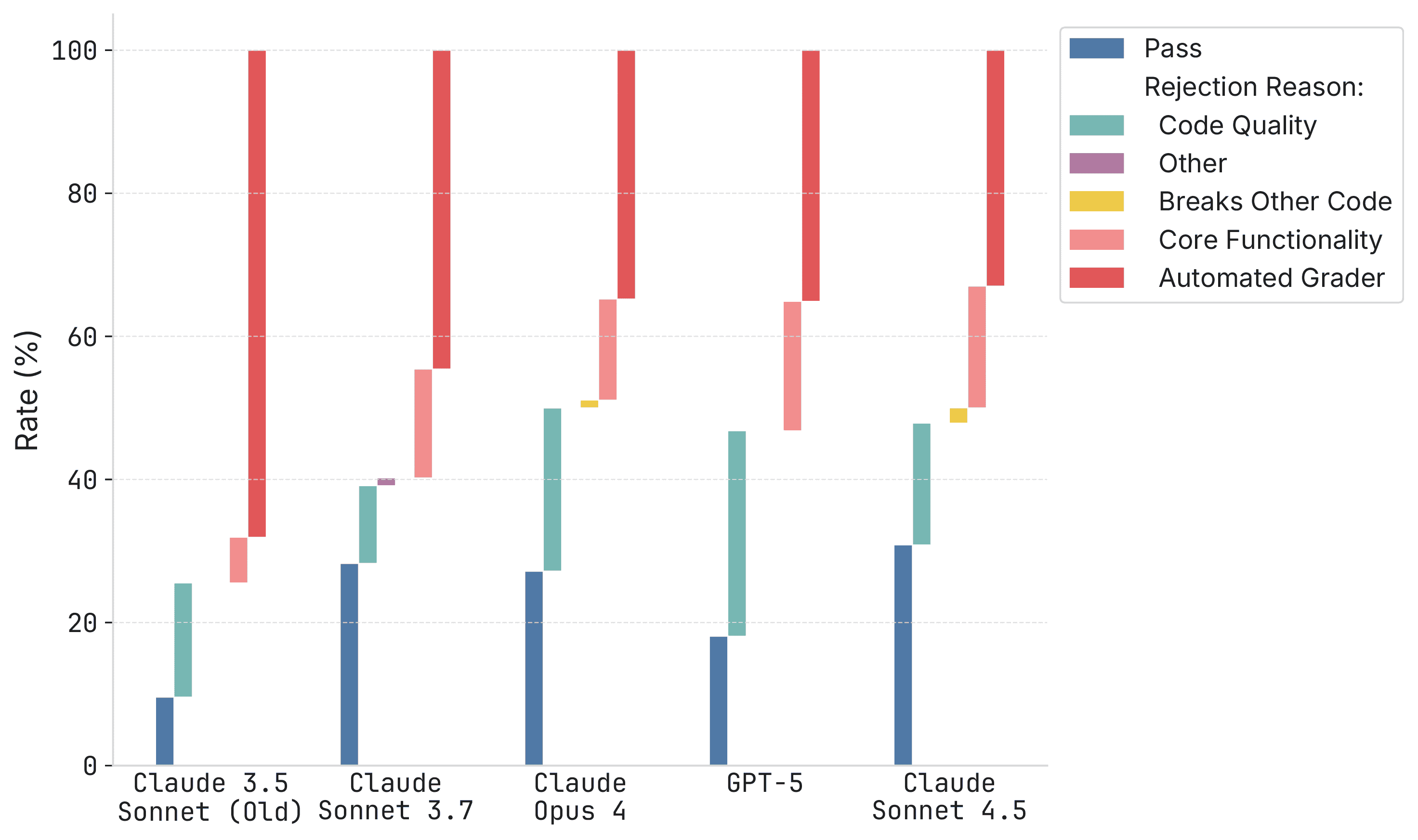
Noam Brown 的看法是:在推理模型出现之前,大量工程投入花在为非推理模型搭建 agentic scaffolding 上。但推理模型出来后,"you just give the reasoning model the same question without any sort of scaffolding and it just does it." 他认为建在推理模型之上的那些 scaffolding,同样会被替代。
这些数据和开篇提到的 42% vs 78% 并不矛盾。
开篇的数据测量的是"有 harness vs 无 harness"——近乎翻倍的差异,说明 harness 作为一个类别是决定性变量。SWE-Atlas 的 2.5 个百分点测量的是另一件事——"不同 harness 之间"的差异。当模型足够强,顶级 harness 之间的效果差距在快速收窄。
两组数据放在一起,对应的正是第二节描述的价值衰减曲线的后半段:模型越过拐点之后,harness 的增量价值开始下降,不同 harness 之间的差距也随之缩小。补位空间在收窄,格式亲和性被泛化能力抹平,harness 能做的事越来越精细。
3.3 两股吞噬力量
Harness 的领先优势正在被两个方向同时挤压。
第一个方向来自模型本身。 Harness 中任何被证明有价值的能力,最终都会被训练进模型权重。今天在 Harness 里做的 browser use adapter,明天可能就是模型的原生能力——OpenAI 今年 3 月的 "From model to agent" 一文已经在讲怎么把这些工具能力内化到 Responses API 中。推理模型替代 scaffolding,是同一种力量的另一个表现。
第二个方向来自开源社区。 Harness 的工程门槛不在于"你知道了别人还是做不了"这种深度。AGENTS.md 的最佳实践、Skills 的设计模式、Hook 的配置方法,一旦被验证有效,几周内就会扩散。Skills 最初由 Anthropic 为 Claude Code 引入,如今 Codex 和 OpenCode 也已支持——从私有特性到行业通用,花了不到几个月。
两股力量叠加:模型从上方吞噬能力,社区从侧面复制方法。Harness 层面的任何领先,都是时间窗口型优势,不是结构型优势。窗口可能是 3 个月,可能是 6 个月,但它会关闭。
3.4 更精确的描述
回到 Melly 的判断。"Agent 只是大模型还没来得及原生做掉的一层临时界面"——方向正确,但不够精确。
Harness 不是临时界面,它是模型能力的释放管道。管道本身确实没有独立的"赛道"地位,但在模型能力尚未被完全释放之前,管道的设计质量直接决定了用户感知到的 AI 能力水平。而"尚未完全释放"这个状态,可能会持续相当长的时间。
但 Melly 对"不要把缺口包装成护城河"的提醒依然成立。管道重要,不等于管道是壁垒。
3.5 唯一可能的弱护城河——但极脆弱
如果一个玩家能同时触碰模型训练流程和 Harness 设计,就有可能形成一种弱耦合:让模型在训练时就对特定 Harness 的格式、工具调用方式、上下文结构形成偏好。codex-1 与 apply_patch 的深度绑定(见 2.1 节)就是这种耦合的实例——不是因为 Harness 本身难做,而是因为"让模型在你的 Harness 上效果最好"需要和训练过程深度协同。
但即便是这种弱护城河,也面临被下一代模型冲破的风险。模型的泛化能力每一代都在增强,今天的格式偏好在下一代模型上可能就不再成立。它更像是每代模型都需要重新构筑的沙堡,而非一劳永逸的城墙。
本节小结
Harness 重要,但不构成持久护城河。工程积累可以追赶,补位价值会被模型逐步吸收,方法论扩散得很快。唯一接近壁垒的模型-Harness 协同训练,也是每代模型都需要重建的脆弱优势。
但"没有护城河"这个判断本身只回答了一半问题。第二节建立的三层模型告诉我们,不同层面的价值衰减速度截然不同。而衰减速度的差异,恰好指向了一个更实用的问题——在窗口关闭之前,资源该怎么分配。
四、战略推论:三层衰减,三种投资姿态
4.1 一个元原则:按衰减速度分配资源
第二节建立的三层模型也可以反过来读:三层因素的衰减速度不一样,这本身就是一个决策依据。
格式亲和性衰减最快。下一代模型的泛化能力可以直接抹平上一代的格式偏好。codex-1 和 apply_patch 的深度绑定,到 codex-2 可能就不存在了。
能力补位衰减中等。模型会逐步内化这些能力,但不是一夜之间,而是一个能力一个能力地吃掉。browser use 今年还是 harness 的补位价值,明年可能就被模型原生支持了;但跨 session 记忆的完全内化可能还需要更长时间。
反馈质量衰减最慢。反馈系统天然是领域特定的,模型很难泛化地吸收"怎么给某个特定 codebase 的 CI 结果做结构化解析"这种知识。而且模型越强,它从高质量反馈中提取的信息越多,反馈基础设施的价值反而递增。
衰减速度不同,投资策略就不该是"三层都做"或"只做一层",而是按衰减速度分配权重——把最多资源投在衰减最慢的层,最少资源投在衰减最快的层。
这给了决策者一个简单的判断框架:面对任何 harness 投资决策,先问——"这属于哪一层?衰减多快?"答案直接决定投入力度。
4.2 三层投资姿态

格式亲和性(衰减最快)→ 跟随,而非引领
一句话:选马先于选鞍。先确定我们要骑哪匹马,再围绕它的体型去定制鞍具。
这跟"先选框架,再接各种模型"的主流做法是反着来的。GLM-5 在 Claude Code 上表现好、在 OpenCode 上表现差(见 2.1 节),不是框架的问题,是选马和选鞍的顺序反了。OpenCode 为 Codex 专门加 apply_patch,就是在按马的体型改鞍。
评估一个 harness 方案时,第一个问题不该是"功能全不全",而是"它和我们选定的核心模型的格式亲和度有多高"。这一层的投资周期等于一个模型版本周期,跟着核心模型走就够了。
能力补位(衰减中等)→ 选择性下注,随时可撕
Harness 里的每一个补位模块都编码了一个判断:"模型目前做不了 X,所以我来补。"每个这样的判断都是一张赌注,模型的每次大版本更新都在缩短它的到期日。
一个可操作的做法是给每个 harness 组件贴一张"假设标签",写清楚"此组件存在的前提是模型不具备 Y 能力"。每次模型大版本更新后,对照标签做消融审计:关掉这个组件,效果是否下降?不降反升,说明假设已过期,组件该拆了。Anthropic 在实践中做的正是这件事(见 1.3 节的消融实验)。
多数团队把"定期拆组件"当维护成本。换个角度看:谁先发现并拆掉过期赌注,谁的 harness 就更轻、更快、更不会干扰模型的原生能力。拆掉过期组件不是维护,是竞争动作。每个季度花一天做消融审计,比花一个月加新功能更有价值。
反馈质量(衰减最慢)→ 重仓
格式亲和性由模型厂商决定,我们控制不了。补位空间会被模型进步吞噬,我们留不住。三层里唯一一个投资回报随模型进步递增的方向,是反馈信号的基础设施:结构化的 lint 输出、精确的 error location、typed test results、可执行的验收场景。
Noam Brown 说过,推理模型出来后,大量 scaffolding 直接没用了。编排逻辑是最先被淘汰的。但反馈基础设施不会,模型越强,它从高质量反馈中提取的价值越大(见 2.3 节)。自进化三难困境(见 2.4 节)从安全理论的角度给出了同样的结论:外部反馈信号不是工程上的权宜之计,而是模型保持对齐的结构性需求。
如果预算有限,砍编排层的复杂度,保反馈层的深度。投资信号,而非逻辑。
4.3 产品思维 vs 平台思维
三层投资姿态回答了"投什么",但还有一个前置问题:投资的载体应该是什么形态。
在时间窗口型赛道上,把能力做成独立产品是危险的。Sora 的教训已经说明了这一点(见 2.2 节):独立产品带着独立团队、独立路线图,还有独立的资源争夺,而能力边界每几个月就要重划一次,这种组织形态根本跟不上。Fidji Simo 说的"不能被支线任务分心",翻译过来就是:产品思维在这个赛道上是危险的,平台思维才是对的。
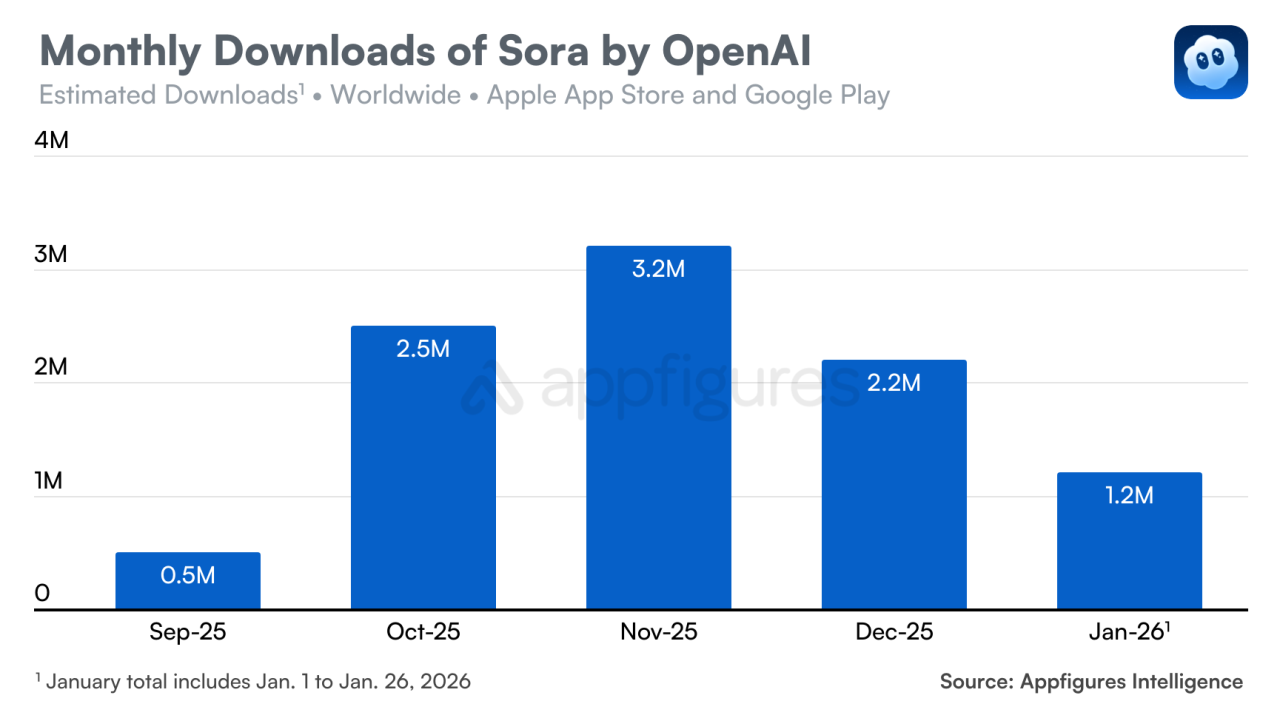
Anthropic 没有把 Claude Code 做成独立产品线。它是模型能力释放的一个持续演进的 harness,Skills、Sub-agents 这些组件随时加、随时拆。这种"可组合、可拆卸"的形态天然适配时间窗口型赛道。
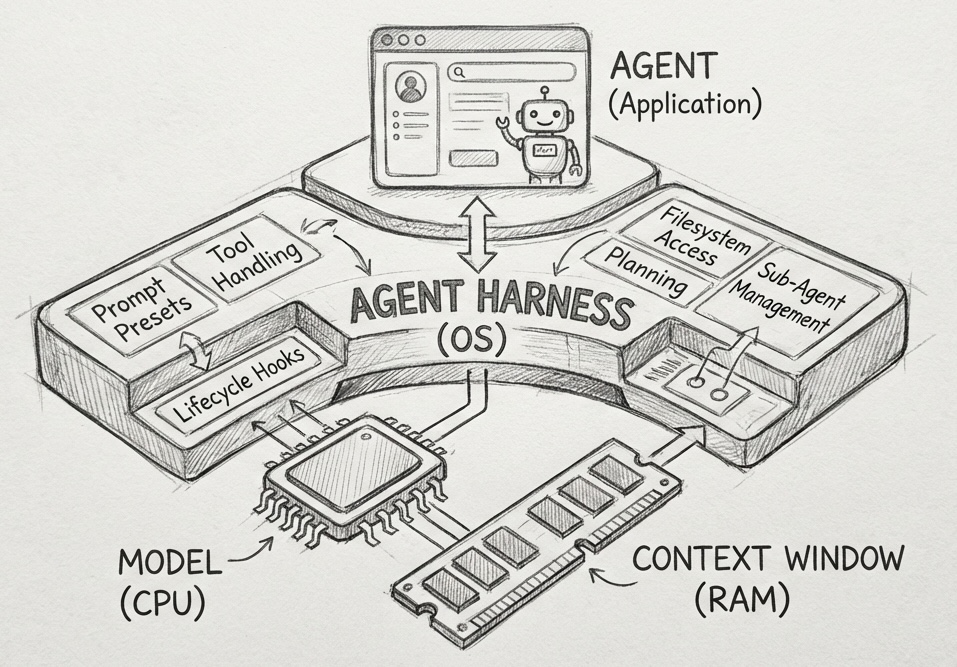
往更大的格局看,harness 正在从单一运行环境变成 AI 能力的通用抽象层,类似当年 Windows 对硬件的抽象。目标不是做一个产品,而是定义 AI 能力被调用的方式本身。
4.4 对平台方的额外启示
以上适用于所有构建 harness 的团队。对于同时拥有模型和 harness 的平台方,还有一层额外机会:模型-Harness 协同训练(见 3.5 节),让模型在训练时就对自家 harness 的格式和工具调用方式形成偏好;以及系统级集成——跨设备上下文、安全沙箱、硬件级隐私保护——这些是开源 harness 结构上做不到的。
OpenAI 将 ChatGPT、Codex、Atlas 合并为统一平台,底层逻辑正是这两点的叠加:用协同训练建立模型偏好,用系统级集成拉开体验差距。
本节小结
三层衰减速度的差异,给出了一张当前窗口内的资源分配地图:格式层跟随,补位层可撕,反馈层重仓。载体上,平台思维优于产品思维。
但地图本身也有保质期。每一代模型的发布都会重划能力边界,今天的重仓方向,明天未必还是。接下来的问题不再是"投什么",而是当我们接受这张地图会被反复重画时,该持什么姿态。
五、结语:不要做"产品",要做"能力释放的管道"
三件事同时为真:Agent 没有独立赛道,Harness 决定当下效果,Harness 本身不构成持久护城河。这三件事并不矛盾。矛盾的表象来自一个被忽略的维度:时间。Harness 的价值不是一个定值,而是一条衰减曲线,不同层面的衰减速度截然不同。这个结构性差异,才是决策的真正支点。
所以,不要把 harness 能力做成独立产品,要做能力释放的管道。独立产品追求稳态,带着固定的边界和独立的路线图。但这个赛道没有稳态。每一代模型的发布都在重划能力边界,今天精心设计的管道,下个季度可能就该推翻重来。接受这一点,意味着从一开始就按"可拆卸、可重建"去设计,而不是追求一劳永逸。
但不是所有管道部件都衰减得一样快。格式偏好会被下一代模型的泛化能力直接抹平,补位模块会被逐步吸收为原生能力,唯独反馈信号的基础设施——结构化的 lint 输出、精确的 error location、typed test results——会随模型变强而增值。Anthropic 说过:"harness 中的每一个组件都编码了一个关于模型做不了什么的假设。"这些假设会过时,管道会被重建。但在重建之前,它就是决定效果的那个变量。投资信号,而非逻辑。
Agentic Harness 的窗口期不会太长。马每个季度都在变强,今天合身的鞍具,三个月后未必还合。但此刻,没有鞍具的马拉不动车。
| # | 案例 | 出处 | 首次出现 | 用于支撑的论点 |
|---|---|---|---|---|
| 1 | "Agent 只是时间差套利" | Melly,微信文章,2026.3 | §0 开篇 | Agent 作为独立产品没有持久壁垒 |
| 2 | 3 人 5 月 100 万行代码零行手写 | OpenAI,Harness Engineering,2026.2 | §0 开篇 | Harness 是效果的决定性变量 |
| 3 | 同一模型 42% vs 78% benchmark | Nate B Jones,Substack,2026.3 | §0 开篇 | 有无 Harness 带来数量级差异 |
| 4 | 早期 Codex 瓶颈在环境而非模型 | OpenAI,Harness Engineering,2026.2 | §1.2 | 工程师角色从写代码转向设计运行环境 |
| 5 | Chrome DevTools Protocol 接入 Agent | OpenAI,Harness Engineering,2026.2 | §1.2 | Harness 的加法方法论——扩大 Agent 可触达的世界 |
| 6 | Anthropic 消融实验:逐一移除 Harness 组件 | Anthropic,Harness Design for Long-Running Apps,2026 | §1.3 | Harness 每个组件都编码了对模型局限性的假设;减法是设计通则 |
| 7 | Claude Code 从极简 CLI 到 Skills/Hooks/Sub-agents 的持续演进 | Anthropic,Building Effective Agents | §1.3 | Harness 是持续演进的活系统,不是写好就不动的配置 |
| 8 | Vercel 砍掉 80% 工具后效果反而提升 | Aakash Gupta,Medium,2026.1 | §1.3 | 减法不是 Anthropic 一家的方法论,而是 harness 设计的通用规律 |
| 9 | codex-1 与 apply_patch 的深度绑定 | OpenAI,Harness Engineering,2026.2 | §2.1 | 格式亲和性:模型在训练时就对特定工具格式产生偏好 |
| 10 | OpenCode 为 Codex 专门加 apply_patch 工具 | HumanLayer Blog,2026.3 | §2.1 | 同一 harness 对不同模型需暴露不同工具接口 |
| 11 | GLM-5 在 Claude Code 上表现显著优于 OpenCode | 直接观察 | §2.1 | 格式亲和性由训练数据决定,非框架本身优劣 |
| 12 | 格式生态形成隐性 lock-in | 综合推论 | §2.1 | 生态使切换 Harness 的成本超越技术迁移 |
| 13 | Codex 接入 Chrome DevTools Protocol 操作浏览器 | OpenAI,Harness Engineering,2026.2 | §2.2 | 当前阶段 Harness 以能力补位为主 |
| 14 | Anthropic 长时 Agent:initializer agent + progress file | Anthropic,Effective Harnesses for Long-Running Agents,2026 | §2.2 | 补"跨 session 记忆"这一缺失能力 |
| 15 | OpenAI From Model to Agent:工具能力内化到 Responses API | OpenAI,2026.3 | §2.2 | 补位价值有保质期——模型会逐步内化 Harness 能力 |
| 16 | Sora 上线首日登顶 App Store,6 个月后关停 | TechCrunch,2026.3 | §2.2 | 能力模块独立存在没有稳态;产品形态错误的极端案例 |
| 17 | Bill Peebles 透露 Sora 技术转向"世界模型" | Deep Insights,2026.3 | §2.2 | 能力的归宿是被更大系统吸收,而非独立存在 |
| 18 | "可撕裂性"(Rippability)设计原则 | NxCode,2026.3 | §2.2 | 好的 Harness 让每个模块都能被轻松移除 |
| 19 | Codex 直接读取 logs/metrics/traces | OpenAI,Harness Engineering,2026.2 | §2.3 | 高质量反馈 = 让模型自己看到问题全貌 |
| 20 | Anthropic agent 每完成 feature 跑 e2e 测试写入 progress file | Anthropic,Effective Harnesses for Long-Running Agents,2026 | §2.3 | 闭环验证机制:下一 session 直接看到验证状态 |
| 21 | Martin Fowler 团队评论缺少"功能和行为的验证" | martinfowler.com,2026.3 | §2.3 | 反馈闭环是 Harness 设计中最难也最有区分度的部分 |
| 22 | 自进化三难困境:连续自进化 / 完全隔离 / 对齐不变性不可兼得 | arXiv:2602.09877,2026.2 | §2.4 | 外部反馈信号是模型保持对齐的结构性需求;衰减曲线存在渐近线 |
| 23 | "Model quality is converging… New moat: harness quality" | Aakash Gupta,Medium,2026.1 | §3.1 | Harness 护城河论的代表性声音 |
| 24 | Manus 重写 5 次 harness,LangChain 重构 4 次 Deep Research | Aakash Gupta,Medium,2026.1 | §3.1 | 工程积累是真实的,但不等于结构性壁垒 |
| 25 | LangChain 实测:模型不变,调整 Harness 得分 52.8% → 66.5% | LangChain Blog,Improving Deep Agents with Harness Engineering | §3.1 | Harness 工程确实带来显著效果提升 |
| 26 | METR / Scale AI SWE-Atlas 评测:Opus 4.6 仅高出通用 SWE-Agent 2.5pp | Latent Space,Is Harness Engineering Real?,2026.3 | §3.2 | 顶级 harness 之间的效果差距在收窄 |
| 27 | GPT 5.2 在通用 scaffold 中反而表现更好 | Scale Labs,SWE-Atlas Leaderboard | §3.2 | 模型越强,专用 harness 的增量优势越小 |
| 28 | METR 研究:通过 benchmark 的 PR 约半数被维护者拒绝合并 | METR,2026.3 | §3.2 | Benchmark 得分与实际质量存在系统性落差 |
| 29 | Noam Brown:"推理模型出来后大量 scaffolding 直接没用了" | Latent Space Podcast,Noam Brown | §3.2 | 模型能力内化会吞噬 harness 的编排逻辑 |
| 30 | Skills 从 Anthropic 扩散到 Codex / OpenCode | HumanLayer Blog,2026.3 | §3.3 | 开源社区复制速度极快;方法论不构成壁垒 |
| 31 | Sora 月下载量从 320 万峰值跌至 120 万后关停 | Appfigures Intelligence / ContentGrip | §4.3 | 独立产品形态在时间窗口型赛道上不可持续 |
| 32 | Fidji Simo:"不能被支线任务分心" | The Rundown AI,2026.3 | §4.3 | 平台思维优于产品思维 |
| 33 | Anthropic 将 Claude Code 定位为持续演进的 harness 而非独立产品线 | Anthropic,Building Effective Agents | §4.3 | "可组合、可拆卸"形态适配时间窗口型赛道 |
| 34 | Harness = OS 类比(Model=CPU, Context Window=RAM, Harness=OS) | Philipp Schmid,The Importance of Agent Harness in 2026 | §4.3 | Harness 正从运行环境升维为 AI 能力的通用抽象层 |
| 35 | OpenAI 将 ChatGPT / Codex / Atlas 合并为统一平台 | Decrypt / WSJ,2026.3 | §4.4 | 系统级集成 + 模型-Harness 协同训练的平台策略 |
推荐学习书籍 《CDA一级教材》适合CDA一级考生备考,也适合业务及数据分析岗位的从业者提升自我。完整电子版已上线CDA网校,累计已有10万+在读~ !





 京公网安备 11010802022788号
京公网安备 11010802022788号







