


 雷达卡
雷达卡
















With the advent of new technologies, there has been an increase in the number of data sources. Web server logs, machine log files, user activity on social media, recording a user’s clicks on the website and many other data sources have caused an exponential growth of data. Individually this content may not be very large, but when taken across billions of users, it produces terabytes or petabytes of data. For example, Facebook is collecting 500 terabytes(TB) of data everyday with more than 950 million users. Such a massive amount of data which is not only structured but also unstructured and semi-structured is considered under the roof known as Big Data.
Big data is of more importance today, because in past we collected a lot of data and built models to predict the future, called forecasting, but now we collect data and build models to predict what is happening now, called nowcasting. So a phenomenal amount of data is collected, but only a tiny amount is ever analysed. The termData Science means deriving knowledge from big data, efficiently and intelligently.
The common tasks involved in data science are :
- Dig data to find useful data to analyse
- Clean and prepare that data
- Define a model
- Evaluate the model
- Repeat until we get statistically good results, and hence a good model
- Use this model for large scale data processing
MapReduce, the parallel data processing paradigm, greatly simplified the analysis of big data using large clusters of commodity hardware. But as big data got bigger, people wanted to mainly perform 2 types of tasks over it –
- More complex, multi-stage applications, like the iterative machine learning and graph algorithms
- More interactive ad-hoc queries
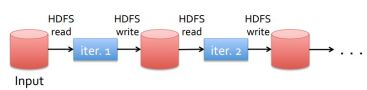
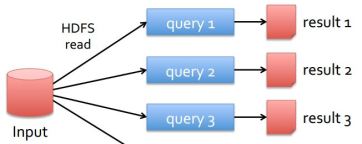
MapReduce is not good at either of them because they both need efficient mechanisms to share data between the multiple map-reduce stages. In map-reduce, the only way to share data across different stages is the distributed data storage which is very slow as it involves disk operations and data replication across the cluster. So in map-reduce, each step that we perform passes through the disk. The mappers reads data from the disk, processes it, and writes it back to the disk before shuffle operation. This data is then replicated across the cluster in order to provide fault tolerance. The reducers then read this data from the disk, processes it and writes it back to the disk. For iterative jobs, multiple map-reduce operations needs to be performed sequentially, which involves a very high disk I/O and high latency making them too slow. Similarly, for interactive queries, data is read from the disk each time the query is executed.
Apache Spark
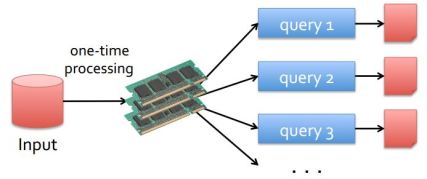
 Apache Spark is an open source big data processing framework built to overcome the limitations from the traditional map-reduce solution. The main idea behind Spark is to provide a memory abstraction which allows us to efficiently share data across the different stages of a map-reduce job or provide in-memory data sharing.
Apache Spark is an open source big data processing framework built to overcome the limitations from the traditional map-reduce solution. The main idea behind Spark is to provide a memory abstraction which allows us to efficiently share data across the different stages of a map-reduce job or provide in-memory data sharing.

At a high level, every Spark application consists of a driver programthat runs the user’s main function and executes various parallel operations on the worker or processing nodes of the cluster. The main memory abstraction that Spark provides is of a Resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs can be created from a file in the file system, or an existing collection in the driver program, and transforming it. So as the name suggests, the data from a file in the file system or from an existing collection in the driver program that forms a RDD is partitioned and distributed across the worker or processing nodes in the cluster, thereby forming a distributed dataset.
The important point to remember is that RDDs are immutable distributed datasets across the cluster and are generated using the coarse grained operations i.e operations applied to the entire dataset at once. We can persist an RDD in-memory, allowing it to be reused efficiently across parallel operations or different stages of a map-reduce job. So the reason why Spark works so well for iterative machine learning algorithms and interactive queries is that, instead of sharing data across different stages of the job by writing it to the disk (which involves disk I/O and replication across nodes) it caches the data to be shared in-memory which allows faster access to the same data.
For fault tolerance, Spark automatically records how the RDD is created i.e the series of transformations applied to the base RDD to form a new RDD. So when the data is lost, it reapplies the steps from transformations graph to rebuilt the RDD or lost data. Generally, only a piece of data is lost when a machine fails, and so RDD tracks the transformations at machine level and recomputes only the required operations or a part of transformations on the previous data to perform recovery.
Spark Ecosystem

Apache Spark takes map-reduce to the next level with it’s capabilities like in-memory data storage and near real-time data processing. In addition to the core APIs, Spark has additional libraries integrated into it to support a variety of data analysis and machine learning algorithms.
1) GraphX – Graph computation engine which supports complex graph processing algorithms efficiently and with improved performance. PageRank Algorithm – a popular graph processing algorithm outperforms in Apache Spark environment over map-reduce.
2) MLLib – Machine learning library built on the top of Spark and supports many complex machine learning algorithms which runs 100x faster than map-reduce.
3) Spark Streaming – Supports analytical and interactive applications built on live streaming data.
4) Shark (SQL) – Used for querying structured data. Spark SQL allows the users to ETL their data from its current format (like JSON, Parquet, a Database), transform it, and expose it for ad-hoc querying.
This was a brief overview of Apache Spark, in future articles, we will dive deep into its concepts and programming model.


 京公网安备 11010802022788号
京公网安备 11010802022788号







