


 雷达卡
雷达卡





数据科学(Python/R/Julia)数据分析、机器学习、深度学习
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中,Java中其实提供了很多并发处理相关的API,但是这些API在分布式场景中就无能为力了。也就是说单纯的Java Api并不能提供分布式锁的能力。所以针对分布式锁的实现目前有多种方案。
针对分布式锁的实现,目前比较常用的有以下几种方案:
基于数据库实现分布式锁
基于缓存实现分布式锁
基于Zookeeper实现分布式锁
在分析这几种实现方案之前我们先来想一下,我们需要的分布式锁应该是怎么样的?(这里以方法锁为例,资源锁同理)
可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
这把锁要是一把可重入锁(避免死锁)
这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
有高可用的获取锁和释放锁功能
获取锁和释放锁的性能要好
基于数据库实现分布式锁
基于数据库表
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
创建这样一张数据库表:

当我们想要锁住某个方法时,执行以下SQL:
因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
当方法执行完毕之后,想要释放锁的话,需要执行以下Sql:
上面这种简单的实现有以下几个问题:
1、这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
2、这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
3、这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
4、这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。当然,我们也可以有其他方式解决上面的问题。
数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
非阻塞的?搞一个while循环,直到insert成功再返回成功。
非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
基于数据库排他锁
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
我们还用刚刚创建的那张数据库表。可以通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:
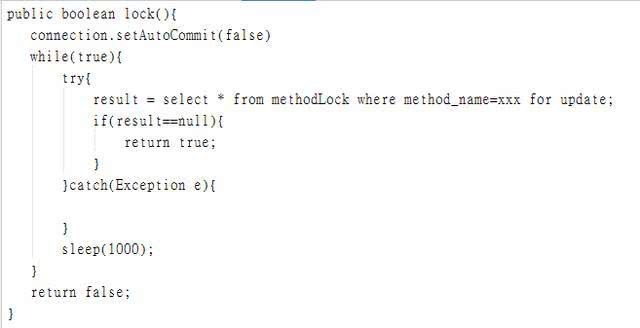
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。)。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:

通过connection.commit操作来释放锁。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
阻塞锁? for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。
锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
但是还是无法直接解决数据库单点和可重入问题。
这里还可能存在另外一个问题,虽然我们对method_name 使用了唯一索引,并且显示使用for update来使用行级锁。但是,MySql会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。如果发生这种情况就悲剧了。。。
还有一个问题,就是我们要使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆
总结
总结一下使用数据库来实现分布式锁的方式,这两种方式都是依赖数据库的一张表,一种是通过表中的记录的存在情况确定当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。
数据库实现分布式锁的优点
直接借助数据库,容易理解。

关注“AIU人工智能”公众号,回复“白皮书”获取数据分析、大数据、人工智能行业白皮书及更多精选学习资料!



 京公网安备 11010802022788号
京公网安备 11010802022788号







