


 雷达卡
雷达卡





数据科学(Python/R/Julia)数据分析、机器学习、深度学习
在数据挖掘项目中有将近60%的时间和精力都是用在熟悉、清洗、转换数据的,下面我们将对数据预处理中一些普遍和重要的方法和技巧进行介绍。
数据的规模
数据的规模是指用于数据挖掘建模是最起码的数据量大小。重点考量的是目标变量多对应的目标事件的数量。

建模过程中通常要将样本划分成3个子集:训练集、验证集、测试集(样本数量太小时也可以划分成训练集和测试集)。通常训练集中数据要占样本总量的40%~70%,而训练集中目标事件的数量至少要有1000个。当然这是指理想情况下,在项目中还是要根据分析师的经验和业务场景进行权衡。
预测模型的输入变量最好控制在8~20个之间,输入变量太少则当变量缺失和误差时模型结果变化显著,稳定性较差;太多则会使模型过于复杂。
训练集样本规模一般应在输入变量数量的10倍以上,且被预测的目标事件的数量至少是输入变量数目的6~8倍。
数据抽样
适用场景:
当数据全集规模过大,针对数据全集进行分析运算会消耗过多的运算资源和运算分析时间,甚至会导致数据挖掘软件崩溃。
在很多小概率事件和稀有事件的建模过程中,按原始的数据全集、原始的稀有占比来分析,是很难得到有意义的预测和结论的。通过抽样可以人为的增加样本中稀有事件的浓度。
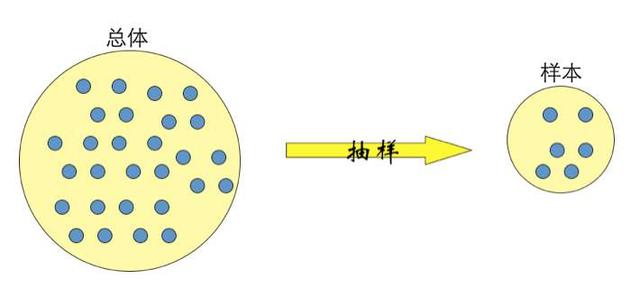
抽样注意事项:
样本中输入变量的值域和分布要与数据全集中输入变量的值域和分布保持一致(连续型变量和类别型变量都是如此),或者说至少要高度相似;
样本中目标变量的值域和分布要与数据全集中目标变量的值域和分布保持一致,或者说至少要高度相似;
样本中缺失值的分布要与数据全集中缺失值的分布保持一致,或者说至少要高度相似;
对稀有事件进行抽样时,为保持目标变量分布一致,要使用加权的方法恢复新样本对数据全集的代表性。
缺失值处理
1.分析数据缺失的原因,进而确定有效的处理方法
数据确实是录入时丢失或未录入;
具有特定商业意义的数据缺失,如信用卡的激活日期,未激活的会记录为null;
系统本身的计算逻辑错误,如对负数取对数。
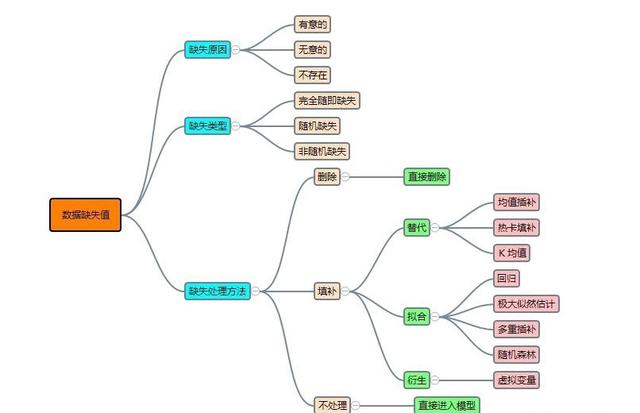
2.选择合适的方法处理缺失值
直接删除带有缺失值的样本。适用于样本中缺失值比例很少,且在后期应用中数据的缺失值也很少的情况;
直接删除有大量缺失值的变量。适用于缺失值占比超过相当比例的变量;
对缺失值进行替换。利用全集中的代表性属性(如变量的众数、均值、中间值等)进行填充;
对缺失值进行赋值。通过如回归模型、决策树模型、贝叶斯定理去预测缺失值的最近替换值。最严谨的方法,但成本较高。
异常值处理
数据样本中的异常值通常指一个类别型变量里某个类别值出现的次数太少、太稀有或者区间型变量里某些取值太大。
1.根据业务场景分析是否真的是异常值
类别型变量:根据业务场景判断异常值是否和目标变量中的目标事件时正相关关系。如果不是则可以删除。
区间型变量:用标准差来衡量,把超过均值n个标准差以上的取值定义为异常值,n的取值取决于具体业务场景和不同变量的合理分布。
2.直接删除异常值对应的观察样本
数据转换
数据转换后模型的效果常常有显著的提升。
1.生成新的衍生变量
通过对原始数据进行简单、适当的数学推,产生更加有意义的新变量。常见的如月均XXX、年均XXX、比例、人均XXX等。
2.改善变量的分布
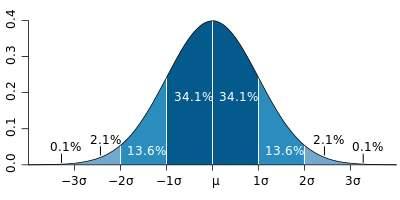
通过各种数学转换使输入变量的分布呈现正态分布。
常见做法:取对数、开平方根、取倒数、开平方、取指数等。
3.分箱转换

把区间型变量转换为次序型变量。主要目的如下:降低变量的复杂性、简化数据;提升变量的预测能力,分箱恰当可以提升自变量和因变量的相关性。
4.数据标准化
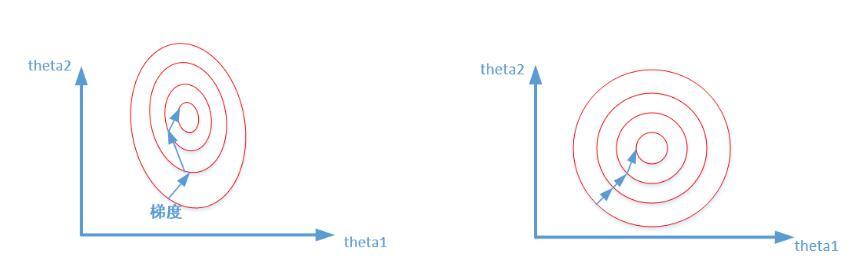
将数据按照比例进行缩放,使数据落入一个更小的区间范围,使变量拥有平等的权重。
最简单的数据标准化方法是Min-Max标准化(离差标准化),是对原始数据进行线性转化,使之落入[0,1]的区间内。公式为:x*=(x-min)/(max-min)。

关注“AIU人工智能”公众号,回复“白皮书”获取数据分析、大数据、人工智能行业白皮书及更多精选学习资料!

 京公网安备 11010802022788号
京公网安备 11010802022788号







