


 雷达卡
雷达卡




在之前的TBQuant数据处理探索——后复权详解(上)一文中,我们介绍了主力连续888的缺陷主要是由于换月时强行切换合约数据,其价格之间由于时间价值而存在较大差值。这个差值主要会导致两个问题:
一、对于大部分趋势策略来说,换月的大跳空基本意味着出现交易信号,然而这个信号通常情况下都是无效的。
二、对于大部分指标来说,由于都需要计算过去一段时间的k线数据,导致换月以后用于计算的数据出错。

上图即为换月时导致kdj指标产生异动。
导致这两个问题的核心原因其实是因为前后价格差太大。那么如果能把前后的价格差抹平,这两个问题自然会迎刃而解。
如何抹平价格差?股票市场提供了一个很好的思路。股票常见高送转等操作,股价往往要重新计算,这个重新计算被称为复权。同样的思路我们也可以应用到期货里。
复权有多种方法,从计算对象来分有前复权和后复权,从计算方式来分有差值复权和比值复权。那么适用于888的复权方法是哪种呢?
首先来看计算对象,这里指的是价格数据。作为复权对象的价格数据,在某个时间点前后被分成相差较大的两部分。

上图很明显在左右两边的数据中间存在跳空节点。为了将两边的数据连接起来,我们要么把左边的数据往下移,要么把右边的数据往上移。
如果是把左边的数据往下移,就被称为前复权,也就是对前面的数据进行修复处理。如果是把右边的数据向上移,那就被称为后复权,也就是对后面的数据进行修复处理。两种复权方式使用起来实际效果是一样的。
由于程序化模型的运行机制是从左到右运行,那么前复权会导致历史数据被修改,之前模型留下的信号记录就必须重算,等于说运行到一个复权节点,就要回头把之前的数据重新复权一下再运行计算一遍。这使得模型运行机制变得十分复杂而且低效率。
比较而言,后复权的运行高效很多。前复权一般用于复权次数较少的数据,例如股票的高送转一般频率不会非常高,而期货换月一年三次,明显不适合前复权。
其次,我们看看差值复权和比值复权。差值复权顾名思义,将节点前后的数字取一个差值,然后将需要复权的数据统一加减这个数值。以后复权为例,假使节点前价格为2500,节点后的价格为3000,那么差值为3000-2500=500,我们对后面的数据做如下处理:
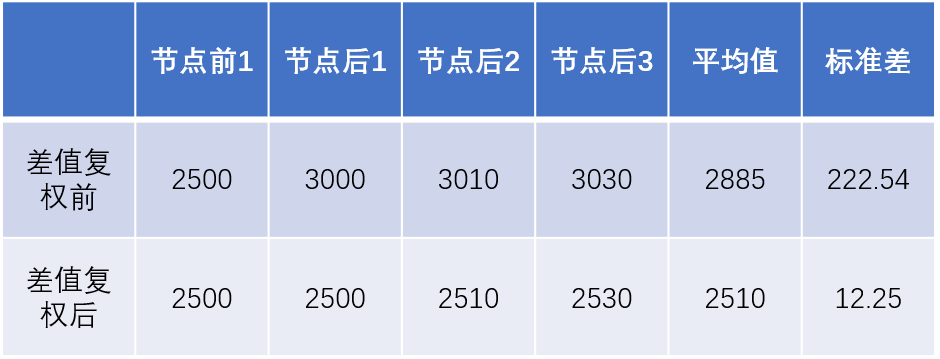
标准差是用来描述一组数组的离散程度的指标。如果一组数据比较连续,互相之间差别很小,那么标准差也会较小,接近于0。相反,如果一组数据彼此之间跳空很明显,那么标准差就会偏大。
从上表来看,差值复权前,节点前后数据的标准差高于差值复权后接近20倍,说明复权确实很大程度降低了数据跳空情况,
但是差值复权对于期货品种来说却有致命的缺陷,那就是期货品种都有较为固定的基差,对于正向市场的连续差值复权会导致最后的价格变成负值。
例如,在第一次换月时:

在第二次换月时,02合约价格从第一次换月时的价格1200下跌至950:

第三次换月时,03合约价格从第二次换月时的价格1200下跌至1050:

三次换月处理时,次主力合约价格都是1200,但是差值复权以后,价格从1000降低至750及600,长此以往,复权价格就会降至负值,这样会对测试报告和后期计算带来很多困难。而比值复权不存在复权后价格降至负值的情况。
根据上文总结,商品能选择的最佳复权方案,只能是向后比值复权。

 京公网安备 11010802022788号
京公网安备 11010802022788号







