


 雷达卡
雷达卡



第7步:使用带有属性X_test的.predict()方法来确定最终结果
# Predicting the Test set results
y_pred = model.predict(X_test)
y_pred

注意:随机森林的准确度为72%。(在进行不同测试尺寸的实验时可能会有所不同,此处= 0.25)。
步骤8:要知道准确性,需要混淆矩阵。混淆矩阵是一个2X2矩阵。
注意:True或False指的是指定的分类是正确的还是不正确的,而正面或负面指的是指定为正面或负面类别
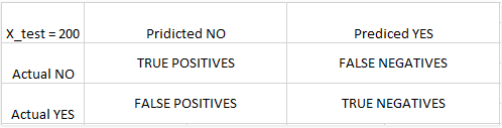
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
cm


 京公网安备 11010802022788号
京公网安备 11010802022788号







