



 雷达卡
雷达卡





今天给大家带来脚本是缺失值处理的。为什么说这一块呢?因为我经常看到大家在用excel对缺失值进行插补,这种也是一个很好的方法,但是比较耗费时间,换句话来说性价比极低。有没有好办法呢,答案是肯定有!!
python的Numpy库中pd.fillna函数就可以搞定,语言非常简洁、方便!看到这里你是不是突然紧张一下,这一期不会是上python教程吧。哈哈哈,我个人不是特别喜欢python的语法,所以也只是在上机器学习中上python(因为python跑的更快一些),所以这一期咱们还是用R。说到缺失值,不得不提缺失值的类型,随机缺失(MAR,Missing at Random)、完全随机缺失(MCAR,Missing Completely at Random)、非随机缺失(MNAR,Missing not at Random),因为每一种缺失类型对应着不同的填补方法,一般情况下缺失数据属于随机缺失、完全随机缺失,也只有这两种类型的据能够填补,至于自己数据属于哪一类网上很多教程,本文不再阐述啦。因为我赶着打酱油去。
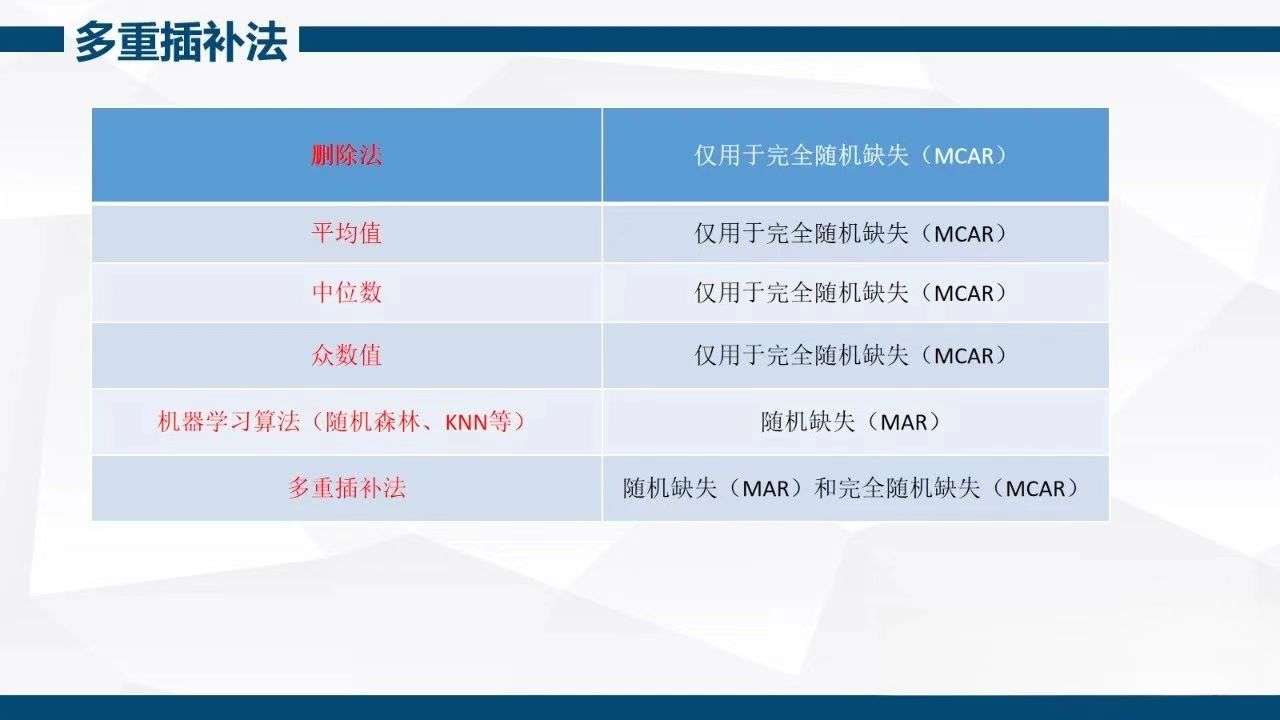
在R语言中,据我所知好像没有包可以快速帮我们去填补一些缺失数据(当然一些基于算法的插补除外),因此对我们来说十分的不便利。基于此,我写了几个小脚本可供大家使用。
二、操作代码1、删除法删除法即个案的所有变量中只要存在缺失值,即将变量进行删除。这个比较简单,R里面有函数可以实现。代码如下
- data=read.xlsx("处理后.xlsx")#data为传入的数据new_data=na.omit(data) #删除存在存在缺失值的个案

 京公网安备 11010802022788号
京公网安备 11010802022788号







