


 雷达卡
雷达卡




随着互联网的普及与媒体数字化转型,新闻报道成为社会大众获取信息、了解时事的主要渠道。每天产生的大量新闻文本不仅记录了社会事件的发展轨迹,也反映了公众关注的焦点和舆论走向。如何从这些海量文本中提炼出有价值的结构化信息,已成为新闻传播学、社会科学以及自然语言处理等领域的重要研究问题。
传统的人工分析方式难以应对大规模新闻数据,因此需要借助自动化的文本挖掘与建模方法。本研究基于新闻语料(光明日报、人民日报2024~2025年每日新闻文本,以及新闻联播2006~2024年的新闻文本),采用主题建模(Topic Modeling) 的思路,通过 潜在狄利克雷分配(LDA, Latent Dirichlet Allocation) 模型对新闻文本进行无监督学习,识别其中潜在的主题分布与关键词特征。并且预设了八大方向(经济、科技、民生、环保、外交、教育、医疗、安全),对每篇新闻文本输出概率最大的五个主题和适配的方向词。希望能为后续研究(政策研究、社会热点监测、媒体报道风格分析等方向)提供数据支持。
| 数据来源 | 数据来源于新闻报道 |
| 时间跨度 | 2006~2025 |
| 区域跨度 | 光明日报、人民日报、新闻联播 |
| 数据格式 | xlsx |
数据指标
date | newspaper | topic1_id | topic1_name | probability1 | topic2_id |
topic2_name | probability2 | topic3_id | topic3_name | probability3 | topic4_id |
topic4_name | probability4 | topic5_id | topic5_name | probability5 | max_topic_id |
max_topic_name | max_topic_keywords | max_probability | final_direction |
|
|
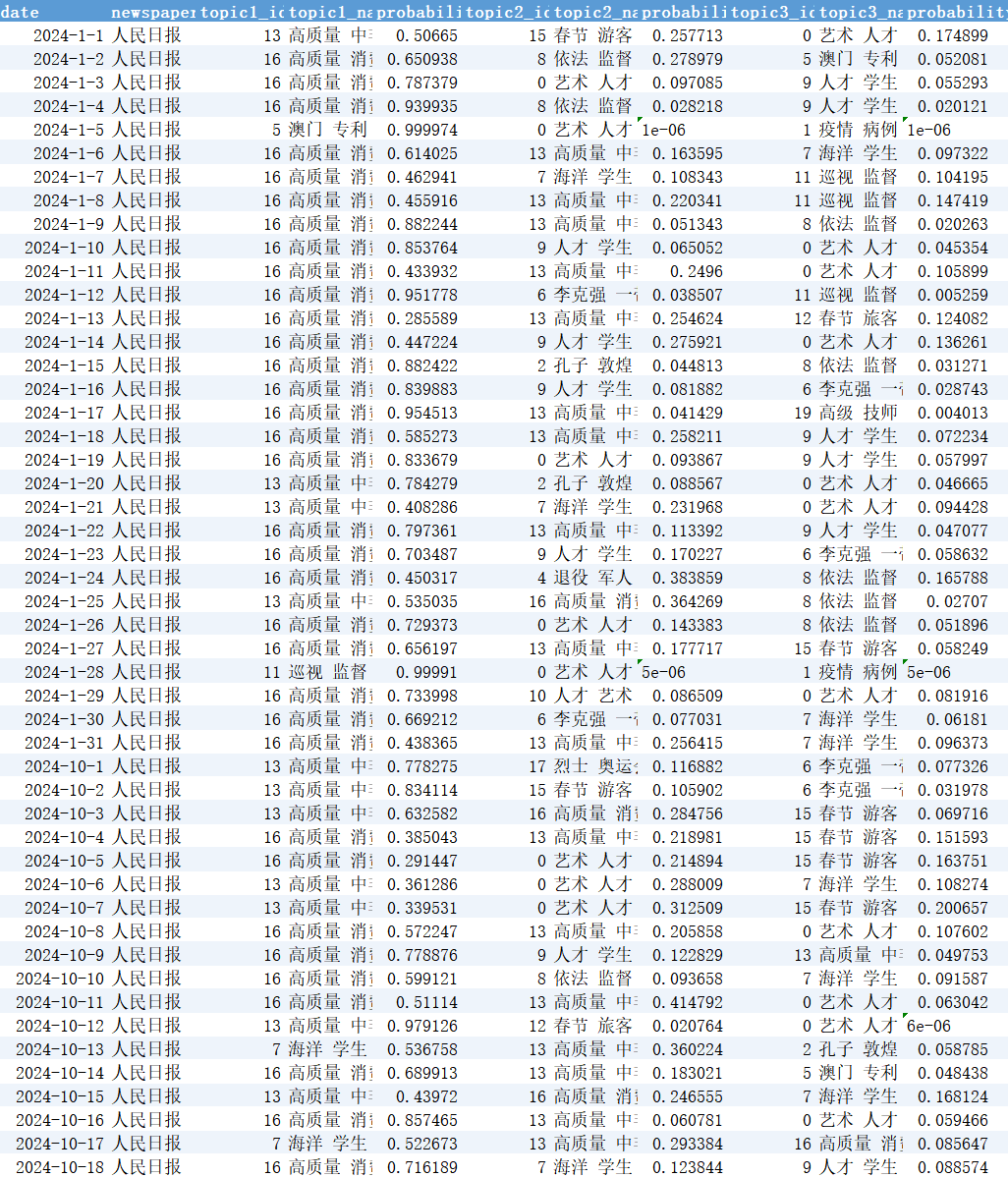
数据展示
参考文献
方匡南,戴明晓,郑挺国,等。国家治理政府注意力指数构建及其应用 —— 基于新闻文本的测度 [J]. 统计研究,2025,42 (03):131-145.
 新闻文本主题关键词提取.zip
(450.87 KB, 需要: RMB 28 元)
新闻文本主题关键词提取.zip
(450.87 KB, 需要: RMB 28 元)

 京公网安备 11010802022788号
京公网安备 11010802022788号







