


 雷达卡
雷达卡



随机森林RF程序(MATLAB),应对分类或回归任务。
有示例,容易上手,只需更换数据即可确保正常运行。
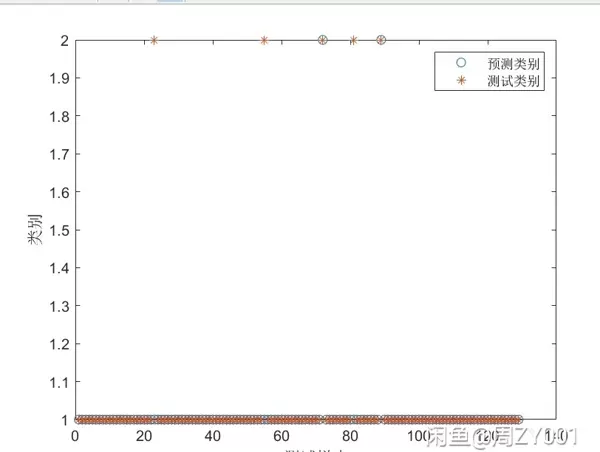
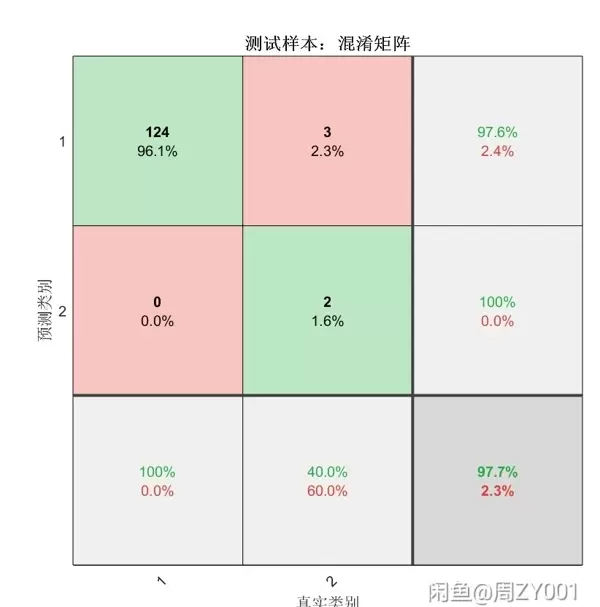
在机器学习的领域里,随机森林(Random Forest,简称RF)是一个强大的工具,它既能处理分类问题,也能解决回归问题,并且操作简便。今天我们就用MATLAB实现一个随机森林程序,并提供示例,你只需替换数据即可直接使用,确保顺利运行!
随机森林概述
随机森林是一种集成学习方法,由多个决策树组成。简而言之,就像一群小专家(决策树)通过投票或平均值来做出判断。在分类任务中,每个决策树会对样本进行分类,最终通过多数表决确定类别;而在回归任务中,各个决策树会提供预测值,然后取平均作为最终结果。
MATLAB实现随机森林程序
代码示例
以下是一个完整的MATLAB随机森林代码示例,首先处理分类问题,接着再看回归问题。
% 加载数据集,这里以鸢尾花数据集为例
load fisheriris
X = meas; % 特征矩阵
Y = species; % 标签向量
% 划分训练集和测试集
cv = cvpartition(Y,'HoldOut',0.3); % 70%训练,30%测试
idxTrain = training(cv);
idxTest = test(cv);
XTrain = X(idxTrain,:);
YTrain = Y(idxTrain);
XTest = X(idxTest,:);
YTest = Y(idxTest);
% 创建随机森林分类器
numTrees = 100; % 决策树的数量
rf = TreeBagger(numTrees,XTrain,YTrain,'Method','classification');
% 进行预测
YPred = predict(rf,XTest);
% 计算分类准确率
accuracy = sum(strcmp(YPred,YTest))/numel(YTest);
fprintf('分类准确率: %.2f%%\n', accuracy * 100);代码分析
数据加载与准备
我们使用了MATLAB自带的鸢尾花数据集,
meas是特征矩阵,
species是标签向量。然后用
cvpartition函数将数据集分为训练集和测试集,这里70%的数据用于训练,30%用于测试。
随机森林分类器创建
使用
TreeBagger函数创建随机森林分类器,
numTrees表示决策树的数量,这里设置为100。
'Method'参数设为
'classification'表示我们处理的是分类问题。
预测与准确率计算
使用
predict函数对测试集进行预测,然后通过比较预测结果和实际标签来计算分类的准确率。
回归问题示例
以下是一个处理回归问题的代码示例:
% 加载房价数据集,这里假设已经有一个包含房价数据的文件
load housingData.mat % 替换为实际的房价数据集文件
X = housingData(:,1:end-1); % 特征矩阵
Y = housingData(:,end); % 房价标签
% 划分训练集和测试集
cv = cvpartition(Y,'HoldOut',0.3);
idxTrain = training(cv);
idxTest = test(cv);
XTrain = X(idxTrain,:);
YTrain = Y(idxTrain);
XTest = X(idxTest,:);
YTest = Y(idxTest);
% 创建随机森林回归器
numTrees = 100;
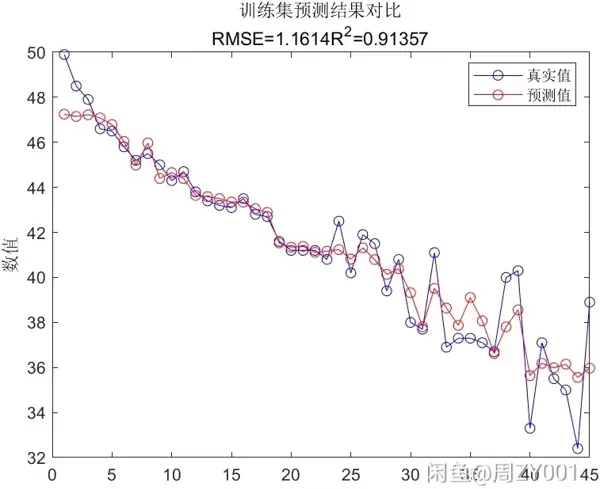
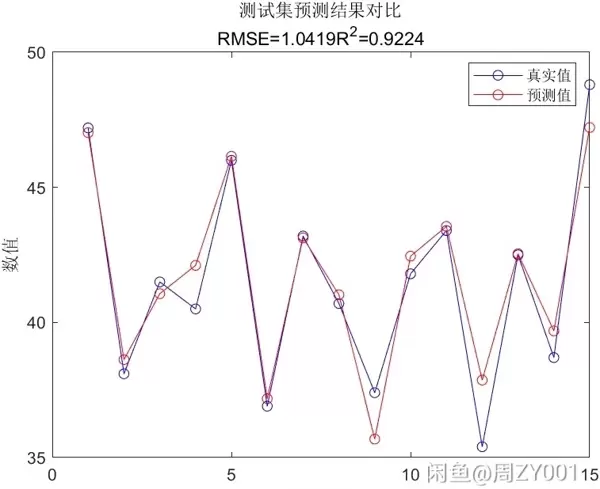
rf = TreeBagger(numTrees,XTrain,YTrain,'Method','regression');
% 进行预测
YPred = predict(rf,XTest);
% 计算均方误差
mse = mean((str2double(YPred) - YTest).^2);
fprintf('均方误差: %.2f\n', mse);代码分析
数据加载与准备
加载房价数据集,分离特征和标签,并同样划分训练集和测试集。
随机森林回归器创建
使用
TreeBagger函数,
'Method'参数设置为
'regression'表示处理回归问题。
预测与均方误差计算
对测试集进行预测,然后计算预测值和实际值之间的均方误差。
总结
通过上述代码示例,我们可以看到用MATLAB实现随机森林解决分类和回归问题非常便捷。你只需替换数据即可直接运行代码。随机森林是一个强大且稳定的机器学习算法,在许多实际应用中表现出色。赶快试试吧!

 京公网安备 11010802022788号
京公网安备 11010802022788号







