


 雷达卡
雷达卡



目录
一、如何用ETL进行数据治理?
两年前,我在的数据团队每天面对海量信息,总是抱怨:
想要制定决策调整时,结果部门报表中的数字前后不一致;想整合一份完整的用户视图,就需要手动对接各个团队,耗时费力;数据在流转过程中缺乏有效管控,既担心泄露风险,又怕触碰合规红线......
这些问题的根源,往往在于缺少一套行之有效的数据治理体系。而ETL正是破解这些难题最直接的技术手段。
那么关键是如何操作呢?本文就直接上干货,不讲虚的,手把手教你如何用ETL进行数据治理;如何用增量抽取技术提升数据处理效率;以及在实践过程中必须掌握的避坑指南。
1. ETL与数据治理
ETL,即提取、转换、加载,它不仅仅是简单的数据搬运。
而数据治理是一整套确保生产的数据质量可靠、标签清晰、来源可追溯、使用安全规范的管理体系和方法论。
现在你发现了吗?ETL是实现数据治理目标最核心、最实用的技术手段。没有ETL这个过程,数据治理的各种规范和蓝图就成了空中楼阁。
2. 数据标准与质量
在转换阶段,我们清洗数据中的脏数据、验证数据的有效性、进行数据补全。
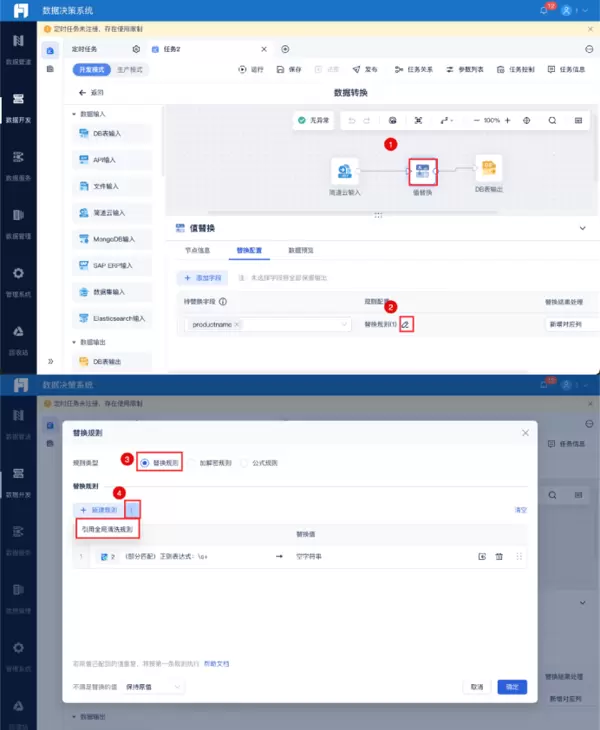
数据清洗的关键在于使用一个好的数据集成工具来进行。例如我工作常用的FineDataLink,在清洗规则上可以设置条件进行全局清洗,通过点击就能获得可靠有用的数据。非常简单方便,初学者也能快速上手。工具体验地址:
https://s.fanruan.com/8hhzn(复制到浏览器打开)
3. 数据模型与集成
我们将来自不同业务系统的数据,在ETL过程中按照设计好的数据模型进行整合、关联。这就是构建数据治理中强调的统一、一致的数据视图。
4. 数据安全与隐私
在ETL的提取和转换阶段,我们可以对敏感数据进行脱敏处理。这直接体现了数据治理中的安全合规原则。
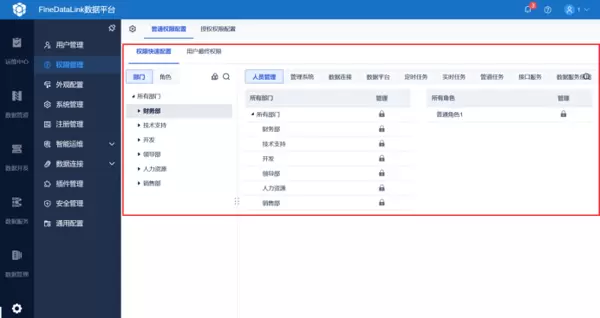
在FineDataLink里还可以通过权限管理对部门或者员工进行授权管理,哪一个环节出了问题就能快速找到相关负责人。
5. 数据血缘
一套好的ETL流程会记录数据的来源、经过了哪些处理、最终流向何处。这为数据治理中的血缘追溯、影响分析提供了最直接的依据。
所以,我一直强调,在进行ETL时,心中必须装着数据治理的标准。你不是在简单地完成任务,而是在为整个企业的数据大厦打下坚实的基础:每一次认真的清洗、转换,都是为后续的数据分析、决策支持奠定可靠的基础。
二、如何进行ETL增量抽取
理解了ETL和数据治理是如何协同工作之后,我们接下来必然会遇到一个非常实际的问题:效率。
想象一下,你负责的报表源表每天会产生上百万条新数据。如果第一天全量抽取花费3个小时。第二天,难道你还要再把整张表,包括已经抽过的和新增的,再次花3个小时搬一遍吗?这无疑是巨大的资源浪费!
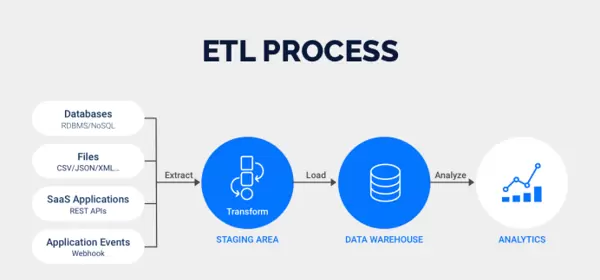
增量抽取,就是只抽取自上次抽取以后,数据库中新增、修改或删除的数据。它是一种极其高效的方式,能大幅减少数据处理量,降低对源系统的压力,并提升整个ETL流程的时效性。
用过来人的经验告诉你,掌握不了增量抽取,你的ETL管道迟早会面临性能瓶颈。
那么,具体如何实现呢?这里我给大家列了表格,可以对照来看:
| 抽取方式 | 原理 | 操作步骤 | 优点 | 缺点 |
|---|---|---|---|---|
| 基于时间戳的增量抽取 | 源表包含新增/修改时间字段,记录上次最大抽取时间点,下次仅抽大于该时间点的数据 | 1. 目标端维护日志表记录 last_max_timestamp;2. 任务启动时获取该时间戳;3. 构建查询语句;4. 抽取完成后更新日志表 | 1. 实现简单;2. 对源系统影响小 | 1. 无法捕获删除操作;2. 依赖时间戳字段的准确性和完整性;3. 时间戳字段需有索引,否则大数据量下查询性能差 |
| 基于增量日志表 | 源库通过数据库机制或业务系统,将所有数据变更记录到单独的增量日志表,ETL 定期扫描该表 | 1. 源数据库创建触发器,源表发生 INSERT/UPDATE/DELETE 时,将变更数据写入 change_log_table;2. ETL 抽取该表中未处理记录;3. 按操作类型在目标端执行合并或删除操作 | 1. 100% 捕获所有数据变更;2. 对源表查询无性能压力 | 1. 对源系统有侵入性,触发器消耗源库性能;2. 需源数据库支持和权限;3. 增加源系统数据库复杂度 |
| 基于数据库日志解析 | 直接解析数据库二进制日志,通过日志还原数据每一步变化 | 使用 Canal、Debezium 等工具,模拟从库读取 Binlog,解析为结构化数据变更事件,发送到消息队列供下游 ETL 处理 | 1. 近乎实时;2. 对源数据库完全无侵入;3. 完整捕获所有变更 | 1. 技术复杂度最高,需搭建维护独立组件;2. 需深入了解数据库日志格式;3. 配置和管理成本高 |
三、增量抽取的“避坑指南”
- 数据一致性与完整性
- 对源系统的影响必须评估
- 变化数据的处理
- 监控预警体系
- 处理数据结构变更
总结
通过本文,我们不仅了解了如何用ETL进行数据治理,还学习了如何利用增量抽取技术提升数据处理效率。希望这些内容对你有所帮助。
看到这里,你可能会问,到底该选哪种?实际上, 没有最好的,只有最合适的。 简单来说,如果你们的业务系统不太可能配合你增加触发器,时间戳也不可靠,并且追求实时性,那么投入资源研究日志解析是值得的;如果是传统的T+1离线抽取,基于时间戳或增量表通常是更务实的选择。
三、增量抽取的“避坑指南”
知道了方法不等于就能做好。在增量抽取的实际操作中,有太多细节需要注意,一不小心就会掉进陷阱。
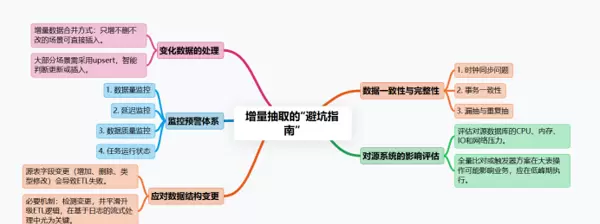
1. 数据一致性与完整性
- 时钟同步问题:如果源系统是分布式的,各台机器的时间可能不一致。你依赖的时间戳可能根本不可靠。务必确保源系统和ETL服务器的时钟同步。
- 事务一致性:一条业务数据可能由多条SQL在一个事务中完成。要确保你抽取到的数据处于一个完整的事务状态。例如,解析Binlog时,要注意事务的提交点,避免读取中间状态。
- 漏抽与重复抽:你的ETL任务必须能够精确记录上一次抽取的“断点”。任务失败重启后,必须能从准确的断点继续,绝不能遗漏,也要避免因重试导致的数据重复。
2. 对源系统的影响必须评估
无论你采用哪种方式,都要 评估对源数据库的CPU、内存、IO和网络带来的压力。 特别是全量比对或者基于触发器的方案,在大表上操作可能直接拖垮业务数据库。尽量在业务低谷期执行。
3. 变化数据的处理
增量数据抽取过来后,如何与目标表的数据合并?简单插入只适用于只有新增的情况。大部分情况下,你需要使用upsert操作,来智能地判断是更新已有记录还是插入新记录。
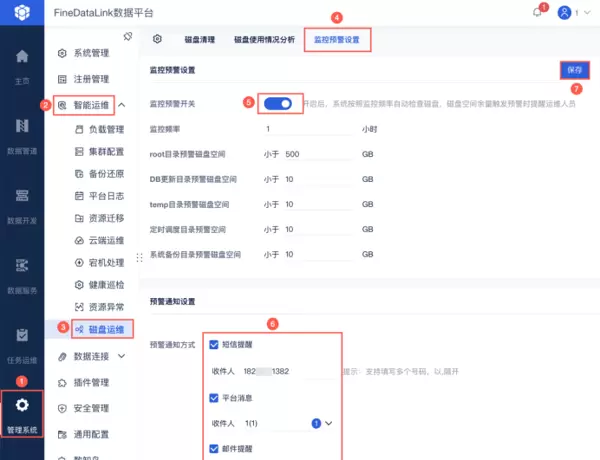
4. 监控预警体系
你必须为增量任务设置完善的监控。
- 数据量监控:本次抽取的数据量是否在合理范围内?突然暴增或暴跌都意味着可能出了问题。
- 延迟监控:数据从产生到进入数据仓库的延迟是多少?是否在SLA要求内?
- 数据质量监控:抽查一些数据,与源系统进行比对,确保没有失真。
- 任务运行状态监控:任务成功了吗?运行了多久?
5. 处理数据结构变更
这是另一个重大挑战。 如果源表增加了字段、删除了字段或者修改了字段类型,你的ETL任务会立即失败。 你需要有一套机制来检测和响应这种变更,并平滑地升级你的ETL作业。这在基于日志解析的流式处理中尤为关键。
总结
ETL和数据治理是相辅相成的; 而 增量抽取,是ETL走向成熟和高效的必经之路。 从选择合适的增量策略开始,到小心谨慎地处理数据一致性,再到建立无死角的监控体系,每一步都需要我们周密的思考和细致的操作。 我一直强调, 数据工作是一项关于信任的工作。 当你提供的报表和数据成为决策依据时,你交付的不仅仅是一串数字,更是一份沉甸甸的责任。你说是不是?

 京公网安备 11010802022788号
京公网安备 11010802022788号







