


 雷达卡
雷达卡



大A已超过4000点,现在来看看“股票研究报告(ERR)自动生成”的输入输出如下:
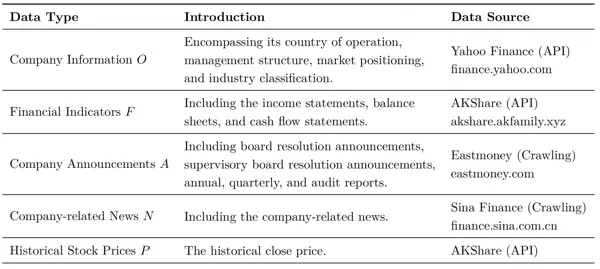
输入:提供公司股票代码(s)和研究日期(t),自动收集6类结构化/非结构化数据,形成输入集合S=[O, F, A, N, P, M]
- O:公司基本信息(例如行业分类、市场定位)
- F:财务指标(包括利润表、资产负债表、现金流量表)
- A:公司公告(例如董事会决议、季度报告等)
- N:公司相关新闻(经过筛选去除重复)
- P:历史股价数据
- M:市场指数(例如沪深300)
输出:符合行业标准的ERR报告,包含6个主要部分:财务分析(R_fin)、新闻分析(R_news)、经营发展分析(R_manage)、风险分析(R_risk)、投资潜力评估(R_invest)、推荐评级(R_rec,买入/卖出)
方法涵盖数据集构建、多智能体框架设计、模型训练优化三个主要部分,接下来详细看看实现。
数据集构建-FinRpt数据集
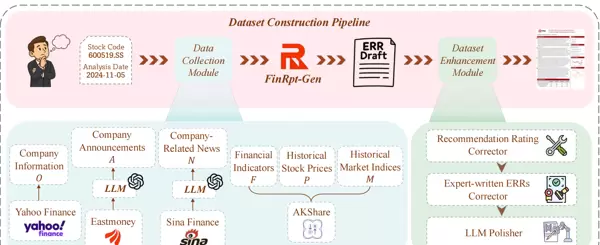
为了支持模型训练和评估,论文设计了自动化数据集构建流程,主要包括3个步骤:
- 数据收集模块
数据来源:
范围:沪深800指数的800支股票,2024年9月3日至11月5日(共计10个分析日期,每间隔一周) - 数据筛选与生成
筛选规则:排除缺乏财务指标、新闻数量少于2条、公告摘要少于300字的低质量数据
报告生成:利用FinRpt-Gen框架(最初基于GPT-4o)自动生成ERR,形成原始样本(s, t, S, R) - 数据集增强模块
推荐评级校正:比较生成报告的R_rec与实际股价趋势,不一致时重新生成
专家报告校正:搜索东方财富网的专家报告,使GPT-4o参考这些报告来提高生成报告的准确性、逻辑性和专业风格
LLM润色:通过GPT-4o优化报告的可读性、连贯性和逻辑流畅度
最终数据集:6825条高质量ERR样本(包括中文和英文版本),按9:1:1比例分为训练集(5556)、验证集(617)、测试集(652)
FinRpt-Gen多智能体框架
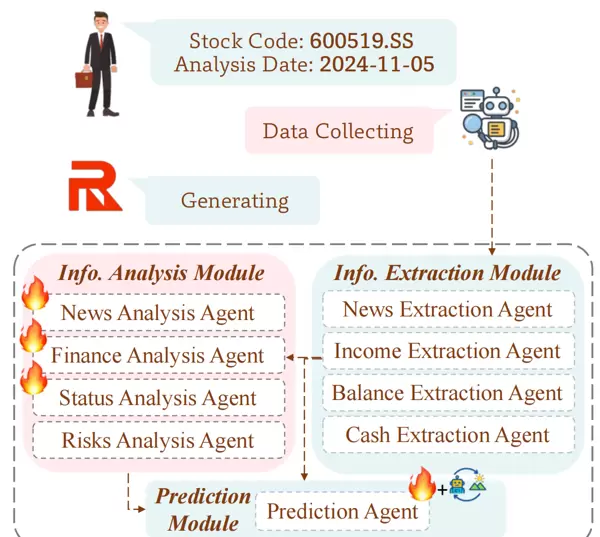
鉴于ERR结构复杂、需要多维度分析的特点,设计了一个包含9个智能体的分层框架,分为3大模块协同工作:
- 信息提取模块(4个智能体):从原始数据中提取关键信息
新闻提取智能体:根据新闻对股价的影响程度排序,选择Top10关键新闻
收入提取智能体:从利润表F中提取营业收入、净利润、每股收益(EPS)等核心指标
资产提取智能体:从资产负债表F中提取资产、负债、所有者权益等关键数据
现金提取智能体:从现金流量表F中提取经营活动、投资活动、筹资活动的现金流 - 分析模块(4个智能体):生成ERR的主要分析部分
财务分析智能体:基于3个财务提取智能体的输出,总结公司的财务健康状况、盈利能力和现金流情况,生成R_fin
新闻分析智能体:基于Top10新闻,分析其对股票未来表现的影响,生成R_news
经营分析智能体:从公司公告A中提炼管理层策略和发展路径,生成R_manage
风险分析智能体:整合财务、新闻、经营分析的结果,识别主要风险(如政策风险、假冒风险),生成R_risk - 预测模块(1个智能体):生成投资建议和评级
预测智能体:输入R_fin、R_news、R_risk,结合历史股价P和市场指数M,生成投资潜力评估(R_invest)和推荐评级(R_rec)
评级规则:如果预期股价涨幅超过沪深300指数,则评级为“买入”,否则为“卖出”
模型训练优化:SFT+RL
针对框架中的4个核心智能体(财务分析、新闻分析、经营分析、预测),采用“监督微调+强化学习”的两阶段训练:
- SFT学习专业分析模式
数据:使用FinRpt数据集中相应模块的标注样本(输入为提取模块的输出,输出为高质量的分析部分)
方法:采用LoRA(低秩适应)微调,仅更新低秩适配器参数Δθ,避免全面微调带来的高资源消耗
优化目标:最大化生成目标文本的似然概率
maxΔθ∑(X,Y)∈DdemologP(Y∣X;θ0+Δθ)
max _{\Delta \theta} \sum_{(X, Y) \in D_{demo }} log P\left(Y | X ; \theta_{0}+\Delta \theta\right) - 强化学习(RL):优化投资预测准确性
针对对象:仅优化预测智能体(核心影响投资建议的有效性)
算法:采用DAPO(动态采样策略优化),基于PPO改进,确保训练的稳定性
奖励函数:综合评估推荐评级的准确性和投资分析的质量,权重分配为α=0.6(评级准确性)、β=0.2(ROUGE-1)、γ=0.2(ROUGE-L)
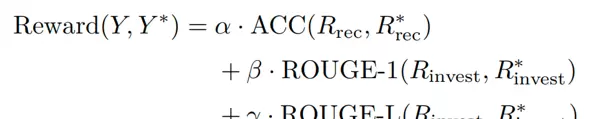
优化目标:最大化裁剪后的代理目标,防止策略更新幅度过大
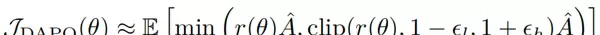
五、评估系统:全面评估ERR生成质量
设计了包含“基础指标+LLM专业评估”的双重评估体系,确保评估的全面性和专业性:
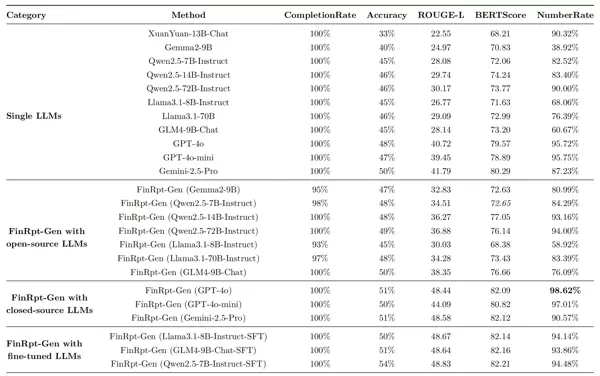
1. 基本指标(5项)- 量化文本品质与预测精确度
完成度(Completion Rate):生成报告是否遵循6章节格式标准
精确度(Accuracy):推荐评级(Buy/Sell)的准确性
语义一致性(BERT Score/ROUGE-L):与专家报告的语义匹配度
数字涵盖率(Number Rate):生成报告中财务数字的密度(相对于专家报告)
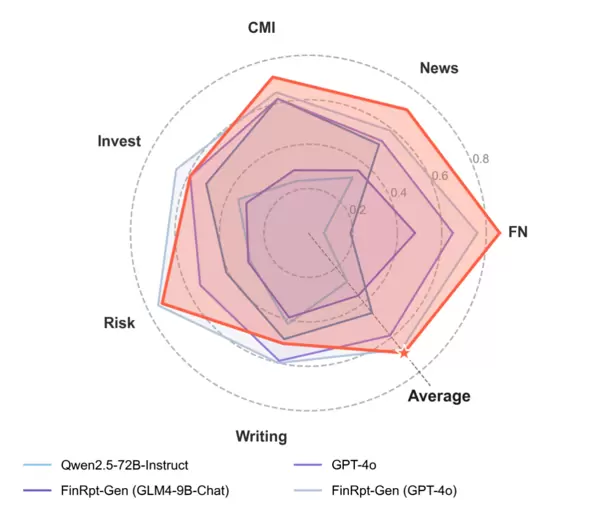
2. LLM专业评估(6个方面):评价金融专业水平
财务数字(FN):财务数据的精确性和分析深度
新闻关联性(News):新闻分析的相关性和完整性
公司/市场/行业见解(CMI):对管理、市场趋势的理解
投资逻辑(Invest):投资建议的合理性和论证的充分性
风险分析(Risk):风险辨识的全面性
写作质量(Writing):连贯性、易读性和逻辑一致性
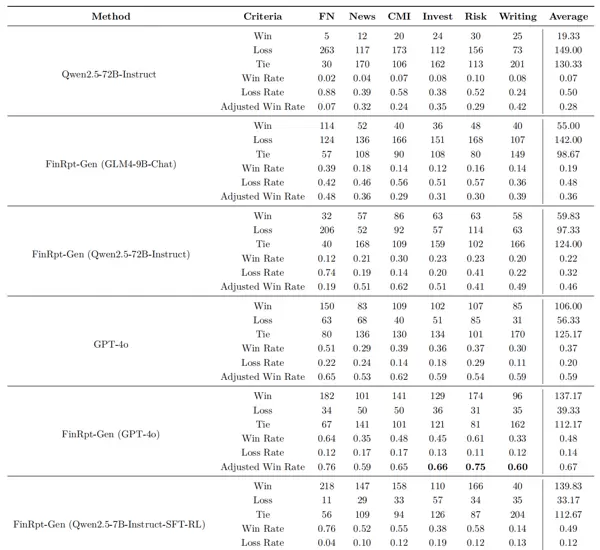
评估方法:采用GPT-4o作为评判代理,通过pairwise比较各模型生成的报告,计算调整后的胜率(胜场数 + 0.5×平局数)/总样本量
实验表现

参考文献:FinRpt: Dataset, Evaluation System and LLM-based Multi-agent Framework for Equity Research Report Generation,https://arxiv.org/pdf/2511.07322v1

 京公网安备 11010802022788号
京公网安备 11010802022788号







