


 雷达卡
雷达卡



案例背景
MNIST手写数字辨识是深度学习领域的标准入门项目,被称为深度学习的“Hello World”。本例利用全连接神经网络完成对0-9手写数字的分类。
本文基于PyTorch实现了几个深度学习案例的代码。
MNIST手写数字辨识案例
此案例的目标是,训练神经网络能够辨识手写数字。虽然此案例常被视为RNN的经典应用,但由于尚未编写RNN的相关笔记且数据较为简单,因此直接采用了线性层代替卷积层。
模块导入
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt第一部分不多解释
nn是神经网络的核心组件,提供了网络层的实现
optim是优化器(包括SGD,Adam等)
torchvision是计算机视觉工具包,提供了常用的数据库
DataLoader用于将数据集转换成一个可迭代的数据加载器
plt用于绘图。
数据准备
# 管道,处理数据,先把数据变成张量,然后在标准化
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 下载数据到指定目录并且利用管道处理后的张量转换成一个Dataset数据集
# 训练数据集
train_dataset=torchvision.datasets.MNIST('./data',
train=True,
transform=transform)
# 测试数据集
test_dataset=torchvision.datasets.MNIST('./data',
train=False,
transform=transform)
#训练数据加载器
train_loader=DataLoader(train_dataset,batch_size=68,shuffle=True) #batch_size代表每个epoch中的每轮是68个数据,shuffle代表打乱数据集
#测试数据加载器
test_loader=DataLoader(test_dataset,batch_size=68,shuffle=False)数据准备通常涉及将常规数据转换为张量,接着是创建数据集,最后是数据加载器。
神经网络构建
class net(nn.Module):
def __init__(self):
super(net,self).__init__()
# 为了方便直接全部用线性层代替
self.linear1=nn.Linear(28*28,128)
self.linear2=nn.Linear(128,64)
self.linear3=nn.Linear(64,10)
# 激活层
self.relu=nn.ReLU()
# 归一化层
self.dropout=nn.Dropout(0.2)
# 向前传播,在使用时自动会进行该操作
def forward(self,x):
# 先把28*28的矩阵张量,展开成1,28*28的张量
x=x.view(-1,28*28)
# 输入先第一层加权求和,然后归一化,最后激活
x=self.relu(self.dropout(self.linear1(x)))
x=self.relu(self.dropout(self.linear2(x)))
#最后一层是输出层,直接输出
x=self.linear3(x)
return x继承nn.Module类,__init__()中初始化网络层,forward()定义前向传播的方法,在使用模型时会自动调用此方法。
思考
可在初始化阶段加入参数的初始化,例如Kaiming和Xavier初始化。
模型训练
#设置epoch轮数
epochs=5
#挂载的设备,gpu还是cpu
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#实体化模型到指定设备上
model = net().to(device)
#实体损失函数
criterion = nn.CrossEntropyLoss()
#实体优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
#开启训练模式
model.train()
#总损失,做统计用
total_loss=0
#开始训练
for epoch in range(epochs):
totol_loss=0
#每轮次遍历迭代器,每次迭代68个
for batch_idx, (data, target) in enumerate(train_loader):
#梯度归零,防止累加
optimizer.zero_grad()
#模型预测
y_pred=model(data)
#求损失
loss=criterion(y_pred,target)
#反向传播求梯度
loss.backward()
#梯度更新
optimizer.step()
#累加损失
total_loss += loss.item()
#输出当前批次的损失
if batch_idx % 100 == 0:
print(f'Epoch: {epoch} [{batch_idx * len(data)}/{len(train_loader.dataset)}] Loss: {loss.item():.6f}')
#输出平均损失
print(f'Epoch {epoch} Average Loss: {total_loss/len(train_loader):.6f}')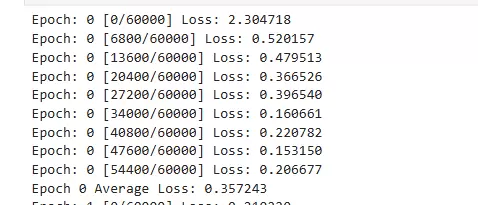
对于神经网络的训练,通常包含梯度清零、模型预测、损失计算、反向传播、梯度更新五个步骤,这些步骤基本上是固定的。
思考
训练过程中可以考虑使用学习率递减策略,以及是否有更优的优化器选择。
测试模型
def test_model():
#模型测评模式
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
print(f'测试集准确率: {accuracy:.2f}%')
return accuracy
test_model()
def predict_single_image():
model.eval()
# 获取一张测试图片
data_iter = iter(test_loader)
images, labels = next(data_iter)
image, label = images[0], labels[0]
with torch.no_grad():
output = model(image.unsqueeze(0).to(device))
_, predicted = torch.max(output, 1)
print(f'真实标签: {label.item()}, 预测结果: {predicted.item()}')
# 显示图片
plt.imshow(image.squeeze(), cmap='gray')
plt.title(f'True: {label}, Pred: {predicted.item()}')
plt.show()
predict_single_image()测试过程与上述类似,这里不再赘述。
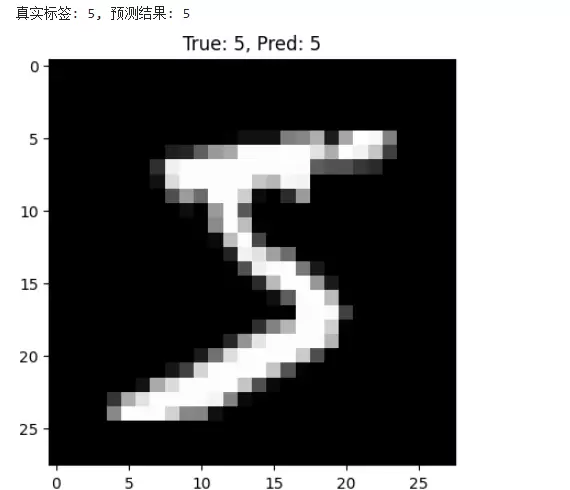
效果展示
最后,如果想了解RNN实现方式,可以参考这篇文章:
https://nextjournal.com/gkoehler/pytorch-mnist

 京公网安备 11010802022788号
京公网安备 11010802022788号







