


 雷达卡
雷达卡



PRBench: 大规模专业评估标准,用于衡量高风险职业推理
来源:arXiv, 2511.11562
摘要
当前模型的进展通常依赖学术基准来评估,但这些基准在实际专业环境中对性能的反映有限。现有的评估方法往往不能充分衡量法律和金融等高风险领域的开放式任务,其中经济回报至关重要。为了解决这一问题,我们推出了“Professional Reasoning Bench (PRBench)”,这是一个涉及金融与法律领域的真实、开放且复杂的基准测试集。
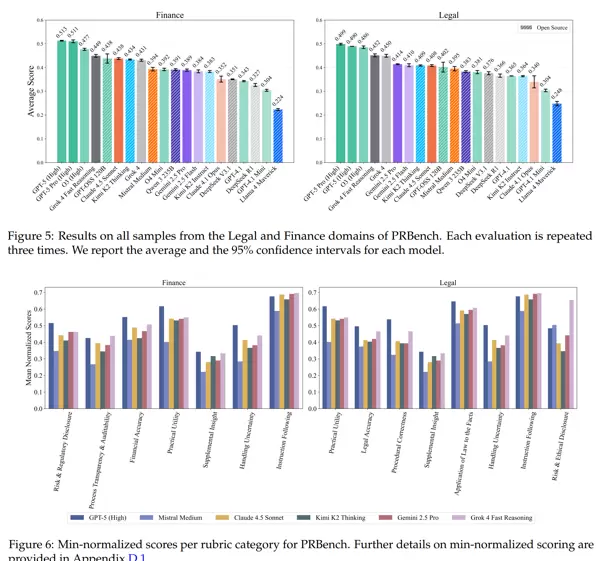
PRBench 包含 1,100 个由专家设计的任务和 19,356 条详细的评估标准,成为迄今为止已知的最大规模的公开专业基准。参与此项目的有 182 名合格的专业人士,他们拥有法律博士(JD)、特许金融分析师(CFA)资格或至少六年的工作经验,并基于其实际工作流程贡献了这些任务。这导致了显著的任务多样性,覆盖了 114 个国家和 47 个美国司法管辖区。
所有专家策划的评估标准都通过了一个严格的质量控制流程,包括独立专家审核。在对 20 款领先模型进行评估后,我们发现它们还有很大的提升空间,在最难的任务子集中得分最高为金融领域的 0.39 和法律领域的 0.37。此外,我们还记录了提示信息的经济影响,并使用人工标注的评估类别来分析性能表现。
研究显示,即使总分相近,不同模型在特定能力上的表现也可能存在显著差异。常见的问题包括判断不准确、缺乏过程透明度以及推理不完整等,这些都表明了它们在专业领域应用时存在的可靠性差距。

文章概览
研究问题:
如何有效地评估大规模语言模型(LLM)在法律和金融领域的高风险职业推理能力?
主要贡献:
本文提出了并开放了 PRBench,一个包含 1,100 个专家编写的问题及 19,356 条评估标准的大型基准测试集,旨在衡量法律和金融领域的职业推理能力。
重点思路:
- 与 182 名领域内专家合作,构建了多轮对话问答任务,涵盖全球 114 个国家的法律和金融挑战。
- 每个问题都配有详细的评估标准(rubric),包含 10 到 30 条描述性条目,并分配重要性权重,以支持自动化且可解释的评估过程。
- 对相关法律和金融领域的评估标准进行了分类整理,确保了评估的关键能力和质量覆盖。
- 通过更复杂的鲁棒性测试方法,系统地评估现有语言模型的表现,确保其合理性和有效性。
分析总结:
在法律和金融领域的评价中,大多数大型语言模型的实际应用表现不佳。PRBench 的评估结果显示,这些模型在完整推理能力和过程透明度方面存在明显不足。尽管某些模型如 GPT-5 在法律领域表现出较高的准确性(达到 0.64),但在系统性评估的其他部分仍然得分较低,显示出改进的空间和必要性。
专家的意见和增强的模型评估揭示了 AI 系统在处理高风险经济决策时的重要性及潜在影响。
个人观点:
本文的核心在于创建了一个大规模、由专家策划的法律和金融领域的基准测试集。

 京公网安备 11010802022788号
京公网安备 11010802022788号







