


 雷达卡
雷达卡



EVICheck: 基于证据驱动的独立推理与整合验证的事实核查方法
本文详细介绍了即将在IJCAI 2025上发布的最新研究成果——《EVICheck: Evidence-Driven Independent Reasoning and Combined Verification Method for Fact-Checking》。
论文概览
该论文已被第34届国际人工智能联合会议(IJCAI)接受,论文的第一作者为王凌霄。EVICheck是一种创新的自动化事实核查方法,它通过证据驱动的独立推理与整合验证,解决了当前基于大语言模型的事实核查中存在的证据利用不足和缺乏明确验证标准的问题。实验结果显示,EVICheck在公共RAWFC数据集上的表现优于现有的SOTA LLM-RAG方法,展示了显著的竞争优势。
会议简介
第34届国际人工智能联合会议(IJCAI)将于2025年8月16日至22日在加拿大蒙特利尔举行。自1969年首次举办以来,IJCAI一直是人工智能领域最古老且最具影响力的学术会议之一。自2016年起,大会每年召开一次,旨在聚集全球的人工智能研究者,共同探讨和展示最新的研究成果。会议涵盖机器学习、自然语言处理、计算机视觉、知识表示、规划与推理、机器人技术等多个热门研究领域。IJCAI是中国计算机学会(CCF)认定的A类会议。
作者简介
王凌霄,中国传媒大学媒体融合与传播国家重点实验室研究生,专注于基于大模型的舆情分析研究。
导师简介
石磊,中国传媒大学媒体融合与传播国家重点实验室副研究员,硕士研究生导师。他还是中国人工智能学会智能服务专委会委员、计算机学会多媒体专委会委员、中国中文信息学会社会媒体处理专委会成员,以及多个知名期刊的编委。石磊教授的研究领域广泛,包括社交网络搜索与挖掘、舆情分析与监测、跨媒体语义学习、人工智能、智能信息处理等。他在国内外重要期刊和会议上发表了50余篇论文,申请并获得了9项发明专利,参与制定了9项国家标准,登记了4项软件著作权,并出版了一部专著。他曾获得第六届CCF大数据学术会议(CCF Big Data 2018)最佳论文奖。目前,他负责主持两项国家重点研发计划项目子课题、一项国家统计局重点课题和一项广西信息中心项目。
本推文由王凌霄撰写,经石磊老师审校,并获作者授权发布。
研究背景及主要贡献
近年来,基于检索增强生成(Retrieval-augmented Generation,RAG)和大语言模型(Large Language Model,LLM)的方法已成为自动事实核查的主流技术。然而,这些方法在处理复杂、有噪声或矛盾的证据时,存在两个主要局限性:一是集体推理的局限性,即现有方法通常将所有检索到的证据聚合后输入LLM进行“集体推理”,这可能导致关键证据的说服力被噪声或不相关信息所稀释;二是黑箱验证的不可靠性,即传统核查流程依赖于简单的提示词或少样本学习直接得出真假标签,缺乏结构化和可解释的验证标准和二次审查机制,使最终判断难以追溯。EVICheck正是为了克服这些局限而设计的。
论文的主要贡献包括:
- 提出证据驱动的独立推理机制:该机制要求LLM对每个独立证据与声明进行深入分析和初步判断,确保每条证据的价值得到最大化利用,显著提升了模型处理复杂证据集(包括矛盾证据)的能力。
- 设计整合验证方法:论文提出了一种结构化、多步骤的最终验证流程,将所有独立推理结果进行科学整合,包括引入二次深度验证机制来解决证据冲突,形成明确、可靠的终局判断。
- 实现SOTA性能:EVICheck在公共RAWFC数据集上的评估显示,其在准确率和F1分数等所有评估指标上均超越了现有的最先进的LLM-RAG基线方法,证明了其在自动化事实核查中的强大潜力和竞争优势。
方法
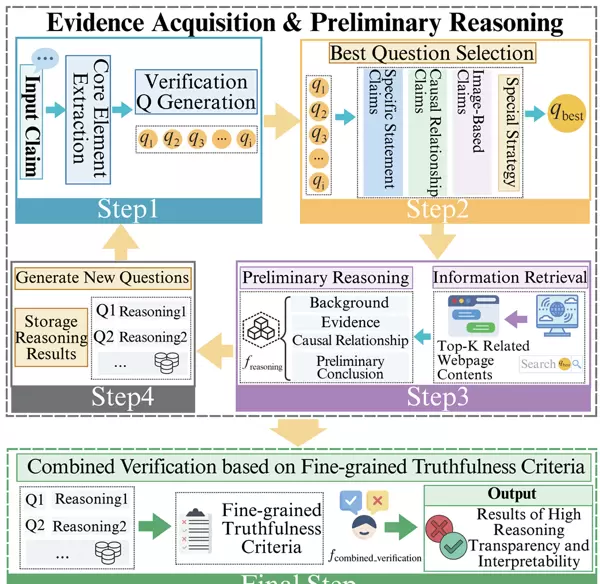
图1展示了EVICheck的整体架构,其核心在于将自动化事实核查定义为一个多步骤的推理过程,主要包括两个模块:证据获取与初步推理,以及基于细粒度真实性标准的整合验证。
在首个模块中,系统首先基于输入声明执行核心元素的提取及验证问题的生成,这是第一步。接着,在第二步,模型依据特定策略(如因果关系、特定陈述等)挑选出最佳的问题。第三步,系统利用最佳问题通过搜索引擎API进行信息检索,并对检索结果进行初步推理,形成包括背景、证据、因果关系及初步结论在内的结构化输出。第四步,模型根据已有的推理结果生成新的问题,并存储这些推理结果,这一过程重复进行N次。在最后一步,整合验证模块将汇总所有循环的推理结果,应用细粒度的真实性标准(如表1所示),通过单一模型做出最终判决,产生高透明度和可解释性的核查结果。

三、实验
(1)实施细节
本文的实验在公开的RAWFC数据集上开展,该数据集包括True, False, Half三种标签。实验采用了GPT-3.5, GPT-4, 和LLaMA-3-8B-Instruct三种大型语言模型。同时,利用LLaMA-Factory框架和LORA方法对LLaMA-3-8B-Instruct进行了微调,训练周期为3个Epoch。在RAG过程中,选用SerpApi作为搜索引擎API。实验配置了5个验证问题和2轮循环推理。评价指标主要包括宏观平均精度(P)、召回率(R)和F1-Score。对比的方法分为监督学习方法和基于LLM的方法两种类型。
(2)实验结果
本文提出的EVICheck与两类基准方法进行了对比。如表2所示,EVICheck在所有评估指标上均有优秀表现。特别是使用GPT-4和微调后的LLaMA 3时,EVICheck的性能最佳,相较于传统顶级方法,其准确率提高了3.5%,精度提升了大约8.6%,F1分数增加了大约6.0%(达到63.3%)。这表明,EVICheck通过其独特的推理和验证机制,在事实核查任务上实现了显著的准确性和可靠性提升。
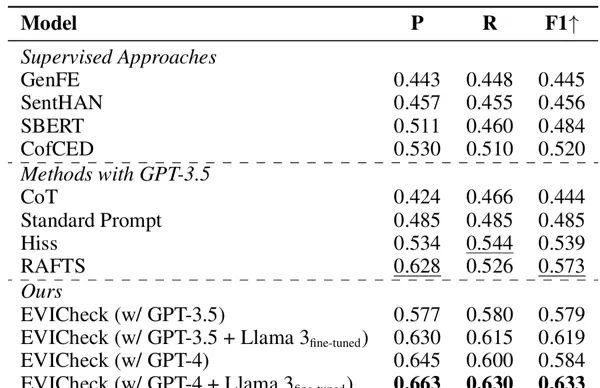
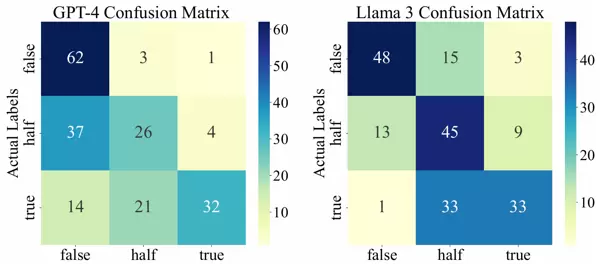
图2展示了GPT-4和微调后LLaMA 3模型的混淆矩阵热力图。从图中可以看出,GPT-4显示出一定的负面偏见,比如更倾向于作出“False”的判断,并且容易将“Half”声明归类为“False”。相反,微调后的LLaMA 3模型显示出较为平衡的偏见,尤其是在判断“True”声明时的准确性得到了提升。这表明,通过微调,LLaMA 3模型能更好地适应复杂的多维度验证任务,从而增强推理过程的稳定性和可靠性。
(3)消融实验
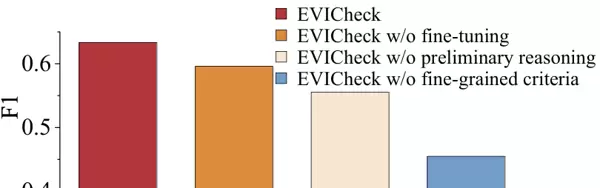
为了验证EVICheck中各关键组件的有效性,本文进行了消融研究,结果见图3。移除模型微调(w/o fine-tuning)导致F1分数下降了3.47%,证明了微调对提高最终判决准确性的重要作用。移除初步推理(w/o preliminary reasoning)使得F1分数显著降低了7.77%,这突显了在检索后即时进行独立分析和推理,对于整合多轮信息的关键性。移除细粒度标准(w/o fine-grained criteria)则使F1分数下降了10.08%,说明明确而细致的验证标准是EVICheck模型准确执行验证的基础。所有组件的去除都导致了性能的下降,证实了EVICheck设计的合理性和完整性。
四、总结与展望
本文介绍了一种新的自动化事实核查方法——EVICheck,旨在克服现有方法在证据利用不充分和缺乏明确验证标准两方面的主要限制。EVICheck通过促使模型对每个证据进行独立分析和详尽推理,随后整合所有结果,并应用细粒度的真实性标准进行综合验证,从而显著提升了核查的可靠性。RAWFC数据集上的实验证明,EVICheck在所有评估指标上均优于现有的顶级方法,显示了其在对抗虚假信息方面的巨大潜力。尽管EVICheck取得了显著成就,但作者指出它目前还难以处理非正式的社交媒体声明和多模态声明(如图片、视频)。因此,未来的努力将集中在整合更多的社交媒体API和支持多模态推理,以应对更加复杂的虚假信息挑战。总之,EVICheck为自动化事实核查领域提供了一个创新且实用的解决方案。

 京公网安备 11010802022788号
京公网安备 11010802022788号







