


 雷达卡
雷达卡



作为 Java 开发者,掌握 MySQL 几乎是必备技能之一。尤其是在进阶学习过程中,深入理解 MySQL 的底层机制与性能调优显得尤为重要。
然而,很多开发者容易陷入一种惯性思维:一提到 MySQL,就立刻聚焦于索引设计、SQL 优化等“热门”话题。本文则希望跳出这些常见讨论,带大家探索一个相对冷门但至关重要的领域:
MySQL 事务的底层实现原理
要理解这个问题,我们得从最基础的地方讲起。
首先需要明确的是,MySQL 支持事务的并发执行。而一旦涉及并发,就不可避免地面临一个经典问题——并发安全性。具体到数据库场景中,这种情况可能表现为:事务 A 正在修改某条数据,同时事务 B 也在操作同一条记录。如果不加控制,极有可能导致数据混乱。MySQL 在架构设计之初就已经充分考虑到了这一点。
那么,MySQL 是如何应对这类并发冲突的呢?它主要通过以下几种机制来保障事务的一致性和隔离性:
MVCC 多版本控制机制事务隔离机制锁机制接下来,让我们思考一个关键问题:
如果数据库不对并发事务进行任何管理,可能会引发哪些严重后果?
带着这个疑问,我们继续深入分析。
脏数据及其类型
所谓“脏数据”,指的是由于事务并发处理不当而导致的数据异常现象。主要包括四种情况:脏写、脏读、不可重复读和幻读。下面我们逐一解析。
1. 脏写
脏写是指一个事务已提交的修改被另一个事务的回滚所覆盖。
举个例子:假设有事务 A 和事务 B。事务 A 首先启动,并将 id 为 1 的记录 name 字段更新为 A(原值为 null),但尚未提交。紧接着事务 B 启动,也将该记录的 name 修改为 B 并立即提交。此时事务 A 决定回滚自己的更改。结果就是这条记录恢复为 null,导致事务 B 的修改“凭空消失”。
当事务 B 再次查询时,发现 name 又变回了 null,这就构成了脏写——自己已经提交的数据被其他事务的回滚影响了。
如果感觉抽象,不妨看下面这张图帮助理解:
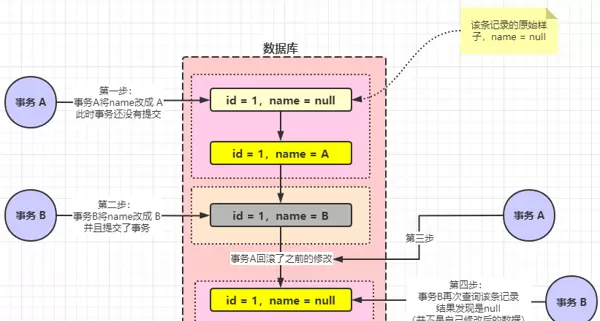
MySQL 如何防止脏写?答案是使用锁机制。当某个事务对一条记录进行修改时,MySQL 会将该记录与当前事务绑定,类似于 JVM 中的线程锁机制。由于事务 A 先获得锁并持有该记录,事务 B 必须等待其释放后才能操作。这样就避免了并发修改带来的冲突。
有人可能会问:“这不就成了串行执行吗?那岂不是牺牲了并发性能?” 实际上,这些操作大多发生在内存中的 Buffer Pool 里,因此效率非常高,不会造成明显的性能瓶颈。
2. 脏读
脏读指的是一个事务读取到了另一个事务尚未提交的数据。
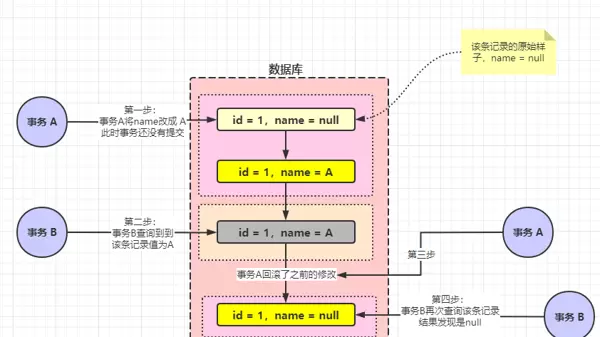
例如:事务 A 修改了 id 为 1 的记录 name 为 A,但还未提交;此时事务 B 查询该记录,读到了“A”这个值,并基于此进行后续逻辑处理。然而事务 A 随后回滚,name 恢复为原始值。这时事务 B 再次查询就会发现数据前后不一致,这就是典型的脏读。
简而言之,事务 B 读取了一个“临时状态”的数据,而这个状态最终并未真正存在过。
为了更直观地展示这一过程,请参考下图:
3. 不可重复读
不可重复读是指在同一事务中,多次读取同一记录时得到不同的结果,通常是由于其他事务对该记录进行了修改并提交。
举例说明:事务 A 开启但未做任何操作;事务 B 将 id 为 1 的记录 name 改为 B 并提交;事务 A 第一次查询得到 name = B;接着事务 C 将该记录 name 改为 C 并提交;事务 A 再次查询时发现 name 已变为 C。
尽管两次查询都在同一个事务 A 中执行,但结果却不一致,这就是不可重复读。
听起来概念复杂,其实本质很简单。我们用一张图来辅助理解:

4. 幻读
幻读关注的是记录数量的变化,而不是单条数据的值变化。它通常出现在范围查询中,表现为前后两次查询返回的行数不同,原因在于其他事务插入或删除了符合条件的新记录。
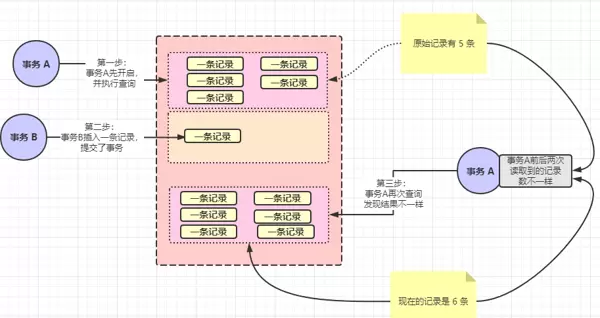
比如:事务 A 执行如下 SQL 查询:
select * from user假设返回 5 条记录。随后事务 B 向 user 表插入一条新数据并提交。当事务 A 再次执行相同的查询时,结果变成了 6 条记录。事务 A 会感到困惑,仿佛出现了“幻觉”——这就是所谓的幻读。
与不可重复读的区别在于:不可重复读侧重于已有记录的修改,而幻读强调的是新增或删除导致的数量变化。
下图可以帮助你更清晰地理解幻读的发生过程:
上述四个问题属于现代数据库中典型的并发事务处理难题,它们会因数据库事务隔离级别的不同而显现。接下来我们将深入探讨事务的隔离级别及其背后的工作机制。
事务隔离级别共有四种,每种级别对应不同的并发控制策略和数据一致性保障程度:
Read Uncommitted读取未提交(Read Uncommitted):在此级别下,一个事务可以读取到其他事务尚未提交的数据变更。这种情况极易引发脏读问题,因此在实际生产环境中几乎不会被采用。
Read Committed[简称 RC]读取已提交(Read Committed):该级别确保事务只能读取到其他事务已经提交的修改结果,有效避免了脏读现象,但仍然可能出现不可重复读和幻读的问题。
Repeatable read[简称 RR]可重复读(Repeatable Read):这是 MySQL 的默认隔离级别。它保证在同一事务内多次读取同一数据时结果一致,即使其他事务对数据进行了修改并提交,也不会影响当前事务的读取视图。
serializable串行化(Serializable):这是最严格的隔离级别,类似于 Java 中的 synchronized 关键字所实现的同步机制。所有事务必须依次执行,杜绝了并发带来的任何副作用,但同时也导致性能大幅下降,通常不适用于高并发场景。
| 隔离级别 | 脏读 | 脏写 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| Read Uncommitted:读取未提交 | √ | × | √ | √ |
| Read Committed:读取已提交 | × | × | √ | √ |
| Repeatable read:可重复读 | × | × | × | √ |
| Serializable:串行化(也有称序列化的) | × | × | × | × |
为了进一步理解事务隔离的底层实现原理,我们需要引入一个关键技术——MVCC(Multi-Version Concurrency Control),即多版本并发控制。MVCC 是数据库管理系统中用于提高并发性能的一种机制,能够在不加锁的前提下实现对数据的并发访问。

虽然我们目前讨论的主题是事务隔离级别的实现原理,但似乎还未触及真正的底层逻辑。其实,并不能一上来就直接剖析核心机制,那样不仅难以理解,也容易让人迷失方向。因此,本文采取由浅入深的方式,逐步铺垫相关知识,引导读者层层递进,最终掌握事务控制的本质。
现在我们要引入一个新的概念:当数据存储在磁盘上时,每条记录除了包含业务数据外,还会附带两个关键字段——事务 ID 和回滚指针。这两个字段对于实现 MVCC 至关重要,其他细节在此暂不展开,聚焦主线才能避免陷入冗杂信息之中。

那么这两个字段分别有什么作用呢?我们从定义出发进行说明:
事务 ID事务 ID(Transaction ID):每个事务启动时都会被分配一个全局唯一的递增标识符,用以标记该事务的身份。
回滚指针回滚指针(Rollback Pointer):指向该记录在本次修改之前的旧版本数据位置,本质上是一个指向 undo log 的指针。undo log 存储的是修改前的数据快照,主要用于事务回滚或构建历史视图。
当需要操作某条记录时,系统首先会将其加载到 Buffer Pool 缓冲池中,并生成相应的 undo log 记录。
注:undo log 指的是数据修改前的原始状态记录,用于支持事务回滚和多版本读取。

假设事务 A 启动后将某条记录的值修改为 A:

此时事务 A 尚未提交,事务 B 随后启动并将该值修改为 B:

接着,在事务 A 和 B 均未结束的情况下,事务 C 也启动并将其改为 C:
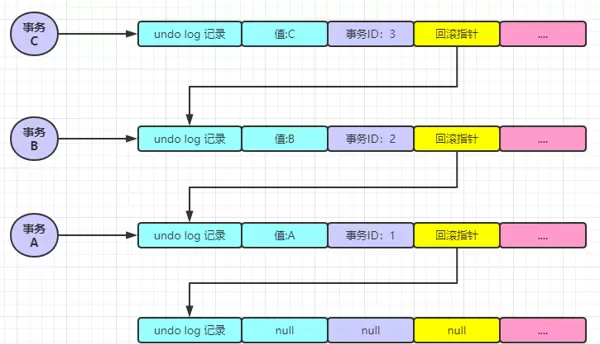
通过以上过程可以看出,这些版本之间形成了一个链式结构,专业术语称之为“MVCC 版本链”。与此同时,另一个核心概念也随之浮现——ReadView。
每一个事务在开启时都会创建一个 ReadView,它是决定当前事务能看到哪些数据版本的关键结构。可以说,理解 ReadView 是掌握事务隔离底层机制的核心所在。
那么,究竟什么是 ReadView?
ReadView 并非简单的快照,而是一个包含多个元数据字段的视图对象,用于判断哪些版本的数据对当前事务可见。其主要包含以下字段:
m_ids、min_trx_id、max_trx_id、creator_trx_id- m_ids:当前系统中所有活跃事务(未提交)的事务 ID 列表;
- min_trx_id:m_ids 中最小的事务 ID;
- max_trx_id:下一个即将分配的事务 ID(注意:不是当前最大 ID,而是即将生成的新 ID);
- creator_trx_id:创建该 ReadView 的事务自身的 ID。
仅靠文字描述可能仍显抽象,下面我们结合具体示例进行图解分析。假设当前存在一条数据记录如下所示:

这条记录显然是由某个先前事务修改后持久化下来的成果,即当前最新的已提交版本。
现假设有三个事务 A、B、C 依次开启,其事务 ID 分别为 4、5、6。以事务 A 为例,在其开始时刻生成的 ReadView 内容如下:
- m_ids = [4, 5, 6]
- min_trx_id = 4
- max_trx_id = 7(表示下一个待分配的 ID)
- creator_trx_id = 4

当事务 A 执行第一次查询操作时,系统会依据其 ReadView 中的信息,结合 MVCC 版本链中的各个版本的事务 ID,判断哪一个数据版本对该事务可见,从而实现隔离性控制。
我们首先来看事务在 MVCC 机制下的查询逻辑。当一个事务开始查询某条记录时,它会沿着该记录的 MVCC 版本链向下追溯,寻找与当前事务可见性匹配的历史版本。具体来说,它会查看每一条 undo log 所关联的事务 ID。例如,假设当前事务 A 的事务 ID 为 4,它在遍历版本链时发现某条 undo log 的事务 ID 为 3。由于 3 小于自身的事务 ID 4,并且也小于其 ReadView 中活跃事务列表 m_ids(如包含 4、5、6)中的所有值,因此可以判断这条记录是在事务 A 开启之前就已经提交的。于是,事务 A 最终读取到的值为 C。
接下来,事务 B 也开始对该记录进行查询操作。同样地,事务 B 也会基于内存中的 MVCC 机制执行查询流程。此时它的查询路径和事务 A 初始阶段一致,查找到的结果同样是 C。这部分逻辑与前文对事务 A 的分析一致,理解起来并不复杂。然而,如果此时事务 B 将该记录的值修改为 B,则数据状态将发生变化,如下图所示:

随后,事务 A 再次发起查询请求,此时它的查询结果应当是多少?让我们逐步分析。事务 A 依然会从最新版本开始沿 MVCC 版本链向下查找。它首先遇到的是事务 ID 为 5 的 undo log 记录。经过比对发现,5 大于其 ReadView 中 min_trx_id(即 4),并且存在于 m_ids 集合中,说明事务 ID 为 5 的事务仍处于活跃状态,尚未提交。根据可见性规则,该版本对事务 A 不可见,因此不会被采纳。
接着继续向下查找,找到了事务 ID 为 3 的 undo log。此时发现 3 不在 m_ids 中,且小于 m_ids 的最小值 4,满足“已提交且早于当前事务”的条件。因此,事务 A 仍然会选择这个版本,最终查询结果依旧是 C。
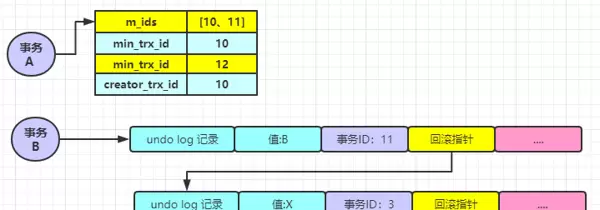
现在考虑一种更关键的情况:假设事务 A 自己将该记录更新为 A,然后再执行一次查询操作。那么这次查询的结果是 A 还是 B?这一步非常关键,请结合以下示意图进行思考:
我们来详细拆解这一过程。当事务 A 更新了该记录后,会在版本链上新增一条由自己(事务 ID 为 4)生成的 undo log。此时事务 A 再次发起查询,系统会重新评估版本链上的各个节点。它首先看到的是事务 ID 为 4 的最新版本记录。通过对比 ReadView 的 creator_trx_id 发现,该版本正是由当前事务本身所修改的。按照 MVCC 可见性原则,当前事务始终能看到自己所做的更改。因此,事务 A 查询得到的结果就是 A。
那么如果此时换成事务 B 来查询这条记录,结果又会如何?我们来进行推演:事务 B 查看版本链顶端的记录,发现其事务 ID 为 4,属于当前活跃事务集合 m_ids 之中,但并非自己的事务 ID(假设为 5)。由于该事务仍在进行中且非自身修改,因此该版本对其不可见,需继续向下查找。
紧接着,事务 B 找到了事务 ID 为 5 的 undo log 记录,恰好与其自身的事务 ID 相同。这意味着这是它自己曾经写入的数据版本。根据可见性规则,事务总是能够看到自己的修改。因此,事务 B 查询返回的结果是 B。
以上便是关于 ReadView 机制的核心工作原理。虽然整体逻辑不复杂,但需要仔细梳理每个判断条件。下面我们做一个小结:
ReadView 借助 MVCC 的版本链机制实现多版本并发控制,其内部维护了几个关键属性:
- m_ids:当前系统中正处于活跃状态的事务 ID 列表(重点)
- min_trx_id:m_ids 中最小的事务 ID
- max_trx_id:即将分配给下一个新事务的 ID
- creator_trx_id:创建该 ReadView 的当前事务 ID
需要注意的是,ReadView 实际上是对 Undo log 日志中各版本记录可见性的快照判定工具,它决定了哪些历史版本对当前事务可见。
在此基础上,我们进一步探讨本文的主题——事务的底层实现原理。事实上,整个事务隔离机制正是建立在 ReadView 的基础之上的。接下来,我们将以两种常见的隔离级别为例展开分析:RC(Read Committed)与 RR(Repeatable Read)。
1. Read Committed(读已提交)
RC 是标准 SQL 定义的四种事务隔离级别之一,其核心语义是:只能读取其他事务已经提交的数据。举例而言,若事务 A 与事务 B 同时运行,在事务 B 提交其修改后,事务 A 的后续查询应能感知到这一变更。
要理解 RC 的实现机制,必须明确一点:在该隔离级别下,每一次 SELECT 查询都会触发数据库生成一个新的 ReadView。这就是 RC 能够读取最新已提交数据的根本原因。
设想如下场景:事务 A 和事务 B 的事务 ID 分别为 10 和 11。在事务 A 尚未启动时,事务 B 已将某条记录的值由原始值 X 修改为 B,但尚未提交。此时系统的状态可参考下图:

此时事务 A 开始执行第一次查询操作。根据 RC 的规则,数据库将为其构造一个新的 ReadView,其中各属性如下:
- m_ids: [10, 11]
- min_trx_id: 10
- max_trx_id: 12
- creator_trx_id: 10
由于事务 B(ID=11)仍处于活跃状态,其修改的版本不会被事务 A 接受。因此事务 A 此时读取的是早于事务 B 修改前的旧版本,即值 X 或之前的某个已提交版本(视具体情况而定)。一旦事务 B 提交,下次事务 A 查询时将获得新的 ReadView,届时 m_ids 不再包含 11,从而使得事务 B 的修改变为可见。
综上所述,RC 隔离级别的核心在于每次查询都重建 ReadView,确保读取的是截至查询时刻为止所有已提交事务的最新结果。

我们继续来看查询过程,这一部分与前文所述的机制一致。当事务 A 发起查询时,首先找到最近的一条记录,其事务 ID 为 11。该 ID 存在于当前活跃事务列表 m_ids 中,但并不等于事务 A 自身的事务 ID(10),因此系统会沿着 undo log 链向前追溯。随后查找到事务 ID 为 3 的版本记录,发现它既不在 m_ids 列表中,又小于当前 ReadView 中的最小事务 ID(min_trx_id = 10),由此可以判断该版本是在当前事务开始前就已经提交的历史数据。因此,事务 A 最终读取到的结果是 X。
接下来,事务 B 被激活并成功提交了修改操作,将数据值由 X 更改为 B。之后,事务 A 再次执行相同的查询请求。此时便进入了 RC(Read Committed)隔离级别的核心机制环节:数据库会为事务 A 重新生成一个全新的 ReadView,其内容如下:
m_ids:[10]
min_trx_id:10
max_trx_id:12
creator_trx_id:10

按照正常的可见性判断流程,事务 A 在此次查询中首先读取到的是事务 ID 为 11 的记录版本。由于该 ID 并未出现在当前 ReadView 的 m_ids 列表中,说明此事务已经提交,并且发生在当前事务创建 ReadView 之前或期间之外。因此,这个版本对事务 A 是可见的,于是本次查询返回的结果为 B。
这就是 RC 隔离级别的实现逻辑。你有没有发现,一旦理解了 ReadView 的工作机制,这些看似复杂的规则其实变得非常清晰明了?
2. Repeatable Read(可重复读)
Repeatable Read(RR)是 MySQL 默认的事务隔离级别。作为默认选项,很多人以为它一定“很强大”?但实际上,了解原理后你会发现——不过如此。
RR 的关键特性在于:ReadView 在事务首次读取时创建后,直到整个事务结束都不会再更新或重建。
假设有两个事务 A 和 B,事务 ID 分别为 10 和 11。事务 B 先行启动并将数据从原始值 X 修改为 B。随后,事务 A 执行一次查询操作。
此时的查询流程与前述 RC 情况完全相同,不再重复描述。重点在于后续变化:在事务 B 提交之后,事务 A 再次发起同样的查询请求。这时神奇的现象出现了——因为 RR 的 ReadView 不会刷新,事务 A 仍使用最初创建的那个视图,其中包含以下信息:
m_ids:[10, 11]
min_trx_id:10
max_trx_id:11
creator_trx_id:10
查询过程中,系统首先读取事务 ID 为 11 的记录版本。由于该 ID 存在于当前 ReadView 的 m_ids 列表中,表示这是在事务 A 开启时尚未完成的事务,因此该版本不可见,需继续沿 undo log 向前查找。当找到事务 ID 为 3 的记录时,发现其不在 m_ids 中,且远小于 min_trx_id,确认为历史已提交版本,于是事务 A 返回结果 X。
现在你应该明白,在 RR 隔离级别下,为何同一事务内的多次查询能保持一致性了吧?根本原因就在于 ReadView 的静态性,避免了因视图频繁更新而导致的数据波动。
本文小结
为了深入剖析事务的底层运行机制,本文进行了详尽的前置铺垫。相信读者在阅读之后,不仅能够更透彻地理解不同隔离级别下事务行为的差异,也能真正掌握 undo log 在版本控制中的关键作用。当你把 ReadView、事务 ID、活跃事务列表以及回滚链路这些概念串联起来时,就会感受到一种“豁然开朗”的通透体验。这种将零散知识点融会贯通的过程,确实令人着迷 ^_^

 京公网安备 11010802022788号
京公网安备 11010802022788号







