


 雷达卡
雷达卡



模型微调(SFT)面试完全指南:从基础到前沿的深度解析
随着大模型技术的迅猛发展,监督微调(SFT)已成为实现AI能力定制化的核心手段。无论是在理论理解还是工程落地层面,SFT都成为AI工程师面试中的高频考点。本文系统梳理SFT的知识体系,涵盖从基础概念到前沿进展的25+个常见问题,助你在技术面试中展现扎实功底。
导语
监督微调(Supervised Fine-Tuning)是让通用大模型向特定任务或领域“专业化”转变的关键步骤,也是考察候选人深度学习理论与实践能力的重要维度。面对面试官从原理推导到工程细节的层层追问,你是否已准备充分?
本文将围绕以下三大核心模块展开:
- 基础概念:厘清SFT的本质定位
- 技术原理:剖析训练机制与优化策略
- 数据工程:详解高质量数据构建方法
一、基础概念篇:理解SFT的本质
问题1:什么是监督微调(SFT)?它在LLM训练流程中处于什么位置?
答案: 监督微调(SFT)是指在已完成预训练的大语言模型基础上,利用标注良好的监督数据进行进一步训练的过程。该阶段在整个LLM训练链条中承上启下,连接预训练与后续对齐阶段。
预训练(Pre-training) → 监督微调(SFT) → 人类反馈强化学习(RLHF) → 部署核心价值包括:
- 使通用模型适配具体应用场景或垂直领域
- 显著提升模型在目标任务上的准确率和输出稳定性
- 为后续如RLHF等强化学习对齐阶段提供高质量的初始策略
问题2:SFT与预训练(Pre-training)的主要区别是什么?
| 维度 | 预训练 | 监督微调 |
|---|---|---|
| 数据规模 | 海量无标注文本(TB级别) | 少量高质量标注数据(GB级别) |
| 训练目标 | 语言建模(预测下一个词) | 任务特定的监督学习目标 |
| 学习率 | 相对较大 | 较小(避免灾难性遗忘) |
| 计算成本 | 极高(数千GPU周) | 中等(数十GPU天) |
| 主要目标 | 获取通用语言理解与生成能力 | 掌握特定任务的行为模式 |
问题3:SFT与提示学习(Prompt Learning)有何异同?
区别:
- 参数更新方式:SFT通常更新全部或部分模型权重;而提示学习多采用冻结主干网络,仅训练少量新增参数(如前缀或模板)
- 数据需求:SFT依赖较充足的标注样本;提示学习可在少样本甚至零样本条件下运行
- 灵活性:SFT完成后难以快速切换任务;提示学习通过更换prompt即可实现快速迁移
联系:
- 二者均为实现预训练模型下游适配的技术路径
- 可组合使用——例如先用SFT增强模型能力,再以提示学习实现轻量级任务迁移
二、技术原理篇:深入SFT的核心机制
问题4:SFT的训练目标函数如何设计?
答案: 一般采用最大似然估计作为优化目标,即最小化模型输出分布与真实标签之间的交叉熵损失。
def sft_loss(model, inputs, targets):
# 前向传播获取logits
logits = model(inputs)
# 计算标准交叉熵损失
loss = cross_entropy(logits, targets)
# 可选正则项防止过拟合
regularization = weight_decay * l2_norm(model.parameters())
return loss + regularization
关键设计考量:
- 仅对目标响应部分计算损失,输入上下文不参与loss计算
- 使用因果注意力掩码确保自回归生成特性
- 合理设置学习率,防止破坏已有知识结构
问题5:什么是SFT中的灾难性遗忘?有哪些应对方法?
灾难性遗忘: 指模型在微调过程中过度拟合新任务数据,导致丢失预训练阶段学到的广泛语言知识和通用推理能力。
应对策略:
- 学习率控制:
- 采用较低学习率(通常1e-5 ~ 1e-4)
- 实施分层学习率:靠近输入层的学习率更小,保持通用特征提取能力
- 正则化技术:
- 使用权重衰减(Weight Decay)约束参数变化幅度
- 引入Elastic Weight Consolidation (EWC),保护重要参数不变:
ewc_loss = fisher_info * (current_params - pretrained_params)**2
- 数据策略:
- 在微调数据中混入一定比例的原始预训练语料
- 采用渐进式训练:从通用任务逐步过渡到专业任务
问题6:SFT中应选择何种学习率调度策略?
常用调度方案:
- 线性暖机 + 线性衰减:
scheduler = get_linear_schedule_with_warmup( optimizer, num_warmup_steps=500, num_training_steps=total_steps )适用于大多数场景,稳定训练初期梯度波动。 - 余弦退火衰减: 平滑降低学习率,在训练后期精细调整模型参数,适合高精度调优需求。
- 常量学习率: 简单直接,但需谨慎选择初始值,适用于微调数据分布接近预训练数据的情况。
选择建议:
- 小规模数据集:推荐使用带衰减的策略,防止过拟合
- 大规模微调数据:可尝试常量或余弦衰减
- 最终决策应基于验证集性能对比不同策略的表现
三、数据工程篇:SFT的数据准备与处理
问题7:SFT训练数据需要满足哪些关键质量要求?
核心质量维度:
- 准确性: 标注内容必须正确无误,避免误导模型学习错误模式
- 多样性: 覆盖各种输入类型、边缘案例及不同表达风格
- 一致性: 类似语义的输入应对应相似格式与逻辑结构的输出
- 完整性: 提供足够上下文信息,确保模型能做出合理判断
典型数据准备流程如下:
数据收集 → 数据清洗 → 数据标注 → 质量验证 → 数据格式化问题8:SFT数据应如何进行预处理和格式化?
答案: 数据需统一转换为模型可识别的指令-响应对格式。示例如下:
{
"instruction": "请解释Transformer的自注意力机制。",
"input": "",
"output": "自注意力机制通过计算Query、Key、Value三者关系..."
}
或对话式结构:
[{"role": "user", "content": "中国的首都是哪里?"},
{"role": "assistant", "content": "中国的首都是北京。"}]
预处理步骤通常包括:
- 清洗噪声数据(广告、乱码、重复内容)
- 标准化文本编码与特殊符号处理
- 构造统一的输入模板(prompt template)
- 按最大序列长度进行截断或拼接
def format_sft_example(instruction, input_text, output_text):
"""格式化SFT训练样本"""
template = """Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
{output}"""
return template.format(
instruction=instruction,
input=input_text,
output=output_text
)
预处理关键要点
在进行SFT(监督式微调)前,数据预处理至关重要。需确保输入数据满足模型要求,并提升整体训练稳定性:
- 统一文本格式与分隔符:使用一致的指令、输入和响应标记结构,便于模型理解任务模式。
- 处理特殊字符与编码问题:清除或标准化不可见字符、乱码及不兼容的Unicode符号,防止解析错误。
- 控制序列长度:截断或分段过长文本,确保不超过模型最大上下文窗口限制。
- 添加起始/结束标记:如[CLS]、[SEP]或特定模板标签,帮助模型识别语义边界。
问题9:如何评估SFT数据的质量与充分性?
高质量的数据集是成功微调的基础。以下为系统化的评估方法:
数据质量评估指标
class DataQualityEvaluator:
def __init__(self):
self.metrics = {}
def evaluate_diversity(self, dataset):
"""评估数据多样性"""
# 计算样本间的相似度
similarity_matrix = calculate_similarity(dataset)
diversity_score = 1 - average_similarity(similarity_matrix)
return diversity_score
def evaluate_consistency(self, dataset):
"""评估标注一致性"""
# 通过多人标注计算一致性
consistency_score = calculate_agreement(dataset)
return consistency_score
def estimate_data_requirements(self, task_complexity):
"""估算所需数据量"""
base_size = 1000 # 基础样本数量
complexity_factor = task_complexity * 500
return base_size + complexity_factor
该类可用于量化数据集的多维属性,包括内容丰富度、标注可靠性以及根据任务难度预估最小数据规模。
四、训练策略篇:SFT的工程实践
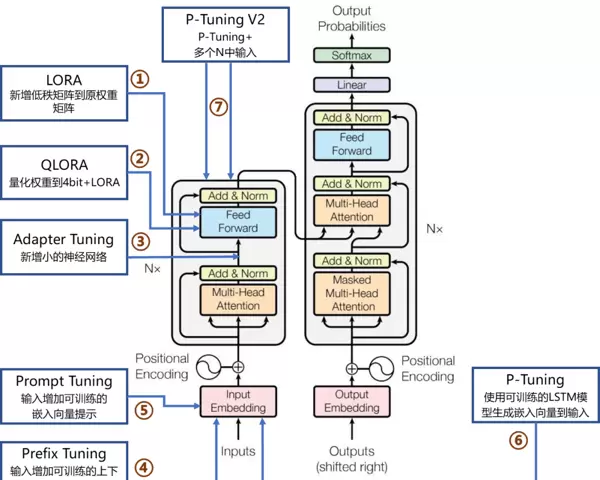
问题10:全参数微调与参数高效微调(PEFT)应如何选择?
不同微调方式适用于不同的资源条件和部署目标。以下是主流技术对比:
| 方法 | 参数量 | 计算成本 | 数据需求 | 适用场景 |
|---|---|---|---|---|
| 全参数微调 | 全部参数 | 高 | 大量数据 | 计算资源充足,追求极致性能 |
| LoRA | 0.1%-1% | 低 | 中等数据 | 资源受限,需快速迭代实验 |
| Adapter | 2%-5% | 中低 | 中等数据 | 支持多任务学习与模块化部署 |
| Prefix Tuning | <1% | 很低 | 少样本场景 | 提示工程优化、快速原型开发 |
选择建议
可根据实际资源配置动态决策最优微调路径:
def select_finetuning_strategy(available_gpus, data_size, performance_requirement):
"""基于资源与需求选择微调策略"""
if available_gpus >= 4 and data_size > 10000 and performance_requirement == "high":
return "full_finetuning"
elif available_gpus <= 2 and data_size < 5000:
return "lora"
elif data_size < 1000:
return "prefix_tuning"
else:
return "adapter"
问题11:如何监控并解决SFT训练中的过拟合问题?
过拟合会显著降低模型泛化能力,因此必须建立有效的监测机制。
过拟合监控机制
class OverfittingMonitor:
def __init__(self, patience=3):
self.patience = patience
self.best_val_loss = float('inf')
self.wait_count = 0
def check_overfitting(self, train_loss, val_loss):
"""检测是否出现过拟合迹象"""
loss_gap = train_loss - val_loss # 损失差值
if val_loss > self.best_val_loss:
self.wait_count += 1
else:
self.best_val_loss = val_loss
self.wait_count = 0
overfitting_signals = [
loss_gap > 0.5, # 训练与验证损失差距过大
def evaluate_safety_alignment(self):
"""安全性评估"""
safety_metrics = self.test_safety_questions()
return safety_metrics
def run_human_evaluation(self, samples=100):
"""人工评估"""
human_scores = {
'fluency': 0, # 流畅度
'relevance': 0, # 相关性
'accuracy': 0, # 准确性
'completeness': 0 # 完整性
}
# 人工评分逻辑
return human_scores
def run_automatic_evaluation(self):
"""自动评估"""
metrics = {}
# 困惑度评估
metrics['perplexity'] = self.calculate_perplexity()
# 任务特定指标
metrics['task_specific'] = self.evaluate_task_metrics()
return metrics
五、进阶技术篇:SFT的前沿进展
问题13:指令微调(Instruction Tuning)与SFT的关系?
关系解析:
指令微调是监督微调(SFT)的一种特殊形式,其核心目标是增强模型对自然语言指令的理解与执行能力。它通过使用大量多样化的“指令-输入-输出”三元组进行训练,使模型能够在未见过的任务上表现出良好的零样本或少样本泛化性能。
技术特点:
# 指令微调数据示例
instruction_tuning_data = [
{
"instruction": "将以下英文翻译成中文",
"input": "Hello, how are you?",
"output": "你好,最近怎么样?"
},
{
"instruction": "总结以下文章的主要内容",
"input": "长篇文章内容...",
"output": "文章主要讲述了..."
}
]
问题14:多任务SFT与单任务SFT的优劣比较
多任务SFT的优势:
- 增强模型在多个任务间的泛化能力
- 降低不同任务之间的负迁移现象
- 实现一次训练、多场景部署,提升工程效率
单任务SFT的优势:
- 针对特定任务可达到更高的精度和性能上限
- 训练过程更简单、收敛更稳定
- 便于调试、监控与针对性优化
选择策略:
def select_sft_approach(task_requirements):
"""选择SFT方法的决策逻辑"""
if task_requirements['generalization'] > 0.7:
return "multi_task"
elif task_requirements['performance'] > 0.8:
return "single_task"
elif task_requirements['data_availability'] < 0.3:
return "multi_task" # 数据少时多任务有助于泛化
else:
return "single_task"
问题15:SFT如何与RLHF配合工作?
协同工作流程:
预训练模型
↓
SFT(获得基础能力)
↓
奖励模型训练
↓
RLHF(基于人类反馈优化)
↓
最终模型SFT在RLHF中的角色:
- 为强化学习阶段提供高质量的初始策略模型
- 确保模型已具备基础的指令理解与响应生成能力
- 有效减少RLHF训练初期的输出不稳定和无效探索
六、实战问题篇:SFT的工程挑战
问题16:如何处理SFT中的类别不平衡问题?
解决方案:
class ImbalanceHandler:
def __init__(self, dataset):
self.dataset = dataset
self.class_distribution = self.calculate_distribution()
def apply_resampling(self):
"""重采样策略"""
if self.is_imbalanced():
# 过采样少数类或欠采样多数类
问题12:如何设计有效的SFT评估体系?
多维度评估框架:
class SFTEvaluator:
def __init__(self, model, tokenizer, eval_datasets):
self.model = model
self.tokenizer = tokenizer
self.eval_datasets = eval_datasets
该评估体系包含自动评估、人工评估以及安全性对齐三大模块,全面衡量SFT后模型的能力表现。
问题11:如何识别并解决SFT中的过拟合?
过拟合信号检测:
overfitting_signals = [
self.wait_count >= self.patience, # 验证损失持续上升
train_loss < 0.1 and val_loss > 1.0 # 严重过拟合
]
return any(overfitting_signals)
解决方案:
- 早停(Early Stopping):依据验证集性能动态终止训练,防止过度拟合训练数据
- 数据增强:通过对输入进行变换增加训练样本多样性,提升泛化性
- 正则化技术:如Dropout、权重衰减(weight decay)等,限制模型复杂度
- 减少模型容量:在微调阶段适当减少网络层数或隐藏层维度,避免冗余表达
问题17:SFT模型部署的注意事项
部署准备:
在将SFT(Supervised Fine-Tuning)模型投入生产环境前,需进行系统性的优化与配置。以下为关键步骤的实现逻辑。
class SFTDeploymentPreparer:
def __init__(self, model, tokenizer):
self.model = model
self.tokenizer = tokenizer推理优化处理
通过模型量化、图结构优化以及序列化保存,提升服务端推理效率和资源利用率。
def optimize_for_inference(self):
"""推理优化"""
# 模型量化
quantized_model = self.quantize_model()
# 图优化
optimized_model = self.apply_graph_optimizations()
# 序列化保存
self.save_for_serving(optimized_model)
return optimized_model构建服务模板
定义标准化的服务接口参数,确保生成过程可控且一致。
def create_serving_template(self):
"""创建服务模板"""
template = {
"model": self.model,
"tokenizer": self.tokenizer,
"max_length": 512,
"temperature": 0.7,
"top_p": 0.9,
"stop_tokens": ["\n", "###"]
}
return template监控体系搭建
部署后需持续跟踪模型表现,涵盖性能、输出质量和安全性维度。
def setup_monitoring(self):
"""设置监控"""
monitoring_config = {
"performance_metrics": ["latency", "throughput", "error_rate"],
"quality_metrics": ["perplexity", "response_quality"],
"safety_metrics": ["toxicity", "bias_detection"]
}
return monitoring_config问题18:如何调试SFT训练过程中的问题?
系统化调试方法:
训练阶段的问题往往涉及多个组件交互,因此需要分模块排查。以下是调试类的核心设计。
class SFTDebugger:
def __init__(self, model, dataloader, optimizer):
self.model = model
self.dataloader = dataloader
self.optimizer = optimizer综合问题诊断
对训练流程中的主要环节进行健康检查,并汇总潜在异常。
def diagnose_training_issues(self):
"""诊断训练问题"""
issues = []
# 检查梯度流动
if self.check_gradient_flow():
issues.append("梯度消失/爆炸")
# 检查数据流水线
if self.check_data_pipeline():
issues.append("数据预处理问题")
# 检查优化器状态
if self.check_optimizer_state():
issues.append("优化器配置问题")
return issues梯度流动检测
遍历模型参数,分析梯度范数是否处于合理范围,识别梯度异常现象。
def check_gradient_flow(self):
"""检查梯度流动"""
for name, param in self.model.named_parameters():
if param.grad is not None:
grad_norm = param.grad.norm().item()损失函数策略扩展
针对类别不平衡等问题,可采用加权损失或Focal Loss等改进方案。
损失加权机制
根据类别频率动态调整损失权重,增强稀有类别的学习信号。
def apply_loss_weighting(self):
"""损失加权"""
class_weights = self.calculate_class_weights()
def weighted_loss(logits, targets):
base_loss = cross_entropy(logits, targets)
weights = class_weights[targets]
return (base_loss * weights).mean()
return weighted_lossFocal Loss应用
聚焦于难分类样本,缓解类别不平衡带来的偏差。
def apply_focal_loss(self, gamma=2.0):
"""Focal Loss处理类别不平衡"""
def focal_loss(logits, targets):
ce_loss = cross_entropy(logits, targets, reduction='none')
pt = torch.exp(-ce_loss)
focal_loss = ((1 - pt) ** gamma * ce_loss).mean()
return focal_loss
return focal_loss数据集平衡处理
通过对少数类过采样或多数类欠采样,构造均衡训练集。
balanced_dataset = self.resample_dataset()
return balanced_dataset
return self.dataset预训练(Pre-training) → 监督微调(SFT) → 人类反馈强化学习(RLHF) → 部署if grad_norm < 1e-7 or grad_norm > 1e5:
return True
return False
七、未来趋势篇:SFT的发展方向
问题19:SFT技术的最新进展有哪些?
答案:
前沿技术方向:
参数高效微调的创新:
近年来,参数高效微调方法不断演进。LoRA(Low-Rank Adaptation)作为主流技术,催生了多种改进版本,如DoRA和LoRA+,显著提升了微调效率与性能表现。同时,研究者也在探索更高效的适配器结构设计,以进一步降低计算开销并提升模型适应能力。
多模态SFT:
随着多模态大模型的兴起,SFT已逐步扩展至跨模态场景。当前的研究重点包括文本与图像数据的联合微调,以及面向跨模态任务的指令微调方法,使模型能够统一理解并响应多种输入形式。
持续学习SFT:
在动态更新环境中,如何避免模型遗忘历史知识成为关键挑战。新兴的持续学习SFT技术致力于缓解灾难性遗忘问题,结合增量学习策略,在不重训的前提下实现知识的渐进积累。
自动化SFT:
为降低人工干预成本,自动化SFT正成为研究热点。主要包括自动筛选高质量训练样本的数据选择机制,以及基于优化算法的超参数自适应调整方案,全面提升微调流程的智能化水平。
问题20:SFT在大模型生态系统中的未来定位?
答案:
未来角色:
- 基础能力定制:SFT仍将是实现模型功能定制的核心手段,支撑从通用预训练模型到特定应用场景的转化。
- 快速适配:结合提示学习(Prompt Learning)等轻量级方法,SFT将助力模型实现任务间的快速切换与部署。
- 安全对齐:在确保模型输出符合伦理规范和价值观方面,SFT将在安全对齐过程中发挥不可替代的作用。
- 个性化AI:支持终端用户基于自身需求进行私有化微调,推动个性化人工智能服务的发展。
技术融合趋势:
SFT正逐步与强化学习、知识蒸馏、联邦学习等技术深度融合,构建更加灵活、高效且安全的大模型应用生态体系。
SFT + 提示学习 → 快速适应
SFT + 强化学习 → 精细优化
SFT + 知识蒸馏 → 模型压缩
SFT + 持续学习 → 终身学习结语
监督微调(SFT)作为连接预训练大模型与实际应用的关键桥梁,其在AI工程实践中的重要性持续上升。在技术面试中,仅掌握基本操作已远远不够,还需展现出以下几方面的综合素养:
- 系统性思维:具备从数据准备、模型训练到最终部署的全流程视角;
- 深度理解:深入理解过拟合、梯度爆炸、灾难性遗忘等核心问题的本质;
- 工程实践:能复盘真实项目中遇到的技术难题及其解决方案;
- 技术前瞻:对SFT及相关领域的发展趋势保持敏锐洞察。
需要牢记的是:优秀的AI工程师不仅懂得如何调整参数,更要明白为何如此调整,并能够系统化地应对复杂多变的实际问题。
本文内容基于当前SFT领域的最佳实践与前沿研究成果整理而成。鉴于该技术正处于快速发展阶段,建议读者持续关注最新的学术进展与工业界落地案例,以保持技术敏感度与竞争力。

 京公网安备 11010802022788号
京公网安备 11010802022788号







