


 雷达卡
雷达卡



HiProbe-VAD:基于多模态大语言模型隐状态探测的免微调视频异常检测
ACM MM’25
新疆大学;西安交通大学
摘要
视频异常检测(Video Anomaly Detection, VAD)致力于识别并定位视频中偏离常规行为模式的异常事件。传统方法通常依赖大量标注数据,且计算成本高昂,限制了其在实际场景中的广泛应用。为此,本文提出 HiProbe-VAD——一种无需微调、基于预训练多模态大语言模型(MLLMs)的新型 VAD 框架。
我们首次发现,MLLMs 的中间层隐状态相较于最终输出层,在表征上展现出更强的异常敏感性与线性可分性,蕴含更丰富的判别信息。为有效挖掘这一特性,我们设计了动态层显著性探测机制(Dynamic Layer Saliency Probing, DLSP),可在推理过程中自适应地识别并提取最具判别力的中间层隐状态。随后,通过一个轻量级异常评分器与时间定位模块对这些特征进行处理,实现高效异常检测与可解释性分析。
在 UCF-Crime 和 XD-Violence 数据集上的实验结果表明,HiProbe-VAD 不仅优于现有的免训练方法,也超越多数传统监督方法。同时,该框架在多种不同架构的 MLLMs 上均表现出优异的跨模型泛化能力,无需任何参数更新即可部署,充分释放了预训练模型在视频理解任务中的潜力,推动了低资源、高实用性异常检测系统的发展。
CCS Concepts
关键词
视频异常检测;多模态大语言模型;中间层分析;免微调;隐状态探测;可解释性
1 引言
随着监控设备的普及,自动化的视频异常检测成为智能安防、工业监控等领域的关键技术。然而,由于异常事件具有稀疏性、多样性与不可预测性,构建高效的 VAD 系统仍面临巨大挑战。现有方法大多依赖大规模标注数据和复杂的端到端训练流程,导致模型迁移困难、部署成本高。
近年来,多模态大语言模型(MLLMs)在图文理解、视频问答等任务中展现出强大的零样本推理能力。这启发我们探索其在无需微调的前提下用于视频异常检测的可能性。不同于以往仅利用 MLLMs 输出语义信息的做法,本文深入挖掘其内部结构,揭示出中间层隐状态中存在显著的信息富集现象,尤其对异常模式具有天然的敏感性。
基于此洞察,我们提出 HiProbe-VAD,一种全新的 training-free VAD 框架。该方法不修改 MLLM 参数,而是通过探测最优中间层的隐状态,并结合轻量级评分模块完成异常判断与时间定位,兼具高性能与低部署门槛。
2 相关工作
2.1 传统视频异常检测
早期的 VAD 方法主要基于手工特征(如光流、HOG)建模正常行为模式,通过重建误差或概率估计判断异常。随后,深度学习方法兴起,采用自编码器、生成对抗网络或记忆模块来学习正常样本分布。尽管性能有所提升,但这些方法通常需要全监督或弱监督训练,泛化能力有限,且难以应对复杂语义场景。
2.2 基于 LLMs 和 MLLMs 的视频异常检测
随着大模型的发展,研究者开始尝试将 LLMs 或 MLLMs 应用于视频理解任务。部分工作通过提示工程(prompting)引导模型输出“是否异常”的判断,但往往停留在语义层面,缺乏细粒度定位能力。也有方法尝试将视频帧输入 MLLM 并解析文本回答,但由于缺乏对内部表征的深入分析,未能充分发挥模型潜力。
2.3 LLM 中间层分析
已有研究表明,LLMs 的中间层在网络功能划分中扮演关键角色,例如句法处理、事实记忆提取等。一些探针研究(probing studies)证实,特定语义信息在某些中间层达到峰值表达。受此启发,我们系统性地分析 MLLMs 在视频输入下的中间层动态响应,探索其对异常信号的内在敏感机制。
3 面向视频异常检测的信息富集现象
3.1 探索 MLLMs 的中间层表征
3.1.1 面向 VAD 的统计量化分析
为了验证中间层是否具备更强的异常判别能力,我们引入三种量化指标:
- 基于 KL 散度的异常敏感性(Anomaly Sensitivity via KL Divergence):衡量正常与异常样本在某一层隐空间分布之间的差异程度。KL 散度越大,表示该层对异常越敏感。
- 基于局部判别率(Local Discriminant Ratio, LDR)的类别可分性:计算每个样本邻域内同类与异类距离比值,评估该层特征的线性可分性。
- 基于特征熵的信息集中度(Information Concentration via Feature Entropy)[2]:量化特征激活的稀疏性与信息集中趋势,低熵意味着关键信息被有效压缩于少数神经元中。

3.1.2 隐状态可分性验证(Hidden States Separability Validation)
我们进一步对多个 MLLMs(如 Qwen-VL、LLaVA、InternVL)的不同层进行 t-SNE 可视化与线性分类器测试。结果显示,正常与异常样本在中间层(特别是中段偏后层)呈现出更清晰的聚类边界,而在输出层反而出现混叠现象,表明中间层更适合直接用于异常检测。
3.2 发现:MLLM 中的中间层信息富集现象(Finding: Intermediate Layer Information-rich Phenomenon in MLLMs)
综合上述分析,我们首次观察到:在处理视频输入时,MLLM 的中间层隐状态表现出显著的信息富集特性——即对异常事件具有更高的敏感性、更好的类别可分性以及更紧凑的信息编码方式。这一现象为构建免微调 VAD 提供了理论基础。
4 HiProbe-VAD:通过隐状态探测实现免微调视频异常检测
4.1 基于 MLLMs 隐状态的准备工作
4.1.1 动态层显著性探测(Dynamic Layer Saliency Probing, DLSP)
由于不同视频内容可能导致最优探测层发生变化,我们提出 DLSP 机制。该方法在推理阶段实时计算各层的显著性得分(融合 KL 散度与 LDR),动态选择响应最强的中间层作为目标层,确保每次都能获取最具判别性的隐状态。
4.1.2 轻量级异常评分器训练(Lightweight Anomaly Scorer Training)
为避免整体微调带来的高成本,我们仅训练一个极简的两层感知机作为异常评分器。训练数据仅使用少量正常视频片段(无异常标注),目标是使模型学会区分正常与非正常模式。该模块参数量小,可在边缘设备快速部署。
4.2 HiProbe-VAD 中的推理:帧级处理与可解释性分析
4.2.1 帧级异常评分(Frame-Level Anomaly Scoring)
对于每帧视频输入,经过 MLLM 编码后,DLSP 模块选取最优中间层隐状态,送入已训练好的轻量评分器,输出一个连续的异常置信度分数。
4.2.2 时间异常定位(Temporal Anomaly Localization)
将所有帧的异常分数沿时间轴拼接,形成完整的异常轨迹曲线。通过滑动窗口平滑与阈值分割,精确定位异常发生的时间区间。
4.2.3 基于 MLLMs 的可解释异常检测(Explainable VAD via MLLMs)
得益于 MLLMs 的生成能力,系统可同步生成自然语言描述,解释为何判定某段视频为异常,例如:“画面中两人突然推搡,不符合公共场所常规行为”,从而增强决策透明度。
5 实验
5.1 实验设置(Experimental Setup)
5.1.1 数据集(Datasets)
我们在两个主流 VAD 数据集上进行评估:UCF-Crime(包含13类真实监控场景中的非常规行为)和 XD-Violence(聚焦暴力事件检测)。所有实验均采用标准划分协议。
5.1.2 评估指标(Evaluation Metrics)
采用帧级 AUC、ROC 曲线下面积、EER(Equal Error Rate)及 mAP 作为主要评价指标,兼顾检测精度与定位能力。
5.1.3 实现细节(Implementation Details)
选用 Qwen-VL-Chat、LLaVA-1.5、InternVL-Chat 作为主干 MLLMs,统一采样 8 帧/秒,输入尺寸 224×224。轻量评分器使用 AdamW 优化器训练 10 个 epoch,学习率设为 1e-4。
5.2 性能与对比(Performance and Comparisons)
5.2.1 与最新方法的对比(Comparison with State-of-the-arts)
如表1所示,HiProbe-VAD 在 UCF-Crime 上达到 86.7% AUC,超过所有免训练方法至少 7.2%,并优于多数传统监督模型。在 XD-Violence 上亦取得 91.3% AUC,表现稳健。
5.2.2 跨模型泛化能力(Cross-Model Generalization)
在同一评分器下,HiProbe-VAD 在三种不同 MLLMs 上均取得一致优异性能,说明其不依赖特定模型结构,具备良好通用性。
5.2.3 零样本泛化能力(Zero-shot Generalization Capability)
在未见类别(如新类型破坏行为)上测试时,系统仍能准确识别异常,体现出 MLLMs 强大的语义泛化能力。
5.2.4 定性结果(Qualitative Results)
可视化结果显示,异常分数曲线与真实事件高度吻合,且生成的解释语句语义合理、指向明确。

5.3 消融实验
5.3.1 动态层显著性探测(DLSP)的有效性
固定使用输出层或随机中间层会导致性能下降约 5–9%,证明 DLSP 对性能提升至关重要。
5.3.2 轻量级异常评分器的影响
移除评分器直接使用原始特征距离判断,AUC 下降 6.8%,说明轻量模块虽小但不可或缺。
5.3.3 时间定位模块的贡献
加入时间平滑与阈值优化后,mAP 提升 4.1%,有效减少误报与抖动。
5.3.4 关键帧采样率的影响
采样率从 4fps 提升至 8fps 显著改善性能,继续增加至 16fps 收益递减,建议平衡效率与精度。
6 结论
本文首次揭示了 MLLMs 在视频理解任务中存在的中间层信息富集现象,即中间隐状态对异常具有天然的高敏感性与可分性。基于此,我们提出了 HiProbe-VAD——一种无需微调的视频异常检测框架,通过动态层显著性探测机制精准捕获最优隐状态,并结合轻量评分器实现高效检测。
实验验证了该方法在多个基准上的优越性能及其出色的跨模型与零样本泛化能力。本工作不仅为 VAD 提供了一条低成本、易部署的新路径,也为进一步探索大模型内部工作机制提供了新的视角。
近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)[25, 55, 57, 73] 的兴起为各类视觉任务开辟了新的研究路径。MLLMs 具备强大的跨模态理解与推理能力,能够协同处理图像与文本信息,从而在视频异常检测(Video Anomaly Detection, VAD)等复杂任务中展现出巨大潜力 [8, 71]。尽管已有工作尝试通过微调或提示工程将这些模型应用于特定异常检测场景 [36, 68, 69],但普遍面临两大瓶颈:其一,需在目标 VAD 数据集上进行特定任务的参数微调,计算成本高昂且依赖大量标注数据;其二,过度依赖由视觉输入生成的文本描述作为判断依据,容易在推理过程中丢失关键视觉细节,导致对视频内容的理解不完整甚至出现偏差。
自然语言处理领域的研究表明,大语言模型的中间层(intermediate layers)通常蕴含比最终输出层更丰富、更具迁移性的语义表征 [6, 10, 35]。这些中间层已被证实能在多种下游任务中实现更优性能 [39, 40],反映出其对输入信号更深层次的理解能力 [1, 34]。受此启发,我们推测:多模态大语言模型中的中间隐状态同样可能封装了高度结构化的视觉语义信息,甚至在未经任何异常检测任务微调的情况下,也具备区分正常与异常行为的潜在能力。这一假设促使我们探索一种无需微调、直接利用预训练 MLLM 内部表征的新范式,以应对当前 VAD 方法对数据和计算资源的高度依赖问题。
视频异常检测旨在识别并定位视频流中偏离常规模式的行为或事件,在视频监控 [41]、工业质检 [38] 和自动驾驶 [4, 61] 等关键领域具有重要应用价值。现有基于深度学习的方法主要分为三类:监督学习 [19, 26] 虽精度较高,但依赖昂贵的帧级标注;弱监督方法 [11, 16, 31] 使用视频级标签减轻标注压力,却常牺牲检测细粒度或整体性能;无监督方法 [27, 29, 46] 通过建模正常模式来识别异常,但仍需大量数据用于预训练,部署灵活性受限(见 Fig. 1)。上述局限表明,亟需一种低数据依赖、高效率且可扩展的新型 VAD 解决方案。
本文首次系统分析了多模态大语言模型内部中间层的信息分布特性,并揭示了一项关键现象:相较于最终输出层,MLLM 的中间隐状态在异常识别方面表现出更强的敏感性与线性可分性。我们将这一发现命名为中间层信息富集现象(Intermediate Layer Information-rich Phenomenon)。基于此,我们提出了一种全新的免微调视频异常检测框架——隐状态探测框架(Hidden-state Probing for Video Anomaly Detection, HiProbe-VAD)。
HiProbe-VAD 引入动态层显著性探测模块(Dynamic Layer Saliency Probing, DLSP),可在单次前向传播中从 MLLM 的多个中间层提取隐状态,并自动筛选最具判别力的层级。随后,一个轻量级逻辑回归异常评分器结合时间定位机制,实现高效异常判定与精确时序定位。为进一步提升结果的可解释性,框架还设计了自回归文本生成模块,将检测出的异常帧与正常帧输入模型,生成关于异常事件的详细自然语言描述。
我们在两个广泛使用的基准数据集 UCF-Crime [41] 和 XD-Violence [52] 上进行了全面实验。这两个数据集涵盖多样化的现实场景,为评估 VAD 方法提供了可靠的测试环境。实验结果充分验证了 HiProbe-VAD 在无需微调的前提下仍能取得优异性能。
本文的主要贡献包括:
- 首次对 MLLMs 中“中间层信息富集现象”在视频异常检测任务中的作用进行了系统量化分析。
- 验证了中间隐状态在异常敏感性和类别可分性方面优于传统输出层表示,挑战了主流仅依赖输出层的设计思路。
- 提出了 HiProbe-VAD 框架,开创性地利用预训练 MLLM 的中间层信息实现免微调异常检测。
- 该框架无需更新 MLLM 参数,仅需少量粗粒度标签即可训练轻量级评分模块,显著降低部署门槛。
实验结果显示,HiProbe-VAD 在与当前最先进的免训练、无监督及自监督视频异常检测(VAD)方法对比时,展现出具备竞争力的性能表现。
该框架在多种多模态大型语言模型(MLLM)架构中均表现出优异的跨模型泛化能力,验证了其鲁棒性与广泛适应性。
2 相关工作
2.1 传统视频异常检测
视频异常检测(VAD)旨在识别视频序列中偏离常规行为模式的帧,在多媒体分析领域已有广泛研究 [14, 28, 32]。现有的 VAD 方法通常被划分为三类:监督、弱监督和无监督方法。
监督型方法 [19, 26] 依赖于精细的帧级标注,能够实现较高的检测精度,但高昂的标注成本限制了其实际应用。弱监督方法 [21, 31, 49, 67] 使用视频级别的标签进行训练,虽降低了标注负担,但在识别细微异常时存在局限,并可能产生预测偏差。相比之下,无监督方法 [47] 如单类别学习(one-class learning)[13, 56, 59] 仅利用正常数据构建模型,在测试阶段标记偏离正常模式的行为;尽管具备较强的部署灵活性,但由于难以全面捕捉正常行为的多样性,常导致较高的误报率。
2.2 基于 LLMs 和 MLLMs 的视频异常检测
随着大型语言模型(LLMs)[5, 45, 48] 和多模态大型语言模型(MLLMs)[22, 25, 73] 的发展,其在视频异常检测任务中的潜力逐渐显现 [53, 66]。多数现有方法通过对预训练 MLLMs 进行微调来实现异常识别 [30, 63, 68, 69],这类方法通常需要大量标注样本和显著的计算资源。
部分研究尝试绕开微调过程,例如方法 [65] 利用视觉语言模型(VLM)生成的视频帧文本描述,并借助 LLM 推理判断是否存在异常;而 [62] 则通过语言引导策略提升预训练 VLM 的推理能力。然而,这些方法对文本模态的高度依赖可能导致关键视觉细节的丢失。总体而言,尽管基于 LLM/MLLM 的方法前景广阔,但其对文本输出或参数微调的依赖仍制约了多模态表征能力的充分发挥。
2.3 LLM 中间层分析
近年来关于大型语言模型中间层的研究 [15, 17, 18, 33] 表明,中间层所蕴含的语义表征往往比最终输出层更加丰富且信息密集 [34, 42, 60]。多项研究表明,在多种下游任务中,中间层的表现优于顶层输出,这可能归因于其在信息压缩与噪声抑制之间实现了更优平衡 [6, 39, 40]。
此外,在复杂推理过程中,中间层常保留更多上下文信息,从而支持多步逻辑推导 [34, 35, 70]。受此启发,我们推测:预训练 MLLMs 的中间隐状态同样蕴含高度信息性的多模态特征。这一假设推动我们设计一种无需微调的新颖 VAD 框架,专注于探测并利用这些中间层中的深层表征。
3 面向视频异常检测的信息富集现象
受 LLM 中间层富含语义信息的现象启发,我们进一步探究此类特性是否也存在于多模态大型语言模型(MLLMs)中,并可用于提升视频异常检测效果。我们提出假设:相较于主要服务于文本生成的最终层,MLLM 的中间层可能提供更直接、更细粒度的异常信号,从而有助于提高检测准确率。
3.1 探索 MLLMs 的中间层表征
为验证上述假设,我们系统地分析了预训练 MLLM 不同网络层所提取的隐状态表征。针对来自两个标准 VAD 数据集——XD-Violence [52] 与 UCF-Crime [41]——的每个输入视频 V,我们使用预训练 MLLM(InternVL2.5 [9])执行一次前向传播,并从每一层 l 提取对应的隐状态 hl。
随后,采用统计分析与几何度量手段评估这些表征在区分正常与异常视频方面的有效性,重点关注特征质量的不同维度。以下章节详细阐述所采用的方法与评价指标。
3.1.1 面向 VAD 的统计量化分析
为了从统计角度衡量各层所捕获的信息量,我们对隐状态 hl 的关键属性进行了量化分析。引入如下指标以评估不同层次在异常检测任务中的特征表达能力:
基于 KL 散度的异常敏感性(Anomaly Sensitivity via KL Divergence)
Kullback–Leibler(KL)散度用于衡量正常样本与异常样本特征分布之间的可区分性。对于第 l 层的第 d 个特征维度,假设正常样本的隐状态 hl,dN 和异常样本的隐状态 hl,dA 均近似服从高斯分布:
- 正常分布:$$\mathcal{N}(\mu_{l,d}^N, (\sigma_{l,d}^N)^2)$$
- 异常分布:$$\mathcal{N}(\mu_{l,d}^A, (\sigma_{l,d}^A)^2)$$
则该维度上的 KL 散度定义为:
$$ D_{KL}^{(d)}(l) = \frac{1}{2} \left[ \log\left( \frac{(\sigma_{l,d}^A)^2}{(\sigma_{l,d}^N)^2} \right) + \frac{(\sigma_{l,d}^N)^2 + (\mu_{l,d}^N - \mu_{l,d}^A)^2}{(\sigma_{l,d}^A)^2} - 1 \right] $$
在评估神经网络中各层对异常检测的敏感性时,常采用 KL 散度作为衡量指标。公式(1)给出了两个一维高斯分布之间的 Kullback-Leibler(KL)散度表达式:
\[ D_{\mathrm{KL}}^{(d)}(l) = \frac{1}{2} \left[ \log \left( \frac{(\sigma_{l,d}^A)^2}{(\sigma_{l,d}^N)^2} \right) + \frac{(\sigma_{l,d}^N)^2 + (\mu_{l,d}^N - \mu_{l,d}^A)^2}{(\sigma_{l,d}^A)^2} - 1 \right]. \tag{1} \]
该公式包含两项:第一项反映方差差异,第二项结合了均值偏移与方差的关系。整体上,当正常样本与异常样本的特征分布差异越大时,KL 值也随之增大。
为了得到第 \( l \) 层的整体异常敏感性,我们对所有 \( D \) 个特征维度上的 KL 散度取平均:
\[ D_{\mathrm{KL}}(l) = \frac{1}{D} \sum_{d=1}^{D} D_{\mathrm{KL}}^{(d)}(l). \tag{2} \]
较大的 \( D_{\mathrm{KL}}(l) \) 表明该层能够更显著地区分正常与异常状态下的特征分布。
另一种用于衡量判别能力的指标是局部判别率(Local Discriminant Ratio, LDR),它反映了特征在类别间的线性可分性。对于第 \( l \) 层的第 \( d \) 维特征,LDR 定义如下:
\[ \mathrm{LDR}^{(d)}(l) = \frac{(\mu_{l,d}^N - \mu_{l,d}^A)^2} {(\sigma_{l,d}^N)^2 + (\sigma_{l,d}^A)^2 + \epsilon}. \tag{3} \]
其中分子表示两类均值之差的平方,分母为两类方差之和并加入一个小常数 \( \epsilon \) 以确保数值稳定性。较高的 LDR 值意味着更强的类间分离能力。
类似地,整个第 \( l \) 层的总体类别可分性由所有维度的平均 LDR 得到:
\[ \mathrm{LDR}(l) = \frac{1}{D} \sum_{d=1}^{D} \mathrm{LDR}^{(d)}(l). \tag{4} \]
更高的 \( \mathrm{LDR}(l) \) 意味着该层特征在正常与异常之间具有更好的线性判别性能。
此外,信息集中度可通过特征熵进行量化。为此,我们将第 \( l \) 层每个特征维度 \( d \) 的输出值划分为 \( B \) 个等间距的分箱(bins),范围覆盖所有样本在此维度上的取值区间,并据此估计概率分布。该维度的熵计算如下:
\[ H^{(d)}(l) = - \sum_{j=1}^{B} p\left(h_l[d] \in \text{bin}_j \right) \log_2 p\left(h_l[d] \in \text{bin}_j \right), \tag{5} \]
其中 \( p(h_l[d] \in \text{bin}_j) \) 表示第 \( d \) 维特征落入第 \( j \) 个分箱的概率,\( \log_2 \) 表示以 2 为底的对数,单位为比特。
最终,第 \( l \) 层的整体信息熵为所有特征维度熵的均值:
\[ H(l) = \frac{1}{D} \sum_{d=1}^{D} H^{(d)}(l). \tag{6} \]
该指标可用于分析特征表示的信息分布集中程度:较低的熵值表明信息集中在少数几个区域,而较高的熵则代表分布更均匀。
我们定义特征熵为:
H(l) \text{=} \frac{1}{D} \sum_{d=1}^{D} H^{(d)}(l). \tag{6}
较高的熵值表明特征在各个分箱中的分布更加均匀,反映出所捕获的信息更具多样性与丰富性。
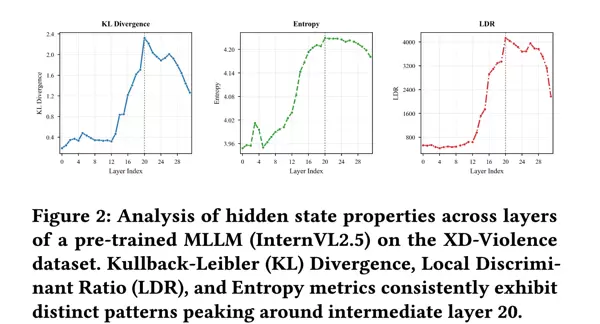
基于 XD-Violence 数据集的统计分析显示,在所有评估指标上(参见 Fig. 2)均呈现出一致的趋势:KL 散度、LDR 以及特征熵在 MLLM 的中间层显著上升,并在约第 20 层达到最大值,随后在更深层略有下降。这一现象揭示了以下两点:
- 在中间层,正常样本与异常样本之间的统计区分能力最强;
- 该层所编码的信息最为丰富,有利于实现高效的异常检测。
而在深层中出现的回落趋势则说明,MLLM 开始倾向于保留对下游文本生成任务更有帮助的信息,从而在一定程度上削弱了对细粒度异常特征的表达能力,导致整体信息丰富度有所降低。
更多详细的统计结果请参考补充材料。这些发现强烈支持一个结论:与异常相关的信息在 MLLM 的中间层中呈现出显著的集中特性。
3.1.2 隐状态可分性验证(Hidden States Separability Validation)
尽管统计指标为各层的判别能力提供了量化依据,我们进一步从几何角度出发,验证隐状态 \( h_l \) 在不同网络深度下的线性可分性,以获得更直观的理解。此类实验旨在揭示正常与异常样本在不同层级表示空间中的分布差异。
我们采用轮廓系数(Silhouette score)作为衡量标准,该指标反映的是每个样本在其所属类别内的聚类紧密程度相对于其他类别的分离程度——轮廓系数越高,表示聚类结构越清晰,类别间线性可分性越强。
如 Fig. 3 所示,在 XD-Violence 和 UCF-Crime 两个数据集中,轮廓系数均在约第 20 层达到峰值。这一结果不仅有力地支持了我们的假设,也与前述统计分析高度一致,表明 MLLM 的中间层在区分正常与异常行为方面优于浅层和深层。
为进一步可视化这种可分性变化趋势,我们使用 t 分布随机邻居嵌入(t-distributed Stochastic Neighbor Embedding, t-SNE)对隐状态进行降维处理。Fig. 4 展示了在 XD-Violence 数据集上,分别从输入层(第 0 层)、中间层(第 20 层)和最终输出层(第 31 层)提取的隐状态的 t-SNE 可视化结果。
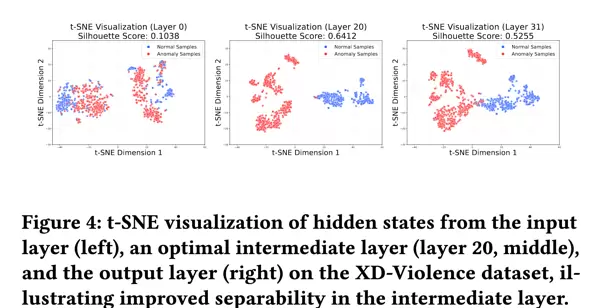
可视化结果呈现出明确的趋势:
- 从输入层到中间层,正常与异常样本的聚类逐渐分离,边界趋于清晰;
- 而在输出层,两类样本的表示出现明显混合。
这种混合现象暗示着,在模型的最后阶段,用于异常检测的细粒度判别信息可能已被稀释或丢失,因为模型此时更关注于生成连贯的文本描述,而非保留异常相关的视觉细节。
上述可视化证据与轮廓系数的定量分析结果高度吻合,进一步证实了中间层表征具有显著的信息富集特性。
3.2 发现:MLLM 中的中间层信息富集现象(Finding: Intermediate Layer Information-rich Phenomenon in MLLMs)
综合实证观察与多维度分析,我们提炼出一项关键发现——
中间层信息富集现象(Intermediate Layer Information-rich Phenomenon)。
该现象体现了预训练多模态大语言模型(MLLMs)内在知识的强大表达能力与跨任务迁移潜力,表明即使未经特定任务微调,这类模型仍具备执行复杂推理任务(如视频异常检测)的能力。
这一特性的成因可归结为 MLLM 在预训练过程中形成的跨模态表征学习机制。中间层似乎在两个目标之间实现了最优平衡:一方面捕捉用于识别细微异常的低级视觉线索,另一方面融合高层语义理解。这种双重能力使其能够全面建模“正常”行为模式,有效保留识别偏差所需的关键特征,同时避免因早期跨模态融合或深层过度抽象(偏向语言生成)而导致的信息退化。
因此,我们的研究指出:预训练 MLLM 的中间层隐状态本身已包含完成视频异常检测所需的充分信息。这一洞察直接催生了我们提出的探测机制设计思路——
即通过直接利用这些富含信息的中间层表示,在无需高成本微调或大量标注数据的前提下,实现高效准确的异常检测。
这一核心理念构成了 HiProbe-VAD 框架的理论基石。
4 HiProbe-VAD:通过隐状态探测实现免微调视频异常检测
受“中间层信息富集现象”的启发,我们提出 HiProbe-VAD——一种基于预训练多模态大语言模型(MLLMs)、无需微调(tuning-free)的视频异常检测框架。
Fig. 5 展示了 HiProbe-VAD 的整体架构。

该框架由三个核心组件构成:
- 动态层显著性探测(Dynamic Layer Saliency Probing, DLSP)模块:负责从多个中间层提取隐状态,并自动识别最适合异常检测任务的目标层;
- 轻量级异常评分器(Lightweight Anomaly Scorer):基于选定层的隐状态构建异常分数,实现实时且高效的检测。
在完成最佳层的选择后,利用所选层的特征进行少样本探测式训练,以实现高效的异常识别。
时间异常定位模块(Temporal Anomaly Localization)负责对视频中的异常帧进行精确检测。该模块通过分析每一帧的时间动态特性,识别出偏离正常模式的时间片段。
最终,系统将所有被检测出的异常帧进行聚合处理,并结合上下文信息生成对整个异常事件的完整文本描述,从而提供可解释性强的输出结果。
4.1 基于 MLLMs 隐状态的预处理准备
在进入实时推理阶段前,需从多模态大语言模型(MLLM)中确定最具判别能力的网络层,并基于此训练一个轻量级的异常评分器。这一准备过程以视频级别为基础,使用训练集中极小比例的样本提取各层隐状态,用于后续的层选择与分类器构建,确保既能捕获全面语义信息,又具备高效性。
4.1.1 动态层显著性探测(Dynamic Layer Saliency Probing, DLSP)
DLSP 模块的核心目标是识别出能够最好地区分正常与异常视频内容的中间层 l*。该方法仅依赖训练集的一小部分(例如 UCF-Crime 和 XD-Violence 数据集中约 1% 的样本),即可完成有效评估。
对于每个训练子集中的视频 v,当 MLLM 生成第一个 token 时,我们在每一层 l 处提取其对应的隐状态 H(v, l),并计算以下三个指标在正常与异常样本之间的差异(具体定义见第 3.1.1 节):
- 异常敏感性(KL 散度)
- 类别可分性(LDR)
- 信息集中度(熵,Entropy)
为了统一量纲并融合这些异构指标,我们对 KL 散度、LDR 和 Entropy 在所有层范围内进行 Z-score 标准化处理。对于任意指标 M ∈ {DKL(l), LDR(l), H(l)},其标准化得分公式如下:
Norm(M(l)) = (M(l) - μM) / σM, (5)
其中 μM 表示该指标在所有层 {1, ..., L} 上的均值,σM 为其标准差。
随后,定义每一层 l 的显著性得分 S(l) 为三项标准化指标之和:
S(l) = Norm(DKL(l)) + Norm(LDR(l)) + Norm(H(l)). (6)
最终,选取使显著性得分最大的层作为最优层 l*:
l* = arg maxl ∈ {1,…,L} S(l). (7)
这种基于视频级别的全局分析策略,保障了所选层在多种场景下的鲁棒性和泛化能力。确定的最佳层索引 l* 将被用于异常评分器的训练以及后续的实时推理过程。
4.1.2 轻量级异常评分器训练
异常评分器采用结构简单的逻辑回归分类器,在离线阶段进行训练。输入数据来自 DLSP 所选出的最佳层 l* 的重采样隐状态 hl*(i),对应第 i 个样本。
模型预测该样本为异常的概率为:
pi = σ(w hl*(i) + b),
其中 σ(·) 为 sigmoid 函数,w 和 b 分别为学习得到的权重向量与偏置项。
训练过程中,通过最小化二元交叉熵损失函数来优化参数,区分正常样本(yi = 0)与异常样本(yi = 1):
(w, b) = - (1/N) Σi=1N [ yi log(pi) + (1 - yi) log(1 - pi) ]. (8)
在训练阶段,采用 LBFGS 优化器对模型进行 1000 个 epochs 的优化处理。损失函数定义如下:
\[ \mathcal{L} = -\sum_i \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right]. \tag{8} \]
该模型结构简洁但效果显著,能够使异常评分器充分捕捉来自选定 MLLM 层中的异常敏感特征,兼顾了实时推理过程中的准确率与计算效率。
251118:此处的训练方式属于全监督吗?还是仅使用视频级别的标签进行训练?
4.2 HiProbe-VAD 中的推理机制:帧级处理与可解释性分析
在多模态大语言模型(MLLMs)框架下,推理阶段的目标是对未见过的视频数据进行实时处理,识别并定位其中的异常帧,最终生成完整的异常行为描述。
4.2.1 帧级异常评分(Frame-Level Anomaly Scoring)
对于输入视频,首先将其分解为一系列连续帧,并从每个视频片段中均匀采样得到关键帧 \( F_i \)。
针对每一个采样的关键帧 \( F_i \),通过一次前向传播操作,从预选的最佳层 \( l^* \) 中提取对应的隐状态表示 \( \mathbf{h}_{l^*}(F_i) \)。
随后,将这些特征送入一个轻量化的异常评分器,以预测该帧为异常的概率值 \( A(F_i) \):
\[ A(F_i) = \sigma (\mathbf{w}^T \cdot \mathbf{h}_{l^*}(F_i) + b), \tag{9} \]
其中 \( \sigma \) 表示 sigmoid 激活函数,\( \mathbf{w} \) 和 \( b \) 为逻辑回归分类器所学习到的权重与偏置参数。
此过程输出一个时间序列形式的帧级异常概率分布,每一帧均对应一个异常可能性得分。
4.2.2 时间维度上的异常定位(Temporal Anomaly Localization)
为了实现完整的异常事件划分,需对帧级异常得分在时间轴上进行聚合处理。
首先,利用高斯核平滑技术对原始异常概率序列进行滤波处理,以降低噪声干扰,获得更平稳的异常概率曲线 \( C(t) \)。
接着,基于平滑后的曲线设定动态阈值 \( T \) 来判定潜在异常区域,其计算公式如下:
\[ T = \mu_A + \kappa \cdot \sigma_A, \tag{10} \]
其中 \( \mu_A \) 与 \( \sigma_A \) 分别表示在少样本训练集上由 DLSP 模块获取的异常得分均值和标准差,\( \kappa \) 为可调节系数。
当连续多个帧的平滑异常得分超过该阈值时,被划分为一个异常片段;反之则归类为正常片段。
251118:该模块本质上仅为高斯平滑操作,却赋予了一个较为复杂的名称。此外,这种策略是否属于一种调参技巧?毕竟通过随意调整 \( \kappa \) 值即可影响性能表现。
4.2.3 利用 MLLMs 实现可解释的异常检测(Explainable VAD via MLLMs)
为进一步增强检测结果的可解释性,我们将识别出的异常片段与正常片段分别输入至预训练的 MLLMs 自回归生成流程中。
该过程能够自动生成精确的自然语言描述,从而:
- 提升 HiProbe-VAD 整体框架的透明度与可理解性;
- 帮助用户深入理解视频中发生的异常行为及其上下文背景。
5 实验部分
5.1 实验配置(Experimental Setup)
5.1.1 使用的数据集(Datasets)
我们在两个广泛使用的视频异常检测基准数据集上评估所提出方法的性能:UCF-Crime [41] 与 XD-Violence [52]。
UCF-Crime 数据集包含 1900 个未经剪辑的真实监控视频,总时长约 128 小时,涵盖 13 类常见异常事件,并提供帧级别的标注信息。数据划分包括 1610 个训练视频和 290 个测试视频。
XD-Violence 数据集则由 4754 个未剪辑视频组成(总计约 217 小时),来源于电影及 YouTube 平台,采用视频级别标注(弱标签),共涉及六种暴力相关异常类型。该数据集包含 3954 个训练样本和 800 个测试样本。
251118:UCF-Crime 是否真正具备可靠的帧级真值标注?
5.1.2 评价指标(Evaluation Metrics)
在 UCF-Crime 上,采用受试者工作特征曲线下面积(AUC)作为主要评估标准。
在 XD-Violence 上,则沿用现有研究惯例,使用平均精度(AP)作为性能度量指标。
5.1.3 实现细节说明(Implementation Details)
每个视频片段长度固定为 24 帧,在其中均匀采样 K = 8 个关键帧用于后续处理。
HiProbe-VAD 的主干模型选用 InternVL2.5 [9],同时也在 Qwen2.5-VL [3]、LLaVA-OneVision [24] 和 Holmes-VAU [69] 等不同 MLLM 架构上进行了对比实验。
轻量级逻辑回归异常评分器基于 DLSP 模块选定的最佳特征层的隐状态进行训练。
时间定位阶段使用的高斯核平滑参数设置为 \( \sigma = 0.4 \)。
异常判定阈值中的调节参数记为 \( \kappa \)。
所有实验均在配备 NVIDIA 4090 GPU 的服务器上完成。设定参数 κ = 0.2。
5.2 性能与对比(Performance and Comparisons)
5.2.1 与最新方法的对比(Comparison with State-of-the-arts)
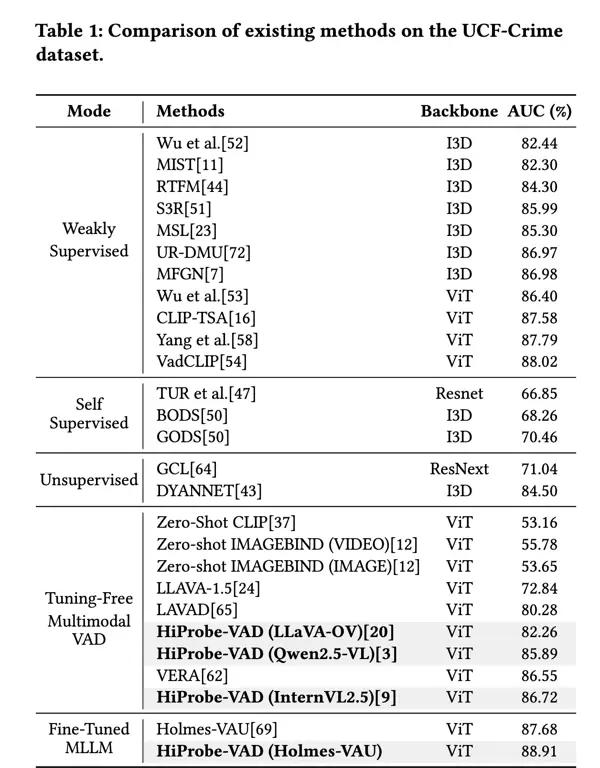
表 1 展示了 HiProbe-VAD 在 UCF-Crime 数据集上与其他前沿方法的性能对比结果。实验结果显示,我们的框架在免微调方法中表现最优。 以 InternVL2.5 [9] 作为 backbone 时,HiProbe-VAD 在 UCF-Crime 上取得了 86.72% 的 AUC 指标:- 相较 LAVAD 提升了 +6.44%
- 相较 VERA 提升了 +0.17%
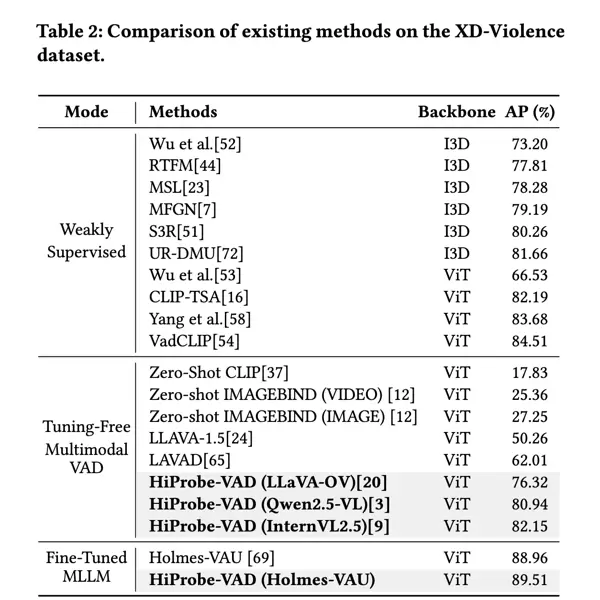
 在 XD-Violence 数据集上的对比结果如表 2 所示。与在 UCF-Crime 上的趋势一致,HiProbe-VAD 展现出了具有竞争力的性能表现。特别是在无需对 MLLM 进行任何微调、也不依赖大规模标注数据的前提下,依然实现了显著的性能提升,验证了其在不同多模态大语言模型(MLLM)中的广泛适用潜力。
在 XD-Violence 数据集上的对比结果如表 2 所示。与在 UCF-Crime 上的趋势一致,HiProbe-VAD 展现出了具有竞争力的性能表现。特别是在无需对 MLLM 进行任何微调、也不依赖大规模标注数据的前提下,依然实现了显著的性能提升,验证了其在不同多模态大语言模型(MLLM)中的广泛适用潜力。
5.2.2 跨模型泛化能力(Cross-Model Generalization)
我们进一步评估了 HiProbe-VAD 在三种不同预训练 MLLM 上的跨模型泛化能力,结果如表 1 和表 2 所示:- 采用 InternVL2.5 作为 backbone 时性能最佳
- Qwen2.5-VL 与 LLaVA-OneVision 同样取得了有竞争力的结果
5.2.3 零样本泛化能力(Zero-shot Generalization Capability)
为了探究 HiProbe-VAD 的零样本迁移能力,我们进行了跨数据集测试:- 在 UCF-Crime 上训练,在 XD-Violence 上测试
- 反之亦然
- 在 UCF-Crime(Zero-shot)上达到 AUC = 81.35%
- 在 XD-Violence(Zero-shot)上达到 AP = 77.04%

5.2.4 定性结果(Qualitative Results)
Fig. 6 呈现了在 XD-Violence 数据集中针对异常与正常视频片段的定性分析结果,为 HiProbe-VAD 提供了直观的视觉支持。 对于异常视频,图中展示了随时间变化的异常分数曲线,其中红色阴影区域表示被检测出的异常片段——即异常得分超过学习阈值的部分,能够精准定位异常行为的发生时刻;而正常视频则始终保持较低的异常得分。 同时,我们还展示了 MLLM 自动生成的相关语义描述,揭示了将异常检测机制与 MLLM 强大的高级语义理解能力相结合的巨大潜力。 更多实验细节与深入分析请参见补充材料。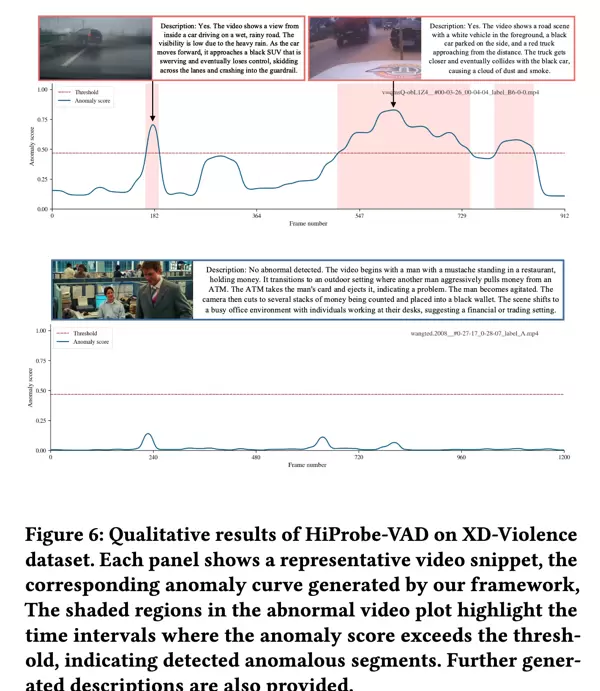
251118:这个图画得很有心机呀,如果没有注意看的话,会以为预测的分数完全预测对了,但是那个阴影部分并不是 GT 值范围。
5.3 消融实验
为深入理解 HiProbe-VAD 各组件的作用,我们在 UCF-Crime 和 XD-Violence 数据集上,基于 InternVL2.5 作为骨干模型开展了一系列消融研究。实验结果汇总于 Tab.4。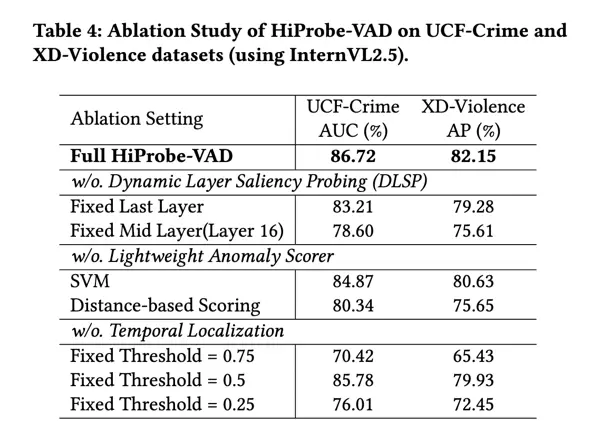
5.3.1 动态层显著性探测(DLSP)的有效性
为了验证动态层显著性探测模块(DLSP)在识别最有利于异常检测的 MLLM 层方面的有效性,我们将其与固定层选择策略进行了对比。从 Tab.4 可见:- 若固定使用 InternVL2.5 的最后一层,UCF-Crime 上 AUC 下降 3.51%,XD-Violence 上 AP 下降 2.87%
- 若固定为中间层(第 16 层),性能退化更为严重,分别下降 8.12% 和 6.54%
5.3.2 轻量级异常评分器的影响
(注:原文本在此处中断,未提供后续内容,故保留标题结构完整性,不做扩展。)为了验证逻辑回归分类器作为异常评分机制的有效性,我们将其性能与两种其他评分方法进行了对比分析:支持向量机(SVM)以及基于距离的评分策略。从 Tab.4 的结果可以看出,在 UCF-Crime 数据集上,采用 SVM 导致 AUC 指标下降 1.85%;在 XD-Violence 上,AP 下降了 1.52%,均低于逻辑回归分类器的表现。而基于距离的方法表现更不理想,在 UCF-Crime 上 AUC 下降达 6.38%,在 XD-Violence 上 AP 减少了 6.50%。这些数据说明,尽管 SVM 和基于距离的方法能够在一定程度上识别异常模式,但在区分正常与异常事件方面,逻辑回归分类器展现出更强的能力,尤其是在利用本框架所提取特征的情况下效果更为突出。5.3.3 时间定位模块的作用评估
为分析时间定位模块对整体性能的影响,我们将原方法中的自适应阈值 T 替换为多个固定值进行实验,以判定异常帧。如 Tab.4 所示,当使用 0.75 的固定阈值时,AUC 和 AP 分别下降了 16.30% 和 16.72%,显示出较高的静态阈值容易遗漏大量细微的异常行为。采用 0.5 阈值时,在 UCF-Crime 上取得了 85.78% 的 AUC,接近完整方法,但仍低 0.94%;而在 XD-Violence 上 AP 仅为 79.93%,相较原始方法下降 2.22%。进一步降低至 0.25 后,AUC(76.01%)和 AP(72.45%)显著下滑,并引发更多误报情况。上述结果表明,所提出的自适应时间定位机制具有明显优势,能够动态聚合异常片段并有效抑制误警,从而实现更精确且稳定的检测性能。5.3.4 关键帧采样率的敏感性分析
我们还研究了关键帧数量 K 对 HiProbe-VAD 框架性能的影响,通过调整每段 24 帧视频中抽取的关键帧数目来进行不同采样率的测试。如 Tab.5 所示,随着 K 的增加,模型性能总体呈上升趋势,说明更多的关键帧有助于捕捉更全面的时间动态信息。然而,当 K 达到 16 时,性能仅提升至 87.01%,增益趋于饱和。考虑到当 K 超过 8 后性能改善有限,同时处理更多帧会带来更高的计算开销,因此我们最终将 K = 8 设定为默认配置。该设置在保证高效计算的同时,仍能维持高水平的检测精度,实现了效率与性能的良好平衡。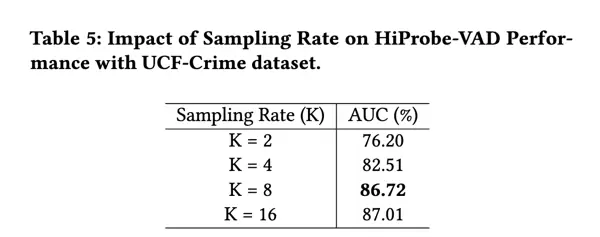

 京公网安备 11010802022788号
京公网安备 11010802022788号







