


 雷达卡
雷达卡



在办公自动化场景中,若频繁涉及浏览器操作,如批量上传数据至网页平台,可借助
库来实现自动化处理。该工具专用于 Web 应用测试,能够依据脚本指令自动执行页面点击、文本输入、页面跳转及内容验证等动作,广泛支持主流浏览器环境,包括 Chrome、Firefox、Safari、Opera、IE 等。selenium
与
库不同,requests
是基于浏览器驱动程序运行的,通过调用实际浏览器内核进行操作。由于其具备完整的网页渲染能力,因此不仅能模拟用户行为,还能高效提取页面渲染后的动态数据信息。seleniumselenium
1. 使用 selenium 库前的准备工作
(1)selenium 驱动浏览器的基本原理
浏览器依赖于浏览器内核对网页代码进行解析和展示。例如,360 浏览器与 Chrome 浏览器均采用 Chromium 内核。虽然
可以控制这些内核,但必须安装对应版本的 WebDriver 驱动程序,才能实现对浏览器行为的精准操控。每个浏览器都有专属的 WebDriver,也称为“驱动程序”,用于建立自动化控制通道。selenium
(2)安装 WebDriver
以 Microsoft Edge 浏览器为例说明驱动程序的安装流程:
- 首先查看当前浏览器的版本信息:
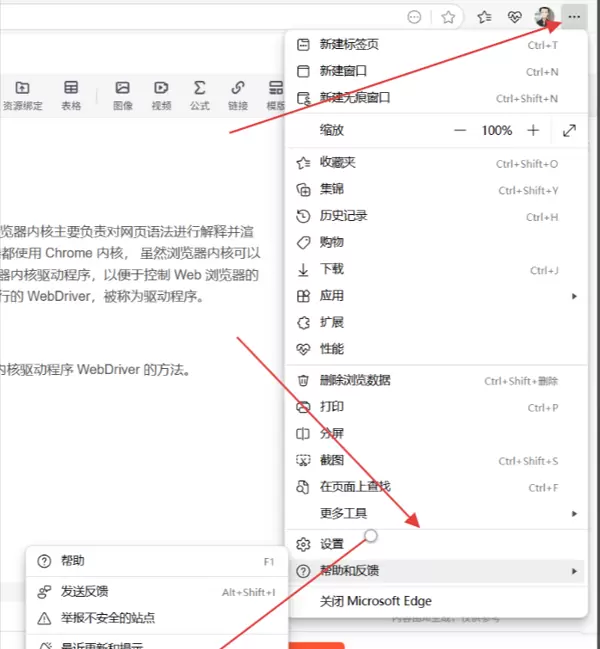

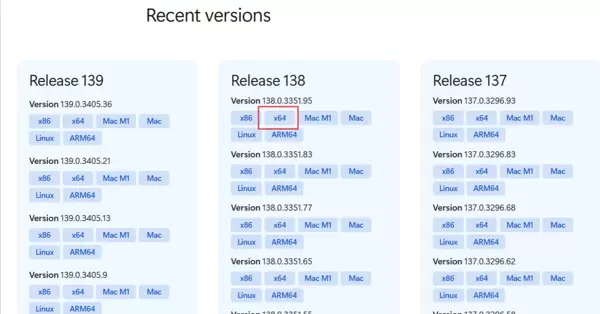
- 访问官方资源页面:Microsoft Edge WebDriver | Microsoft Edge Developer,根据显示的版本号下载对应的驱动包。
- 解压下载文件,将 msedgedriver.exe 文件复制到 Python 安装路径下的 Scripts 目录中,例如:
C:\Users\DELL\AppData\Local\Programs\Python\Python39\Scripts
完成上述步骤后,即表示驱动程序已成功配置。
(3)安装 selenium 库
打开命令提示符或终端,执行以下命令安装核心库:
pip install selenium
2. 启动并驱动浏览器
支持多种浏览器类型,涵盖桌面端与移动端主流浏览器,如 Chrome、Firefox、Edge、IE(7~11)、Safari、Opera、HtmlUnit 和 PhantomJS 等。所有可用浏览器类型可在 selenium
库源码目录下的 selenium
模块中查阅。webdriver
调用方式遵循统一格式:
webdriver.浏览器类型名()
例如启动 Edge 浏览器的标准写法为:
webdriver.Edge(),
当执行
时,系统会默认加载 webdriver.Edge()
文件中的 Edge/webdriver.py
类。WebDriver
其常用语法结构如下:
webdriver.Edge(executable_path = "chromedriver", port = 0, options = None)
功能说明:创建一个新的 Edge 浏览器驱动实例。
参数详解:
:指定浏览器驱动程序的路径,默认从系统环境变量中查找executable_path
。若未设置环境变量,或计算机中存在多个浏览器版本,可通过此参数明确指定驱动位置。path
:定义服务监听端口。若设为 0,则自动选用一个空闲端口。port
:传入由options
类(位于Options
)构建的配置对象,用于定制浏览器行为。selenium/webdriver/edge/options.py
示例代码:
from selenium import webdriver from selenium.webdriver.edge.options import Options edge_options = Options() edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe" driver = webdriver.Edge(options=edge_options)
第 3 行代码通过 Options 类创建了 edge_options 对象,并使用 binary_location 方法绑定目标浏览器可执行文件路径;第 5 行则利用 webdriver.Edge() 初始化驱动,传入选项参数。运行后将自动打开 Edge 浏览器,完成初步驱动。
3. 加载网页内容
通过 webdriver.Chrome 类创建的浏览器驱动对象提供了丰富的操作方法。该类继承自 WebDriver 基类,而 WebDriver 类定义于 selenium 库的 webdriver\remote\webdriver.py 文件中。
WebDriver 类的简要定义:
class WebDriver(object):
def __init__(self, ...):
self.file_detector = ...
def name(self):
...
def start(self):
...
def start_client(self):
...
def stop_client(self):
...
def start_session(self, ...):
...
def create_web_element(self, ...):
...
def execute(self, ...):
...
def get(self, url):
...
# 打开指定的URL页面
def title(self):
...
# 获取并返回当前页面的标题信息
def current_url(self):
...
# 返回当前浏览器窗口中加载页面的完整URL地址
def page_source(self):
...
# 获取当前页面的HTML源码内容
def close(self):
...
# 关闭当前浏览器窗口或标签页
def quit(self):
...
# 退出整个WebDriver驱动进程,关闭所有与之关联的窗口
def current_window_handle(self):
...
# 返回当前活动窗口的唯一标识句柄(每个标签页对应一个句柄)
def window_handles(self):
...
# 返回当前会话中所有打开窗口的句柄集合
def maximize_window(self):
...
# 将当前浏览器窗口最大化显示
def fullscreen_window(self):
...
# 将当前窗口切换为全屏模式,调用系统级全屏操作
def minimize_window(self):
...
# 最小化当前浏览器窗口
def switch_to(self):
...
# 提供可切换目标的对象,如frame、window、alert等操作入口
def back(self):
...
# 导航至浏览器历史记录中的上一页
def find_element_by_id(self, id_):
...
# 根据HTML元素的id属性定位单个网页元素
def find_elements_by_id(self, id_):
...
# 根据HTML元素的id属性定位多个匹配的网页元素
def find_element_by_name(self, name):
...
# 通过标签的name属性查找页面中第一个匹配的元素
def find_elements_by_name(self, name):
...
# 通过标签的name属性查找页面中所有匹配的元素
def find_element_by_tag_name(self, name):
...
# 依据HTML标签名称获取页面中的单个元素
def find_elements_by_tag_name(self, name):
...
# 依据HTML标签名称获取页面中所有符合该标签名的元素
def find_element_by_class_name(self, name):
...
# 通过class属性值定位页面中的一个元素(支持单一类名)
def find_elements_by_class_name(self, name):
...
# 通过class属性值定位页面中所有具有指定类名的元素
def find_element_by_link_text(self, link_text):
...
# 根据超链接的完整文本内容精确匹配并获取一个链接元素
def find_elements_by_link_text(self, link_text):
...
# 根据超链接的完整文本内容匹配并获取所有对应的链接元素
def find_element_by_partial_link_text(self, link_text):
...
# 利用部分链接文本来模糊匹配并查找第一个符合条件的链接元素
def find_elements_by_partial_link_text(self, link_text):
...
# 利用部分链接文本进行模糊匹配,查找所有相关的链接元素
def find_element_by_xpath(self, xpath):
...
# 使用XPath表达式来定位页面中的某个特定元素(XPath是一种用于在XML和HTML中导航节点的语言)
def find_elements_by_xpath(self, xpath):
...
# 使用XPath表达式查找页面中所有满足条件的元素
def find_element_by_css_selector(self, css_selector):
...
# 通过CSS选择器语法定位页面中的一个元素
def find_elements_by_css_selector(self, css_selector):
...
# 通过CSS选择器语法获取页面中多个符合规则的元素
def execute_script(self, script, *args):
...
# 在当前窗口或frame中同步执行JavaScript代码
def execute_async_script(self, script, *args):
...
# 在当前上下文中异步执行JavaScript脚本,适用于需要等待回调的操作
在自动化测试中,浏览器操作提供了多种方法来控制页面行为与会话状态。以下为常用功能的实现方式:
页面导航与刷新
forward():在浏览器历史记录中前进一个页面。
refresh():重新加载当前显示的网页内容。
Cookie 管理相关方法
get_cookies():获取当前会话中所有可见的 Cookie,返回结果为字典组成的列表。
get_cookie(name):根据指定名称获取单个 Cookie 的信息。
delete_cookie(name):移除会话中具有特定名称的 Cookie。
delete_all_cookies():清除该会话下的全部 Cookie 数据。
add_cookie(cookie_dict):向当前会话添加一个新的 Cookie,参数需为符合规范的字典格式。
等待机制设置
implicitly_wait(time_to_wait):设定隐式等待时间,用于等待元素出现或命令执行完成。
set_script_timeout(time_to_wait):配置异步脚本执行的最大等待时长。
set_page_load_timeout(time_to_wait):定义页面完全加载的最长容忍时间,超时则抛出异常。
元素查找方法
find_element(by=By.ID, value=None):依据给定的定位策略和值,查找第一个匹配的页面元素。
find_elements(by=By.ID, value=None):返回所有符合定位条件的元素集合。
驱动信息与窗口操作
desired_capabilities():返回当前 WebDriver 实例所使用的浏览器能力配置。
set_window_size(width, height, windowHandle='current'):调整浏览器窗口的尺寸。
get_window_size(windowHandle='current'):获取当前窗口的宽度与高度数值。
set_window_position(x, y, windowHandle='current'):设置浏览器窗口在屏幕中的位置坐标。
截图功能实现
get_screenshot_as_file(filename):将当前页面视图保存为 PNG 格式的图像文件。
save_screenshot(filename):功能同上,以文件形式存储屏幕快照。
get_screenshot_as_png():以二进制数据流的形式获取截图内容。
get_screenshot_as_base64():获取当前页面截图,并编码为 Base64 字符串格式。
常见网页加载方式介绍
1. get() 方法
此方法用于直接访问目标网址。语法结构如下:
driver.get(url)
示例代码:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r""
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/periodical")
上述第6行调用 get() 方法打开人民邮电出版社官网的期刊页面,运行后将自动启动 Edge 浏览器并加载对应网页内容。
2. execute_script() 方法
该方法可用于执行 JavaScript 脚本,常用于在同一浏览器中打开新标签页。其基本语法为:
driver.execute_script(script, *args)
其中,script 参数为要执行的 JavaScript 代码字符串。例如,使用 "window.open('网址 url','_blank');" 可实现在新标签页中打开指定链接。
示例代码片段:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r""
driver = webdriver.Edge(options=chrome_options)
第7至第9行代码调用 execute_script() 方法,执行JavaScript脚本,在浏览器中打开新的标签页。分别访问的页面包括:人民邮电出版社的登录界面、数艺设官方网站首页,以及数艺设的课程展示页面。
4. 获取渲染完成后的网页源码
当使用 get() 方法加载指定网址后,浏览器会自动对页面进行完整渲染。此时若需获取经过JavaScript执行和DOM更新后的最终页面结构,可调用 page_source 属性来提取当前页面的完整HTML内容。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r""
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/')
print(driver.page_source)如上述代码所示,第7行通过 driver.page_source 获取由 get() 方法加载并渲染完毕后的网页源代码。
5. 网页元素的定位与操作
(1)定位页面中的特定元素
在成功加载网页后,可以通过Selenium提供的多种方法查找页面中的具体元素,并对其进行交互操作。常用的元素操作方法包括:
tag_name():返回该元素的HTML标签名称。text():获取元素内部的文本内容。click():模拟鼠标点击该元素。submit():用于提交包含表单的元素。send_keys(value):向输入框等可编辑元素中输入内容。size():获取元素在页面上的尺寸(宽高)。
更多可用的操作函数可在Selenium库的源文件路径 webdriver\remote\webelement.py 中查阅。
(2)向元素输入内容
使用 send_keys() 方法可以向目标元素(如输入框)发送指定文本信息。其基本语法格式如下:
send_keys(value)示例代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
edge_options = Options()
edge_options.binary_location = r""
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/')
driver.find_element_by_tag_name("input").send_keys("Python")其中,第8行代码通过 find_element_by_tag_name("input") 定位页面中标签名为 input 的元素——根据网页源码分析,此元素通常对应搜索框。随后调用 send_keys("Python") 实现自动输入“Python”字符串的功能。
需要注意的是,不同网站的搜索框可能使用不同的HTML标签或属性,因此在实际应用前应先查看目标页面的源代码以确认准确的定位方式。
进一步地,在实现文本输入的基础上,还可以结合按键模拟功能,模拟用户按下回车等操作。例如:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.keys import Keys
edge_options = Options()
edge_options.binary_location = r""
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/")
driver.find_element_by_tag_name("input").send_keys("Python" + Keys.RETURN)该段代码在输入“Python”之后,紧接着触发回车键(Keys.RETURN),实现自动提交搜索请求的效果,更贴近真实用户行为。
相较于之前的代码,本次修改仅针对第 8 行进行了调整。改动的内容是在 send_keys() 方法中加入了 Keys.RETURN 参数。其中,Keys.RETURN 代表按下键盘上的 Enter 键,该常量来源于第 3 行所导入的 Keys 类。在 Keys 类中,包含了多种常见按键对应的转义字符定义,便于自动化操作时模拟键盘输入行为。
以下是 Keys 类在其源码中的部分按键定义内容展示:
class Keys(object):
"""
包含一系列特殊按键的编码。
"""
NULL = '\ue000'
CANCEL = '\ue001' # ^break
HELP = '\ue002'
BACKSPACE = '\ue003'
TAB = '\ue004'
CLEAR = '\ue005'
RETURN = '\ue006'
ENTER = '\ue007'
SHIFT = '\ue008'
LEFT_SHIFT = '\ue009'
CONTROL = '\ue00a'
LEFT_CONTROL = '\ue00b'
ALT = '\ue00c'
LEFT_ALT = '\ue00d'
PAUSE = '\ue00e'
ESCAPE = '\ue00f'
SPACE = '\ue010'
PAGE_UP = '\ue011'
PAGE_DOWN = '\ue012'
END = '\ue013'
HOME = '\ue014'
LEFT = '\ue015'
ARROW_LEFT = '\ue015'
UP = '\ue016'
ARROW_UP = '\ue016'
RIGHT = '\ue017'
ARROW_RIGHT = '\ue017'
DOWN = '\ue018'
ARROW_DOWN = '\ue018'
INSERT = '\ue019'
DELETE = '\ue01a'
SEMICOLON = '\ue01b'
EQUALS = '\ue01c'
NUMPAD0 = '\ue01d'
NUMPAD1 = '\ue01e'
NUMPAD2 = '\ue01f'
NUMPAD3 = '\ue020'
NUMPAD4 = '\ue021'
NUMPAD5 = '\ue022'
NUMPAD6 = '\ue023'
NUMPAD7 = '\ue024'
NUMPAD8 = '\ue025'
NUMPAD9 = '\ue026'
MULTIPLY = '\ue027'
ADD = '\ue028'
SEPARATOR = '\ue029'
SUBTRACT = '\ue02a'
DECIMAL = '\ue02b'
DIVIDE = '\ue02c'
F1 = '\ue031'
F2 = '\ue032'
F3 = '\ue033'
F4 = '\ue034'
F5 = '\ue035'
F6 = '\ue036'
F7 = '\ue037'
F8 = '\ue038'
F9 = '\ue039'
F10 = '\ue03a'
F11 = '\ue03b'
F12 = '\ue03c'
META = '\ue03d'
COMMAND = '\ue03d'
6. 图片上传功能实现
本节目标是在百度识图官方网站完成一张本地图片的上传操作。通过 Selenium 工具控制浏览器,定位文件输入框,并自动填入指定图片路径,从而触发上传流程。
示例代码如下:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from time import sleep
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://graph.baidu.com/pcpage/index?tpl_from=pc')
input_element = driver.find_element(by=By.NAME, value='file')
input_element.send_keys(r"C:\Users\A\PycharmProjects\PythonProject\lanzhi\书代码\第15章(爬虫)\lsls.jpg")
sleep(5) # 留出足够时间供页面跳转及新结果渲染
graph_guess_word = driver.find_element(by=By.CLASS_NAME, value='graph-guess-word')上述脚本首先配置了 Edge 浏览器的启动选项,指定了浏览器可执行文件的位置,随后打开百度识图主页。接着通过 name 属性定位到文件上传控件,并使用 send_keys 方法传入本地图片的完整路径,实现自动选择文件。由于页面需要一定时间加载识别结果,因此设置了 5 秒的等待时间,确保后续元素能够被正确查找。
output_element = graph_guess_word.find_element(By.XPATH, ".//span")
print("识别结果:", output_element.text)
a = input('维持窗口:')
第9行代码通过调用 driver.find_element(by=By.NAME, value='file') 方法,定位网页中标签名为 file 的元素。
在第10行代码中,利用 send_keys() 方法将指定的图片路径以字符串形式填入该 file 标签对应的输入框,从而完成图片上传操作。运行代码后,程序会自动打开百度识图官方网站,并上传位于 “C:\Users\A\PycharmProjects\PythonProject\lanzhi\书代码\第15章(爬虫)\lsls.jpg” 的图片文件,网站将自动对该图像进行识别处理。
7. 更多浏览器操作
1. 模拟点击操作
在获取到目标网页元素之后,可以调用 click() 方法来模拟鼠标点击行为,即触发页面上某一元素的点击事件。为了更高效地跳转至目标页面,以下示例展示如何使用 click() 方法点击人民邮电出版社官网中的“图书”栏目。
代码实现如下:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r""
driver = webdriver.Edge(options=edge_options)
driver.get("https://www.ptpress.com.cn/periodical")
elements = driver.find_elements_by_class_name("item")
for element in elements:
print(element.text)
第7行代码使用 find_elements_by_class_name() 方法查找所有 class 属性为 "item" 的网页元素。由于在目标位置存在多个 class 名相同且标签名一致的元素,因此需先获取全部此类元素以便进一步筛选。
第8至第11行通过 for 循环遍历并输出每个元素的文本内容,帮助开发者确认所需元素在列表中的具体索引位置。
第12行确定“图书”选项在 elements 列表中的索引为 3,随后调用 click() 方法实现点击操作。
2. WebDriver 常用控制方法
- back():返回上一个访问过的页面。
- forward():前进到下一个历史记录中的页面。
- refresh():重新加载当前页面。
- quit():关闭整个浏览器进程及所有相关窗口。
- close():仅关闭当前活动的标签页(浏览器中每一个打开的网页称为一个标签页,此操作不影响其他标签页)。
以下为实际应用示例:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
import time
edge_options = Options()
edge_options.binary_location = r""
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/')
elements = driver.find_elements_by_class_name("item")
elements[3].click() # 点击“图书”链接
driver.back() # 返回上一页
time.sleep(5)
driver.forward() # 前进至前一页
time.sleep(5)
driver.refresh() # 刷新当前页面
time.sleep(5)
driver.quit() # 完全退出浏览器
其中,第10行调用 back() 方法,使页面从“图书”页返回至官网首页。
第12行执行 forward() 方法,重新由首页前进至“图书”页面。
第14行使用 refresh() 方法对当前页面进行刷新。
第16行调用 quit() 方法结束会话并关闭浏览器。
time.sleep(5) 的引入是为了防止代码执行速度过快,导致无法清晰观察每一步的操作效果,加入延时有助于调试和演示。
3. 无头模式:不启动浏览器界面获取网页资源
除了常规的可视化浏览器操作外,Selenium 还支持“无头模式”(Headless Mode),即在后台运行浏览器而无需显示图形界面。该方式能够在不弹出浏览器窗口的情况下完成网页加载、元素抓取、截图、表单提交等操作,适用于服务器环境或需要降低资源消耗的场景。
在通过代码抓取网页资源时,通常无需实际打开浏览器界面,因为用户关注的是最终的数据结果,而非页面的加载过程。为了提升效率并减少资源占用,可以采用无头模式(headless mode)来运行浏览器。这种模式下,浏览器在后台运行,不显示可视化窗口,所有操作均在内存中完成。
实现该功能的关键是使用 Options 类中的 add_argument() 方法,并传入 '--headless' 参数,即可启用无窗口运行方式。示例如下:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.add_argument('--headless')
edge_options.binary_location = r""
driver = webdriver.Chrome(options=edge_options)
driver.get("https://www.ptpress.com.cn/")
上述代码中,第 4 行设置了浏览器以无界面模式启动。虽然不会弹出浏览器窗口,但其核心功能依然正常运作,能够在后台完成页面加载与 DOM 解析等操作。
接下来,在第 9 到第 10 行代码中,程序会查找人民邮电出版社官网页面上所有标签名为 a 的元素,并输出其文本内容:
elements = driver.find_elements_by_tag_name("a")
for element in elements:
print(element.text)
通过这种方式,可以在不干扰用户界面的前提下高效获取网页中的结构化信息。读者可自行运行代码,验证其执行效果。

 京公网安备 11010802022788号
京公网安备 11010802022788号







