


 雷达卡
雷达卡



在 NeurIPS 2025 上发表的一项重要研究揭示了扩散模型生成图像过程中一个长期被忽视的本质:去噪不仅是一个微分方程求解问题,更是一种系统性降低不确定性的信息恢复过程。这项由何恺明团队主导的新工作提出了一种全新的视角——去除VAE结构、无需Tokenizer,直接采用纯Transformer架构进行数据预测,其效率优于传统的噪声预测方式。
与此同时,华南理工大学的研究也得出了相似结论:在扩散模型中,直接预测原始数据比预测噪声更具优势。该研究从底层数学原理出发,指出图像生成过程本质上是逆向减少条件熵的信息重建过程,并基于此提出了EVODiff算法,通过优化推断阶段的条件方差,在不增加计算成本的前提下显著提升了生成质量与效率。

信息论框架下的扩散模型新理解
尽管扩散模型在图像合成、视频生成等任务中展现出强大的生成能力,但其缓慢的多步推断过程一直是实际应用中的瓶颈。过去主流方法如PNDM、DPM-Solver和UniPC,通常将去噪建模为常微分方程(ODE)或随机微分方程(SDE)的数值求解问题,致力于寻找更高精度的积分器以减少迭代步数。
然而,这些方法大多聚焦于轨迹逼近的数学精度,忽略了生成过程背后的物理意义——即如何从高斯噪声中逐步恢复出有序的数据结构。这种缺失导致缺乏对“为何某些推断策略更高效”的理论解释,也限制了进一步压缩推理步数的设计空间。
EVODiff 正是为填补这一理论空白而生。研究团队引入信息论视角,将整个逆向生成过程视为条件熵动态演化的路径。前向扩散不断添加噪声、破坏结构、提升熵值;相应地,逆向推断必须实现熵减,即持续降低中间状态的不确定性。
在此框架下,每一次去噪的核心目标变得明确:最大化信息增益,最小化条件熵。而互信息作为衡量连续状态间信息传递的关键指标,与条件熵呈负相关关系。因此,降低条件熵意味着更高的信息利用率,从而更有效地逼近真实数据分布。
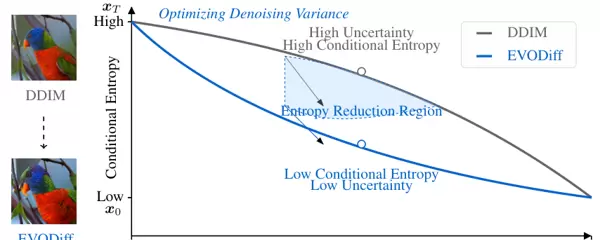
从熵减到方差优化:可操作的理论转化
虽然直接计算高维图像的熵不可行,但研究者巧妙利用扩散模型常用的高斯近似假设,建立了条件熵与条件方差之间的数学联系。在马尔可夫链与高斯转换的设定下,理论推导表明:条件熵正比于条件方差的对数行列式。
这一发现至关重要——它将抽象的信息论目标“熵减”转化为具体可优化的操作目标“方差最小化”。只要在每一步推断中有效降低条件方差,就能间接实现条件熵的下降,推动样本更快收敛至高概率区域。
数据预测为何优于噪声预测?
扩散模型常见的两种参数化方式为预测噪声(Noise Prediction)与预测数据(Data Prediction)。EVODiff 的理论分析首次从信息论角度证明:
数据预测在理论上优于噪声预测。
原因在于:在独立性假设下,直接预测数据能够更有效地减少重建误差并抑制条件熵的增长。相比之下,噪声预测需经过多次转换才能还原数据,每一环节都可能引入并放大误差,形成累积偏差。而数据预测则绕过中间变量,直指目标分布,避免了不确定性传播。
这一结论也为此前一些经验现象(如DPM-Solver中数据空间求解表现更优)提供了坚实的理论支撑。
重建误差分解与EVODiff的收敛保障
为了设计更高效的推断算法,研究团队进一步将重建误差分解为两个组成部分:方差项与偏差项。其中,方差项反映当前状态相对于后验均值的波动程度,偏差项则衡量后验均值与真实数据之间的偏离。
由于在生成时无法获知真实数据,优化偏差项既困难又不具备可行性。因此,唯一可控且有效的优化方向是方差项。
传统ODE求解器虽能沿预设轨迹推进,却未主动考虑方差控制。EVODiff 则提出一种“熵感知”的方差优化机制,通过动态调整推断路径来最小化每一步的条件方差。该机制并非盲目优化,而是基于对梯度推断中方差来源的深入分析。
研究表明,梯度推断中的条件方差主要来源于两方面:一是梯度估计本身的随机性所带来的方差,二是梯度项与一阶展开项之间不匹配所引发的额外方差。EVODiff 针对这两类来源设计了相应的校正策略,实现了更稳定、更精确的低步数生成。
实验结果验证了该方法的有效性。例如,在 CIFAR-10 数据集上,仅用10步推断,EVODiff 将FID分数从5.10大幅降低至2.78,实现了生成保真度的突破性提升,同时未增加额外计算开销。
通过构建一个旨在最小化前向与逆向估计差异以及梯度误差的目标函数,研究人员成功推导出在松弛约束条件下这两个参数的闭式解(Closed-form solution)。 这一理论突破使得 EVODiff 能够在每一次迭代过程中瞬时计算出最优参数值,并依据当前推断状态进行动态调整。整个过程在不增加额外计算负担的前提下,实现了信息传输效率的最大化。 基于上述原理,EVODiff 被设计为一种即插即用的推理框架。它无需对已有模型重新训练,而是作为采样策略直接应用于现有的预训练扩散模型中。算法的核心在于标准多步迭代流程中引入了方差优化项,从而改进状态更新机制。 该设计允许 EVODiff 有效利用模型参数中低方差区域的信息,通过线性插值方式引入低方差参数,以“中和”高方差的估计结果。研究进一步证明,这种基于熵减少(RE)的多步迭代方法构成了一种全局收敛的二阶迭代算法。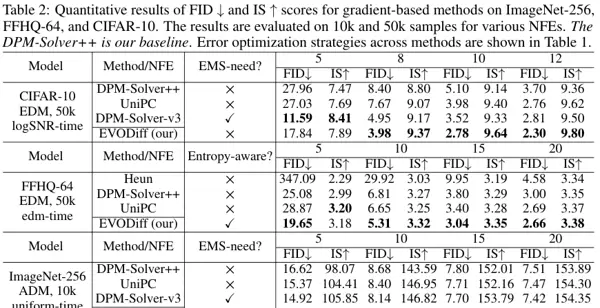 在多个标准数据集上的广泛实验验证了其卓越性能。EVODiff 在 CIFAR-10、ImageNet 和 LSUN-Bedrooms 等基准上,与 DPM-Solver++、UniPC、DEIS 等当前先进算法进行了全面对比。
在 CIFAR-10 数据集上,当仅使用 10 次函数评估(10 NFE)时,DPM-Solver++ 的 FID 分数为 5.10,而 EVODiff 将其显著降低至 2.78,相对误差减少了 45.5%。即便在极端的 5 NFE 设置下,EVODiff 仍能保持良好生成质量,FID 从基线的 27.96 下降至 17.84,展现出在计算资源受限场景下的强大优势。
在多个标准数据集上的广泛实验验证了其卓越性能。EVODiff 在 CIFAR-10、ImageNet 和 LSUN-Bedrooms 等基准上,与 DPM-Solver++、UniPC、DEIS 等当前先进算法进行了全面对比。
在 CIFAR-10 数据集上,当仅使用 10 次函数评估(10 NFE)时,DPM-Solver++ 的 FID 分数为 5.10,而 EVODiff 将其显著降低至 2.78,相对误差减少了 45.5%。即便在极端的 5 NFE 设置下,EVODiff 仍能保持良好生成质量,FID 从基线的 27.96 下降至 17.84,展现出在计算资源受限场景下的强大优势。
 在高分辨率任务如 ImageNet-256 上,EVODiff 同样表现突出。为达到相同质量水平,其所需 NFE 比 DPM-Solver++ 减少了 25%(从 20 降至 15),意味着实际部署中生成速度可提升四分之一。
此外,EVODiff 对潜在空间扩散模型(Latent Diffusion Models)同样适用。
在高分辨率任务如 ImageNet-256 上,EVODiff 同样表现突出。为达到相同质量水平,其所需 NFE 比 DPM-Solver++ 减少了 25%(从 20 降至 15),意味着实际部署中生成速度可提升四分之一。
此外,EVODiff 对潜在空间扩散模型(Latent Diffusion Models)同样适用。
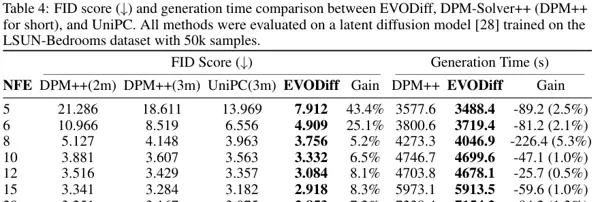 在 LSUN-Bedrooms 数据集上,5 NFE 条件下,EVODiff 的 FID 达到 7.912,远优于 UniPC 的 13.969,性能提升高达 43.4%。同时,由于避免了冗余计算,EVODiff 在生成时间上也具备优势——在保证最高生成质量的同时,速度比 UniPC 快约 5.3%。
在 LSUN-Bedrooms 数据集上,5 NFE 条件下,EVODiff 的 FID 达到 7.912,远优于 UniPC 的 13.969,性能提升高达 43.4%。同时,由于避免了冗余计算,EVODiff 在生成时间上也具备优势——在保证最高生成质量的同时,速度比 UniPC 快约 5.3%。
 视觉质量的提升同样显著。定量指标的进步直观体现在图像感官效果上。实验表明,在低步数采样时,传统方法常出现噪声残留、结构失真或模糊等问题,而 EVODiff 生成的图像则细节清晰、结构完整。
在文本到图像生成任务中,这种优势转化为更强的语义一致性与更少的视觉伪影。例如,在使用 Stable Diffusion v1.5 模型并输入提示词“一只骑自行车的巨大毛毛虫”时,25 NFE 条件下,DPM-Solver++ 和 UniPC 生成的图像存在明显扭曲和结构混乱,毛毛虫与自行车融合不合理;而 EVODiff 不仅生成高保真图像,还准确还原了语义描述,两者交互自然且符合物理逻辑。
视觉质量的提升同样显著。定量指标的进步直观体现在图像感官效果上。实验表明,在低步数采样时,传统方法常出现噪声残留、结构失真或模糊等问题,而 EVODiff 生成的图像则细节清晰、结构完整。
在文本到图像生成任务中,这种优势转化为更强的语义一致性与更少的视觉伪影。例如,在使用 Stable Diffusion v1.5 模型并输入提示词“一只骑自行车的巨大毛毛虫”时,25 NFE 条件下,DPM-Solver++ 和 UniPC 生成的图像存在明显扭曲和结构混乱,毛毛虫与自行车融合不合理;而 EVODiff 不仅生成高保真图像,还准确还原了语义描述,两者交互自然且符合物理逻辑。
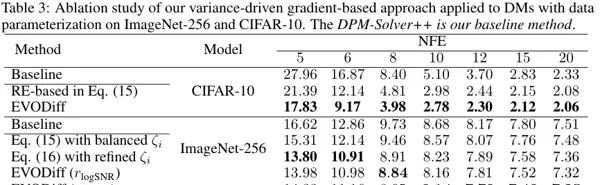
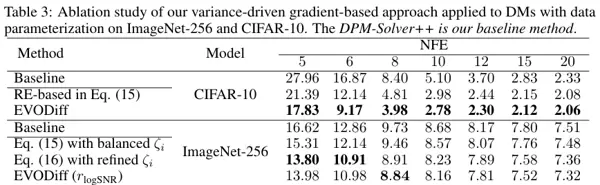 为验证各模块的有效性,研究团队开展了详尽的消融实验。结果表明,从基线求解器出发,引入熵减少机制带来首轮性能提升,再加入演化状态驱动的参数优化后,FID 进一步下降。这说明 EVODiff 的成功源于多层次优化策略的协同作用,而非单一技巧的堆叠。
为验证各模块的有效性,研究团队开展了详尽的消融实验。结果表明,从基线求解器出发,引入熵减少机制带来首轮性能提升,再加入演化状态驱动的参数优化后,FID 进一步下降。这说明 EVODiff 的成功源于多层次优化策略的协同作用,而非单一技巧的堆叠。
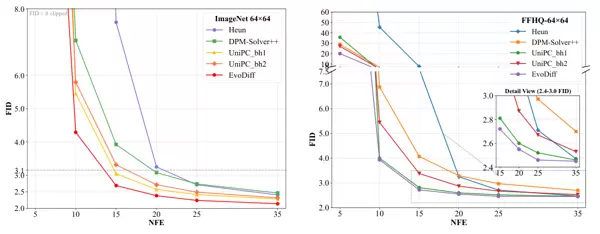 此外,EVODiff 展现出极强的鲁棒性。无论采用 logSNR 或 EDM 的噪声调度策略,无论是像素空间还是潜在空间模型,其性能曲线始终位于其他方法之下(FID 越低越好)。这种广泛的适应性表明,EVODiff 具备成为未来扩散模型推理标准组件的潜力,适用于从学术研究到工业落地的多种场景。
EVODiff 并未止步于表层的速度优化,而是深入生成过程的信息论本质,通过调控条件熵与方差来优化生成路径。这种无需依赖参考轨迹、基于物理直觉的方差控制方法,不仅缓解了推理速度与生成质量之间的矛盾,也为理解生成模型背后的数学机制提供了全新视角。
随着生成式 AI 对实时性与高质量需求的持续增长,像 EVODiff 这类兼具理论深度与实际效能的算法,将成为推动技术真正落地的关键力量。
此外,EVODiff 展现出极强的鲁棒性。无论采用 logSNR 或 EDM 的噪声调度策略,无论是像素空间还是潜在空间模型,其性能曲线始终位于其他方法之下(FID 越低越好)。这种广泛的适应性表明,EVODiff 具备成为未来扩散模型推理标准组件的潜力,适用于从学术研究到工业落地的多种场景。
EVODiff 并未止步于表层的速度优化,而是深入生成过程的信息论本质,通过调控条件熵与方差来优化生成路径。这种无需依赖参考轨迹、基于物理直觉的方差控制方法,不仅缓解了推理速度与生成质量之间的矛盾,也为理解生成模型背后的数学机制提供了全新视角。
随着生成式 AI 对实时性与高质量需求的持续增长,像 EVODiff 这类兼具理论深度与实际效能的算法,将成为推动技术真正落地的关键力量。
 京公网安备 11010802022788号
京公网安备 11010802022788号







