


 雷达卡
雷达卡



引言
作为一名内容创作者,保持对行业动态的敏锐感知是我的日常任务。每天早晨,我都要打开多个浏览器标签页,逐一搜索最新资讯,再手动复制、整理成一份简报。这一过程不仅繁琐、重复,而且效率极低。
直到我接触到 ModelEngine 的可视化编排功能,才意识到这种重复性劳动完全可以实现自动化。通过将整个流程拆解为独立的功能模块,并像拼积木一样连接起来,我成功打造了一个“全自动行业研报生成器”。接下来,我将详细介绍这个工作流的设计思路与实现过程。
一、 工作流设计与整体架构
我的目标是构建一条完整的自动化流水线:从关键词输入开始,自动完成网络搜索、内容抓取、信息提炼,最终输出结构化的行业日报。
在 ModelEngine 的编排界面中,这一逻辑被清晰地分解为以下核心节点:
- 开始节点 (Start Node):用于接收用户输入的关键词(如:“人工智能医疗应用”)。
- 搜索工具节点 (Search Tool Node):调用内置搜索引擎插件,获取与关键词相关的最新网页链接列表。
- 网络爬虫节点 (Web Scraper Node):访问这些链接并提取正文内容。
- 大模型节点 (LLM Node):作为系统的核心处理单元,负责分析和总结所抓取的信息。
- 结束节点 (End Node):输出最终生成的简报结果。
二、 核心构建环节:可视化节点的操作优势
1. 图形化搭建流程骨架
ModelEngine 提供了一个直观的画布环境。我只需从左侧组件库中拖拽所需节点到画布上,并通过连线建立数据流动路径。整个操作如同绘制流程图一般自然流畅,各节点之间的依赖关系和数据流向一目了然。
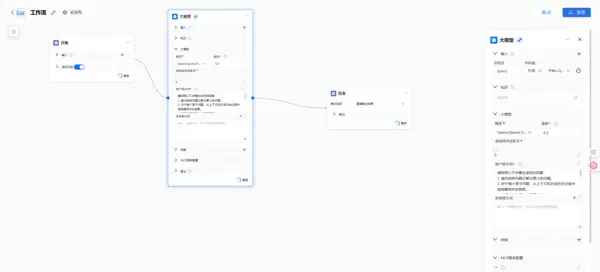
2. 配置 LLM 节点:赋予系统“思考能力”
在整个流程中,LLM 节点是最关键的部分。它需要理解上游传来的原始文本,并按照预设要求进行智能处理。为了实现这一点,我在提示词编辑区使用了变量引用机制。
以下是我在 LLM 节点中设置的 Prompt 示例:
您是一位资深的行业分析师。请阅读以下通过网络搜索获取的多篇关于“{{start_node.query_keyword}}”的文章内容。
输入数据来源:
{{scraper_node.scraped_content}}
任务要求:
1. 提取上述内容中最关键的 3-5 条行业动态;
2. 过滤广告及无关信息;
3. 将结果整理为一篇结构清晰的早报,包含“核心观点”和“详细摘要”两个部分;
4. 输出格式采用 Markdown。
借助 {{node_name.variable}} 这种简洁语法,我可以轻松将前序节点的数据传递给大模型,实现动态内容注入。
三、 流程调试与问题排查:高效定位异常
尽管可视化编排降低了开发门槛,但在实际运行中仍可能出现问题。ModelEngine 内置的调试模式极大提升了排错效率。
初次运行时,我发现大模型输出的内容非常稀少。于是,我启用调试面板,逐层查看每个节点的输入与输出状态。
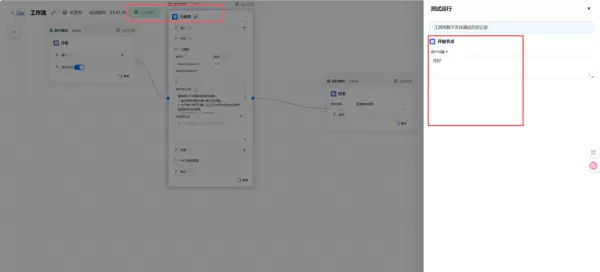
经过检查,问题根源出现在网络爬虫节点:其抓取结果包含了大量侧边栏、导航栏等非正文内容,干扰了后续的信息提取。发现问题后,我优化了爬虫的选择器配置,并在 LLM 的提示词中加强了信息过滤指令。再次执行后,输出质量显著提升。
相比传统代码调试方式,这种图形化的逐节点追踪方法更加直观高效,极大地缩短了迭代周期。
四、 实际效果与使用体会
如今,我只需在输入框中键入一个关键词,等待约 30 秒,即可获得一篇格式规范、内容精炼的行业早报。相比以往的手动操作,工作效率提升了十倍以上。
ModelEngine 的可视化编排功能不仅让 AI 应用开发变得更简单,更重要的是它引入了一种工程化的思维模式——将复杂任务分解、串联、监控与优化。整个流程变得可视、可管、可调。
对于希望构建复杂 AI 自动化流程的用户而言,这无疑是一个强大而实用的工具。

 京公网安备 11010802022788号
京公网安备 11010802022788号







