


 雷达卡
雷达卡



一、神经网络的八大核心要素
要全面理解神经网络的构成要素及其相互关系,我们需要从建模全流程的角度,讲神经网络视为一个由多个正交维度共同定义的“设计空间”。下面我将完整列举**神经网络的核心组成要素(共8大类)、解释每一类的具体内容、用一张关系图说明它们如何协同工作、澄清常见混淆点**。二、详细解析八大要素
1. 网络结构(Network Structure)
网络结构定义了层与层之间的连接方式和整体拓扑形态,直接影响模型对数据特征的提取能力。
常见类型包括:
- 前馈网络(MLP):基础的全连接结构
- 卷积网络(CNN):擅长捕捉局部空间相关性
- 循环网络(RNN/LSTM):处理时序依赖问题
- 图神经网络(GNN):适用于图结构数据
- 自注意力机制(Transformer):建模长距离依赖关系
- 编码器-解码器架构(Seq2Seq):用于序列转换任务
不同的结构决定了模型能够有效学习的数据模式类型,如局部性、顺序性或图关联性。
2. 神经元模型(Neuron Model)
该模块描述单个神经元如何将输入信号映射为输出响应,其核心计算公式如下:
a = φ(∑w_i × x_i + b)
其中包含两个关键部分:
- 激活函数:引入非线性表达能力,常用类型有 ReLU、Sigmoid、Tanh、Swish 等
- 特殊单元设计:如 LSTM 中的门控机制、胶囊网络中的动态路由、脉冲神经元的时间动态行为
这一组件直接决定网络的非线性拟合能力和表达复杂函数的能力。
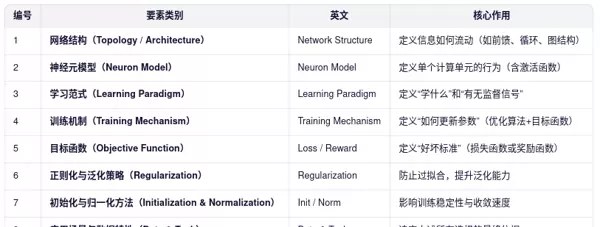
3. 学习范式(Learning Paradigm)
指明模型获取知识的方式和任务的基本性质。
主要类别包括:
- 监督学习:依赖标注数据进行训练
- 无监督学习:从原始数据中发现潜在结构
- 自监督学习:利用数据本身构造监督信号
- 强化学习:通过环境反馈优化策略
- 其他扩展形式:半监督学习、迁移学习、元学习等
学习范式决定了是否需要标签、奖励或其他外部信号来驱动训练过程。
4. 训练机制(Training Mechanism)
涉及参数更新的具体实现方法。
主要内容包括:
- 优化算法:如 SGD、Adam、RMSProp 等
- 梯度计算方式:反向传播(BP)、策略梯度(Policy Gradient)、进化策略(Evolution Strategy)
- 训练策略:批量训练、在线学习、课程学习等
该机制影响模型的学习速度、稳定性以及最终收敛效果。
5. 目标函数(Objective Function)
即损失函数或奖励函数,明确模型优化的方向。
按学习范式分类:
- 监督学习:交叉熵损失、均方误差(MSE)、Hinge Loss
- 无监督学习:重构误差(如自编码器)、KL散度(VAE)、对比损失(SimCLR)
- 强化学习:累积回报(Return)、优势函数(Advantage)
目标函数是训练机制的核心输入,与学习范式紧密耦合。
6. 正则化与泛化策略(Regularization)
旨在防止过拟合并提升模型在未知数据上的表现。
常用手段包括:
- L1 / L2 权重衰减
- Dropout 随机失活
- 数据增强技术
- 早停法(Early Stopping)
- 批归一化(Batch Normalization),兼具加速训练作用
这些方法独立于网络结构存在,但显著影响训练动态和泛化性能。
7. 初始化与归一化方法
虽不改变模型容量,但极大影响训练可行性。
- 参数初始化:Xavier 初始化、He 初始化 —— 有助于梯度稳定传播
- 归一化技术:BatchNorm、LayerNorm、GroupNorm —— 提升训练稳定性
合理的初始化和归一化能避免梯度消失或爆炸,使深层网络更易训练。
8. 应用场景与数据特性
这是所有设计决策的根本驱动力。
不同任务对应最优结构选择:
- 图像处理 → 倾向使用 CNN
- 文本序列建模 → RNN 或 Transformer 更合适
- 图结构数据 → GNN 是首选
- 小样本学习 → 可考虑元学习框架
不存在“万能”的网络结构,只有最适配具体任务与数据分布的设计组合。
三、常见误区澄清

四、以 ResNet 为例,分析八大维度体现
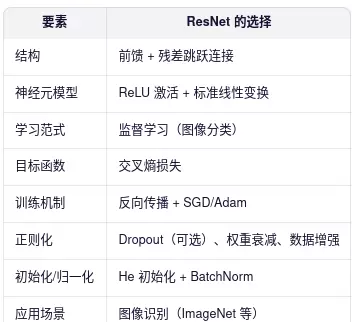
五、总结
神经网络并非单一技术,而是一个多维设计空间。你所提及的“学习范式、网络结构、训练机制、激活函数”确实是关键组成部分,但仍需补充其余四个维度才能完整刻画模型全貌。
目标函数(定义优化方向)
正则化策略(控制泛化)
初始化与归一化(保障可训练性)
数据与任务(一切设计的起点)
???? 真正强大的AI工程师,不是记住模型名字,而是理解这8个维度如何组合以解决实际问题。
 京公网安备 11010802022788号
京公网安备 11010802022788号







