


 雷达卡
雷达卡



本文所述方法适用于woff字体文件频繁变动的网站场景。若目标站点的woff文件较为固定,可考虑跳过图片处理环节,直接导出字体中的字符图像进行OCR识别,并辅以人工校验完成数据提取。
目标网站示例如下:
aHR0cHM6Ly96ZmNnLmN6dC56ai5nb3YuY24vbHViYW4vZGV0YWlsP3BhcmVudElkPTYwMDAwNyZhcnRpY2xlSWQ9VHpGSHNoQUk3OUxuUW1oemJQbG4vUT09在对接口进行抓包分析时发现,正文内容由名为“detail”的接口返回。然而,响应数据中存在大量视觉上不可见的空白区域。通过复制操作可获取实际隐藏的文字内容,说明文本信息确实存在于页面中,但显示异常。
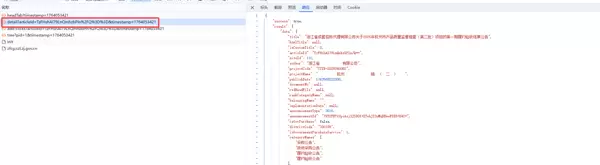
复制所得内容如下图所示:

进一步查看页面源码后,发现一段用于加载自定义字体的CSS规则。该样式定义了一个名为 "ZCY SC" 的字体族,通过@font-face引入了远程EOT与WOFF格式的字体文件,并强制将整个页面body元素的字体设置为此自定义字体。这种技术常被用作反爬虫手段——利用私有字符映射机制,使真实文本在未正确解析字体的情况下无法正常阅读。
<style type="text/css">
@font-face {
font-family: "ZCY SC";
src: url('https://zcy-gov-open-doc.oss-cn-north-2-gov-1.aliyuncs.com/1147JT/117011d6-3243-4cbf-80e9-6b63f0f0592a.eot');
src: url('https://zcy-gov-open-doc.oss-cn-north-2-gov-1.aliyuncs.com/1147JT/117011d6-3243-4cbf-80e9-6b63f0f0592a.eot?#iefix') format('embedded-opentype'),url("https://zcy-gov-open-doc.oss-cn-north-2-gov-1.aliyuncs.com/1147JT/b5ecddd8-d22e-4227-b9cc-70e6865de3e1.woff") format('woff')
}
body {
font-family: "San Francisco", "PingFang SC", Arial, "Microsoft YaHei", 微软雅黑, "ZCY SC" !important;
}
</style>因此可以判断,当前内容无法正常显示的原因正是由于使用了经过加密或重映射的WOFF字体文件。为还原原始文本,需对字体文件进行解密和映射关系重建。
整体流程拆解如下:
- 获取网页当前使用的WOFF字体文件;
- 解析该字体文件,提取其中的字形与Unicode编码对应关系;
- 依据解析出的映射表,替换接口返回中的乱码字符,还原真实内容。
对于本案例而言,WOFF文件地址已在CSS代码中明确指出,无需额外查找,可直接进入第二阶段的解析工作。
WOFF字体解析步骤:
该过程可分为三个主要环节:
- 解析WOFF文件并导出字符对应的图像;
- 对导出的图像进行预处理优化;
- 执行OCR识别,建立图像与实际文本之间的映射关系。
第一步:WOFF解析与图像导出 + 图像预处理
借助fontTools工具库实现WOFF文件的解析。为提高效率,本文将图像导出与预处理合并为一个步骤执行。导出的图片以对应字符的Unicode码点命名,便于后续追踪匹配。相关代码实现如下:
import json
import re
import ddddocr
import requests
import freetype
from fontTools.ttLib import TTFont
from PIL import Image
import os
from tqdm.auto import tqdm
def export_glyphs(woff_path, output_dir, canvas_size=(64, 64), margin_ratio=0.15):
"""
将 WOFF 字体中的字符按 Unicode 编码导出为图片(如 uniF00C.jpg),字符与背景留15%空白。
:param woff_path: WOFF 字体文件路径
:param output_dir: 图片输出目录
:param canvas_size: 输出图片尺寸(宽,高),默认 64x64
:param margin_ratio: 字符与背景的留白比例,默认 15%(0.15)
"""
# 1. 解析 WOFF,获取字符映射表(Unicode → 字形名称)
font = TTFont(woff_path)
cmap = font['cmap'].getBestCmap() # 自动选择最优字符映射表
# 2. 加载字体到 FreeType,准备渲染
face = None
ttf_path = None
try:
face = freetype.Face(woff_path) # 尝试直接加载 WOFF(需 FreeType ≥2.8)
except Exception as e:
print(f"直接加载 WOFF 失败:{e},尝试转换为 TTF...")
# 若加载失败,先转换为 TTF(依赖 fonttools 的 woff2 模块)
try:
from fontTools.woff2 import decompress
ttf_path = "temp_font.ttf"
decompress(woff_path, ttf_path)
face = freetype.Face(ttf_path)
except Exception as e2:
print(f"转换 TTF 失败:{e2}")
return
# 设置渲染尺寸(此处渲染为较大尺寸,后续缩放避免模糊)
render_size = max(canvas_size) * 2 # 渲染尺寸翻倍,缩放后更清晰
face.set_pixel_sizes(render_size, render_size)
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
print(f"开始导出字符图片,共找到 {len(cmap)} 个字符映射...")
print(f"图片尺寸:{canvas_size[0]}x{canvas_size[1]},留白比例:{margin_ratio*100}%")
success_count = 0
for unicode_code, glyph_name in tqdm(cmap.items(), desc='导出进度', unit='item'):
# 3. 获取字形索引,跳过无对应字形的字符
glyph_index = face.get_char_index(unicode_code)
if glyph_index == 0:
continue
# 4. 加载并渲染字形为位图
try:
face.load_glyph(glyph_index)
glyph = face.glyph
bitmap = glyph.bitmap
# 跳过空字形(宽度或高度为 0)
if bitmap.width == 0 or bitmap.rows == 0:
continue
# 5. 关键修复:将 bitmap.buffer 转换为 bytes(处理 list/bytes 兼容问题)
if isinstance(bitmap.buffer, list):
bitmap_data = bytes(bitmap.buffer)
else:
bitmap_data = bitmap.buffer
# 转换为 Pillow 图像,并反转颜色(黑→白,白→黑)
img = Image.frombytes('L', (bitmap.width, bitmap.rows), bitmap_data)
img = img.point(lambda p: 255 - p) # 颜色反转
# ---------------------- 核心修改:计算15%留白并缩放字符 ----------------------
# 1. 计算有效绘制区域(画布尺寸 - 两侧15%留白)
effective_w = canvas_size[0] * (1 - 2 * margin_ratio) # 左右各15%
effective_h = canvas_size[1] * (1 - 2 * margin_ratio) # 上下各15%
# 2. 计算缩放比例(保持宽高比,不超过有效区域)
orig_w, orig_h = img.size
scale = min(effective_w / orig_w, effective_h / orig_h) # 取最小比例避免超出
# 3. 缩放字符(使用高质量缩放算法)
new_w = int(orig_w * scale)
new_h = int(orig_h * scale)
img_scaled = img.resize((new_w, new_h), Image.Resampling.LANCZOS) # 抗锯齿缩放
# 4. 创建白色画布
canvas = Image.new('RGB', canvas_size, color='white')
# 5. 居中粘贴缩放后的字符(周围自然留出15%空白)
x = (canvas_size[0] - new_w) // 2
y = (canvas_size[1] - new_h) // 2
canvas.paste(img_scaled, (x, y))
# --------------------------------------------------------------------------
# 7. 生成文件名并保存
unicode_hex = f"{unicode_code:04X}"
filename = f"uni{unicode_hex}.jpg"
canvas.save(os.path.join(output_dir, filename))
success_count += 1
except Exception as e:
print(f"导出 Unicode {unicode_code:04X} 失败:{e}")
continue
# 清理临时文件
if ttf_path and os.path.exists(ttf_path):
os.remove(ttf_path)
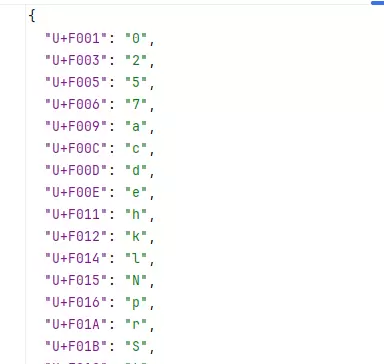
print(f"导出完成!成功保存 {success_count} 张字符图片到 {output_dir}")转换后的输出结果如图所示。之所以需要对图像进行预处理,是为了提升OCR识别的准确率,确保每个字符图像清晰、对比度高且无干扰噪点。

第二步:OCR识别
选用合适的OCR模型对处理后的图像逐一识别,并将识别结果与其对应的Unicode编码保存为结构化数据(如JSON格式),形成完整的字符映射表。
def recognize_font_images_with_ddddocr(image_dir, output_json_path):
"""
使用ddddocr识别指定目录下的所有字体图片,并保存为JSON文件
Args:
image_dir: 包含字体图片的目录路径
output_json_path: 输出的JSON文件路径
"""
# 初始化ddddocr识别器
ocr = ddddocr.DdddOcr(show_ad=False)
# 存储识别结果的字典
recognition_results = {}
# 支持的图片格式
supported_formats = {'.png', '.jpg', '.jpeg', '.bmp', '.tiff', '.tif'}
# 获取目录下所有图片文件
image_files = []
for file in os.listdir(image_dir):
file_ext = os.path.splitext(file)[1].lower()
if file_ext in supported_formats:
image_files.append(file)
print(f"发现 {len(image_files)} 个图片文件,开始识别...")
# 处理每个图片文件
for i, filename in enumerate(tqdm(image_files, desc='识别进度'), 1):
try:
# 从文件名中提取unicode码
unicode_match = extract_unicode_from_filename(filename)
if not unicode_match:
print(f"[{i}/{len(image_files)}] 跳过无法提取unicode的文件: {filename}")
continue
unicode_code = unicode_match
file_path = os.path.join(image_dir, filename)
# 使用ddddocr识别图片
with open(file_path, 'rb') as f:
image_bytes = f.read()
# 识别文字
recognized_text = ocr.classification(image_bytes)
# 存储结果
recognition_results[unicode_code] = recognized_text
# print(f"[{i}/{len(image_files)}] 识别成功: {filename} -> {recognized_text} (Unicode: {unicode_code})")
except Exception as e:
print(f"[{i}/{len(image_files)}] 识别失败 {filename}: {e}")
continue
# 保存结果为JSON文件
try:
with open(output_json_path, 'w', encoding='utf-8') as f:
json.dump(recognition_results, f, ensure_ascii=False, indent=2)
print(f"???? 成功识别 {len(recognition_results)}/{len(image_files)} 个字符")
except Exception as e:
print(f"? 保存JSON文件失败: {e}")最终得到的识别结果展示如下:
最终应用:
在正式的数据采集脚本中,加载上述生成的JSON映射文件,根据已知的字体映射关系对detail接口返回的混淆文本进行批量替换,从而实现原始内容的精准还原。

 京公网安备 11010802022788号
京公网安备 11010802022788号







