


 雷达卡
雷达卡



与传统的 Requests 和 BeautifulSoup 组合相比,DrissionPage 库具备显著优势。它将浏览器自动化(类似 Selenium)和网络请求(类似 Requests)功能整合于同一库、同一对象中,极大降低了爬虫开发的入门门槛。同时,DrissionPage 支持实时展示浏览器操作过程,便于开发者观察页面结构与调试前端代码。(以下案例以爬取京东商品的商品描述、价格及用户评论为例进行说明)
第一步:导入所需库
from DrissionPage import ChromiumOptions, ChromiumPage
from DrissionPage.common import Keys
import re
import time
import json第二步:创建浏览器实例
co = ChromiumOptions()
co.no_imgs(True)
cp = ChromiumPage(addr_or_opts=co)
url = "https://www.jd.com/"
cp.get(url)
cp.ele('css:#key').input('西部数据')
cp.ele('css:#key').input(Keys.ENTER)cp 表示当前浏览器实例。
使用 cp.ele('css:#key') 可定位页面中 id 为 key 的输入框元素(其中 '#' 表示通过 id 属性查找)。定位成功后,输入目标商品名称(如“西部数据”),并模拟按下回车键触发搜索。
第三步:获取商品列表容器
在浏览器中,可通过右键“检查”查看页面 HTML 结构: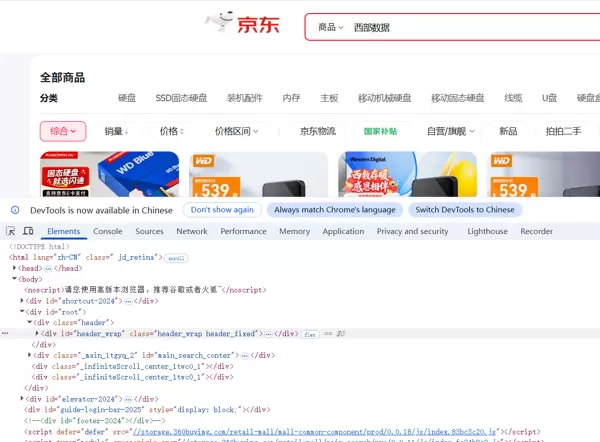 点击开发者工具左上角的选取图标:
点击开发者工具左上角的选取图标:
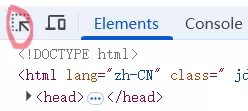 随后将鼠标悬停在商品区域,即可定位到对应的商品 div 容器:
随后将鼠标悬停在商品区域,即可定位到对应的商品 div 容器:
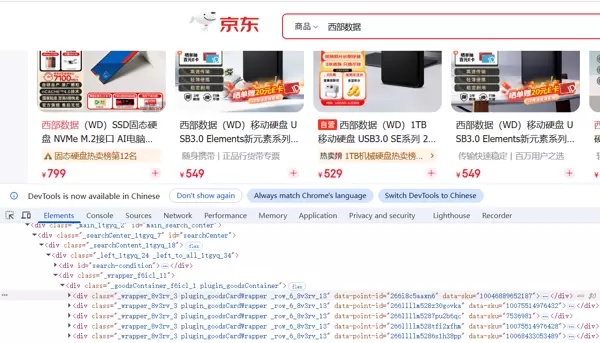 注意到每个商品 div 中包含一个关键属性
注意到每个商品 div 中包含一个关键属性 data-sku(库存单位标识,Stock Keeping Unit),该属性通常唯一标识一个商品。因此,使用如下语句获取所有商品项:
goods = cp.eles('css:div[data-sku]')goods = cp.eles('css:div[data-sku]')第四步:提取价格与商品标题
 虽然可通过 class 名称定位商品标题和价格(例如:
虽然可通过 class 名称定位商品标题和价格(例如:good.ele('css:._goods_title_container_1g56m_1 _clip2_1g56m_14'),其中 '.' 表示按 class 查找),但此类方式稳定性差。观察发现,京东列表页的 class 名包含哈希后缀,每次更新前端资源时均会发生变化。
因此,采用更稳定的 XPath 方式进行定位:
title = good.ele('xpath:.//span[contains(@class,"text")]').text
price = good.ele('xpath:.//span[contains(@class,"price")]').text第五步:进入单个商品详情页
good.click()
if cp.latest_tab != cp:
new_tab = cp.latest_tab
else:
new_tab = cp
cp.wait.load_start()cp.wait.load_start() 方法,等待新页面开始加载完成后再执行下一步操作,避免因页面未就绪导致元素查找失败。
第六步:抓取用户评论数据

comments = [comment.text for comment in new_tab.eles('.info text-ellipsis-2')]第七步:获取分页控制信息
为实现多页商品数据的连续爬取,需识别总页数以及“下一页”按钮的位置。 同样利用 XPath 进行精准定位:
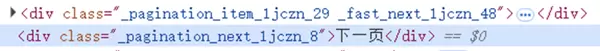
cp.ele('xpath:.//div[contains(@class,"pagination_next")]').click()
page_max = re.findall(r'\d+',cp.ele('xpath:.//div[contains(@class,"pagination_total")]').text)[0]r'\d+' 提取页码文本中的数字部分,准确获取当前总页数,便于循环翻页操作。
第八步:模拟滚动到底部
京东采用动态渲染技术,部分内容需用户滚动至页面底部才会加载。 因此,加入以下代码模拟真实用户下滑行为,确保本页所有数据完全加载:cp.scroll.to_bottom()第九步:引入并行处理机制
考虑到每个商品详情页相互独立,具备高度并行化潜力,有经验的开发者可采用并发策略加速评论信息的采集。尽管作者对并行计算掌握有限,未能在此实现完整方案,但仍欢迎社区高手在讨论区分享高效并行算法思路。附件:完整源码参考
from DrissionPage import ChromiumOptions, ChromiumPage
from DrissionPage.common import Keys
import re
import time
import json
file_path = r'./JD_result_json/'
def save_json(c, p, comments, file_path):
item = {"简介": c, "价格": p, "评论": comments}
with open(file_path, 'w', encoding='utf-8') as f:
f.write(json.dumps(item, ensure_ascii=False, indent=4) + '\n')
co = ChromiumOptions()
co.no_imgs(True)
cp = ChromiumPage(addr_or_opts=co)
url = "https://www.jd.com/"
cp.get(url)
cp.ele('css:#key').input('西部数据')
cp.ele('css:#key').input(Keys.ENTER)
page_max = re.findall(r'\d+',cp.ele('xpath:.//div[contains(@class,"pagination_total")]').text)[0]
index = 1
good_num = int(input("输入你想要爬取的商品数:"))
for page_index in range(int(page_max)):
flag = False
time.sleep(2)
cp.scroll.to_bottom()
goods = cp.eles('css:div[data-sku]')
for good in goods:
title = good.ele('xpath:.//span[contains(@class,"text")]').text
price = good.ele('xpath:.//span[contains(@class,"price")]').text
good.click()
if cp.latest_tab != cp:
new_tab = cp.latest_tab
else:
new_tab = cp
cp.wait.load_start()
comments = [comment.text for comment in new_tab.eles('.info text-ellipsis-2')]
path = file_path + "商品" + str(index) + ".json"
save_json(title, price, comments, path)
if index >= good_num:
flag = True
break
index = index + 1
comments.clear()
new_tab.close()
if flag:
break
cp.ele('xpath:.//div[contains(@class,"pagination_next")]').click()
cp.quit()
 京公网安备 11010802022788号
京公网安备 11010802022788号







