


 雷达卡
雷达卡



当前人工智能技术的发展呈现出多元并行的态势,其中世界模型与基于自然语言处理(NLP)的大语言模型代表了两条差异显著的技术路径。二者在理念、能力结构和应用边界上各具特点,彼此之间并非替代关系,而是处于深度协同与互补的状态。以下从核心概念、特性对比、典型产品、协作模式以及不可替代性等方面进行系统分析。
一、基于 NLP 的大语言模型
1. 核心概念
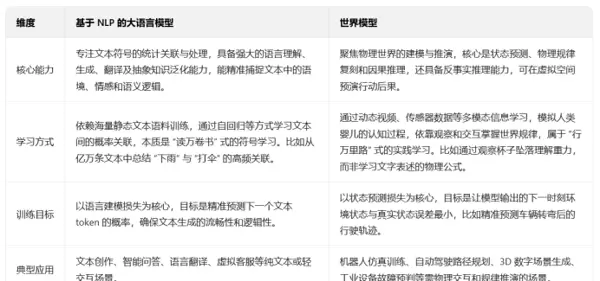
这类模型以海量文本数据为基础,专注于自然语言的理解与生成。其本质是通过对词汇、句法及语义逻辑中的统计规律进行学习,模拟人类的语言交互行为。整个处理过程围绕文本符号体系展开,强调对语言形式的建模而非现实世界的物理理解。
2. 核心特点
- 学习方式为“博览群书”:依赖大规模静态文本语料库,采用自回归等机制捕捉词语之间的概率关联,从而掌握语言表达模式。
- 擅长文本处理任务:在语言生成、翻译、摘要提取等方面表现突出,部分多模态版本还可扩展至图文联合理解。
- 受限于“符号牢笼”:仅能处理语言层面的表层关联,缺乏对因果机制和空间动态的认知能力,容易产生不符合事实的“幻觉”输出。
- 技术成熟度高:具备清晰的架构设计与完整的开发生态,部署成本相对可控,已广泛应用于各类实际场景。
3. 应用场景
覆盖绝大多数与文本相关的通用及专业领域。例如,在编程辅助中可作为代码助手帮助开发者撰写程序;在医疗行业可用于病历信息抽取与关键实体识别;在金融与法律领域则可用于合同审查、合规性分析等高精度文本处理任务。
4. 代表产品
GPT-4:由 OpenAI 推出的闭源大模型,具备强大的文本与图像多模态处理能力,在创意写作、代码生成等领域表现优异,企业版支持复杂商业级文本应用。
豆包大模型:采用稀疏 MoE 架构,推理效率高,幻觉率低至 4%,适用于知识问答、内容创作等多种场景,尤其适合中小微企业的低成本 AI 部署需求。
百度文心一言:在金融、法律等垂直领域有深度优化,能够胜任合同解析、合规判断等专业化文本交互任务,满足行业特定的语言处理要求。

二、世界模型
1. 核心概念
世界模型旨在构建一个可在系统内部运行的真实世界动态模拟器,类似于内置的“物理引擎”。它整合了物理常识、因果逻辑、时空推理等底层规则,能够对未发生的事件进行推演预测,复现人类对世界运行规律的直觉认知。
2. 核心特点
- 以“实践”为导向的学习方式:主要通过视频流、传感器信号等多模态数据进行训练,依靠环境观察与交互来学习世界规律,不依赖传统文本语料。
- 聚焦因果推理与动态预测:不仅能识别“A与B相关”,更能理解“A导致B”的内在机制,实现深层次逻辑推导。
- 强于时空建模能力:对物体的空间位置、运动轨迹具有精准建模能力,可预演不同动作带来的连锁后果。
- 面临高数据成本与标准缺失挑战:训练需大量标注的多模态数据,且目前尚无统一的评估体系与行业规范。
3. 应用场景
主要集中于需要物理交互或复杂场景推演的领域,如自动驾驶中的环境预判、智能制造中的产线仿真、虚拟场景生成等。例如,在自动驾驶系统中,当检测到皮球滚入道路时,模型可推断后续可能出现儿童追跑的情况,并提前减速避险;在供应链管理中,可通过模拟航道封锁的影响,生成订单延迟应对方案。
4. 代表产品
Marble:由李飞飞参与创立的 World Labs 推出的首个商业化世界模型,支持多模态输入生成可编辑的3D环境,广泛应用于游戏开发、影视特效制作,并为机器人提供仿真训练平台。
华为乾崑 ADS 4.0:基于 WEWA 架构构建难例场景数据库,利用世界模型的生成能力提升自动驾驶系统的泛化性能与安全冗余,增强对复杂路况的预测可靠性。
蔚来 NWM 模型:支持多模态输入与自然语言交互,核心目标是通过世界模型强化自动驾驶中的场景理解与决策控制能力,保障行车过程的安全性与稳定性。
三、两类模型的互补机制
1. 指令解析与执行落地的协同
大语言模型擅长将模糊的人类指令转化为结构化任务规划,而世界模型负责将这些抽象指令转化为符合物理规律的具体行动。例如,用户向自动驾驶车辆发出“尽快前往医院”的指令,大语言模型首先将其拆解为“选择最优路线、优先避让行人”等策略,随后由世界模型推演实时路况,计算行驶速度与避让路径,确保操作既高效又安全。
2. 弥补彼此的核心缺陷
大语言模型可为世界模型提供自然语言接口,使普通用户能通过文字直接操控3D场景生成;反过来,世界模型也能弥补大语言模型在物理常识方面的不足。例如面对“拆除货架一侧支撑后货物会如何移动”的问题,大语言模型可能仅凭语义联想作答,但结合世界模型后,系统可准确推演货物倾斜、滑落的过程,避免违反物理规律的错误回答。
3. 跨场景数据与决策的双向转化
世界模型可将现实世界中的动态变化转化为结构化数据,再交由大语言模型加工成易于理解的自然语言输出。例如在工业监控场景中,世界模型感知到某设备温度异常上升,将其转化为状态信号,大语言模型则据此生成故障预警报告并提出维护建议,实现从感知到表达的闭环。
四、为何二者难以相互取代
1. 核心能力存在结构性空白
大语言模型虽精通语言符号的操作,却无法真正理解重力、惯性、碰撞等物理法则;而世界模型虽能模拟真实世界的动态演化,却不具备自然语言的灵活表达与广泛知识覆盖能力。这种根本性的能力错位决定了它们无法单方面完成对方的核心职能,必须通过协同才能实现更高级别的智能行为。
大语言模型在处理文本类任务时展现出高度成熟的适配能力,无论是日常对话、文案生成还是专业领域的问答系统,均已通过市场长期验证,具备良好的稳定性与用户接受度。若将其替换为世界模型,不仅无法发挥后者优势,反而会导致现有应用场景的适配性失效,影响整体使用效果。
与此同时,世界模型在涉及物理规律模拟的领域具有不可替代性,尤其在自动驾驶、机器人交互以及数字孪生等高精度场景中,对动态过程的准确推演至关重要。而大语言模型基于统计关联的推理机制,缺乏对真实物理世界的建模能力,即便能复述物理公式,也无法精确预测如积木倒塌轨迹等具体物理行为,难以满足此类场景对安全性和可靠性的严苛要求。
从技术发展角度看,两者均面临显著瓶颈与生态壁垒,构成相互替代的巨大障碍。世界模型依赖多模态数据输入,标注成本高昂,算力需求巨大,且行业尚未建立统一的训练规范与评估标准,各企业独立研发,短期内难以向以文本为主的场景拓展。反观大语言模型,其架构设计以自然语言为核心,若强行改造用于物理系统建模,需重构整个技术框架,不仅带来算力成本的急剧上升,且改造后的物理推理精度仍远低于原生世界模型的表现。
此外,应用生态的分化进一步加剧了二者之间的鸿沟。大语言模型已在文本创作、信息检索、智能客服等领域构建起完整的技术链条和落地路径;而世界模型则深耕于需要环境感知与动态预测的实体交互场景,两类模型在目标导向、输入输出形式及评价体系上存在根本差异,导致其核心能力难以互相迁移或融合。

 京公网安备 11010802022788号
京公网安备 11010802022788号







