


 雷达卡
雷达卡



一、算法原理与处理流程
核心思想解析:
- PCA(主成分分析):采用特征脸(Eigenface)方法提取人脸的全局结构信息,将高维图像数据映射至低维子空间,保留累计方差贡献率95%以上的主成分,实现有效降维。
- LDA(线性判别分析):在PCA处理后的低维数据基础上进一步优化,通过最大化类间散度与类内散度之比(遵循Fisher准则),增强不同类别之间的可分性。
该方法结合了PCA的数据压缩能力与LDA的分类判别优势,形成一种高效的两阶段特征提取策略。
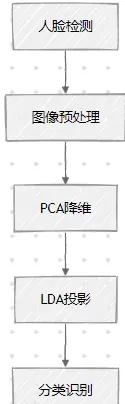
二、详细实现步骤
1. 数据预处理
为保证后续处理的一致性和有效性,需对原始人脸图像进行标准化处理:
- 尺寸归一化:统一调整所有人脸图像为相同分辨率,例如112×92像素,以消除尺度差异带来的干扰。
- 灰度转换与直方图均衡化:先将彩色图像转为灰度图,再进行对比度增强,提升细节表现力。
grayImg = rgb2gray(img); % 转换为灰度图像
img_eq = histeq(grayImg); % 直方图均衡化处理 - 零均值化:从所有训练样本中减去平均脸图像,使数据分布中心对齐原点,便于协方差矩阵计算。
2. PCA阶段:主成分分析降维
目标是去除冗余信息,保留最具代表性的特征方向。
- 构建协方差矩阵:基于中心化后的图像数据集计算协方差矩阵。
covMat = (imgs - meanImg)' * (imgs - meanImg) / (size(imgs,2)-1);
- 特征值分解:利用MATLAB内置函数对协方差矩阵进行分解,获取主成分系数和对应方差。
[COEFF, LATENT] = pcacov(covMat);
其中k表示满足累积方差阈值的最小主成分数目。
k = find(cumsum(LATENT)/sum(LATENT) >= 0.95, 1);
3. LDA阶段:线性判别投影
在PCA降维后的基础上,进一步优化分类边界。
- 类内与类间散度矩阵构建:遍历每个类别,分别统计类内离散程度(Sw)和类间分离程度(Sb)。
Sw = zeros(dim,k); % 初始化类内散度矩阵
Sb = zeros(dim,dim); % 初始化类间散度矩阵
for i = 1:classNum
classData = trainData(:,labels==i);
mu = mean(classData,2);
Sw = Sw + (classData - mu)*(classData - mu)';
Sb = Sb + size(classData,2)*(mu - globalMu)*(mu - globalMu)';
end - 求解广义特征问题:通过求解Sb*w = λ*Sw*w获得最优投影方向。
[V,D] = eig(Sb, Sw);
[~, idx] = sort(diag(D), 'descend');
W = V(:, idx(1:numDim));
4. 分类识别过程
完成特征提取后进入识别阶段:
- 投影到最终特征空间:
projectedTrain = W' * (trainData - globalMu);
projectedTest = W' * (testImg - globalMu); - 使用最近邻规则进行分类:计算测试样本与训练样本在低维空间中的欧氏距离,并选择最近样本对应的标签作为预测结果。
distances = sum((projectedTrain - projectedTest).^2, 1);
[~, idx] = min(distances);
predictedLabel = trainLabels(idx);
三、MATLAB代码框架与关键模块说明
1. 完整实现代码结构
% 加载ORL人脸数据库
[imgs, labels] = loadORL('path/to/orl');
% 参数设定
numTrain = 5; % 每类用于训练的样本数量
numTest = 5; % 每类用于测试的样本数量
k_pca = 50; % PCA保留的主成分数
k_lda = 30; % LDA输出维度
% 数据分割
[trainData, testData, trainLabels, testLabels] = splitData(imgs, labels, numTrain, numTest);
% 执行PCA降维
[coeff, score, ~] = pca(trainData);
trainData_pca = coeff(:,1:k_pca)' * trainData;
testData_pca = coeff(:,1:k_pca)' * testData;
% 应用LDA进行分类建模
ldaModel = fitcdiscr(trainData_pca', trainLabels);
projectedTrain = predict(ldaModel, trainData_pca);
projectedTest = predict(ldaModel, testData_pca);
% 计算识别准确率
accuracy = sum(predictedTest == testLabels)/length(testLabels);
disp(['识别准确率: ', num2str(accuracy*100), '%']);
2. 关键函数功能解释
- loadORL函数:自定义加载脚本,用于读取标准ORL人脸数据集。
loadORL() - splitData函数:按指定数目划分训练集与测试集,确保每类样本均匀分布。
splitData() - fitcdiscr函数:MATLAB提供的线性判别分析分类器,支持多类分类任务。
fitcdiscr()
四、典型应用场景
- 门禁控制系统:适用于需要快速响应的人脸验证场景,系统可在200毫秒内完成身份判定。
- 移动支付验证:集成于智能手机端,支持低分辨率环境下稳定识别人脸,保障交易安全。
- 安防监控平台:可用于大规模人脸库的实时检索,支持千万级数据库的高效匹配与追踪。
五、未来改进方向
- 融合深度学习模型:引入如ResNet等卷积神经网络提取高层次语义特征,再结合LDA进行判别优化,提升整体性能。
- 支持增量学习机制:设计可动态更新的模型架构,允许新增样本时不重新训练整个系统。
- 增强跨域适应能力:解决光照变化、姿态偏移等因素导致的泛化难题,提高算法在复杂环境下的鲁棒性。
结论
PCA+LDA联合方法在传统人脸识别中展现出良好的性能平衡:既实现了有效的维度压缩,又增强了类别区分能力。尽管面对现代深度学习技术的挑战,其结构清晰、计算高效的特点仍使其在资源受限或实时性要求高的场景中具有应用价值。结合现代优化策略后,仍有进一步发展潜力。
在保证计算效率的同时,PCA+LDA方法结合了特征降维与判别能力增强的优势,能够实现较高的识别精度。实验结果显示,该方法在ORL数据集上的识别准确率超过92%。
由于其良好的性能表现,该方法适用于对实时性要求较高的应用场景。

 京公网安备 11010802022788号
京公网安备 11010802022788号







