


 雷达卡
雷达卡



背景与现状分析
近年来,以大型语言模型(Large Language Models, LLMs)为核心的人工智能技术实现了显著突破,并在多个行业领域中展现出广泛的应用前景。然而,在提升智能化服务水平的同时,LLMs自身携带的安全隐患也逐渐暴露,尤其是在内容生成的合规性、安全性方面存在较大挑战。
为应对上述问题,学术界提出了一系列基于人类反馈的对齐方法。其中,一种主流路径是通过收集人类对模型输出的偏好判断,训练奖励模型(Reward Model, RM),再利用强化学习算法(如PPO)优化原始语言模型的生成策略,使其输出更符合人类价值观与安全规范。
这一思路最早由 Christiano P F 等人在《Deep Reinforcement Learning from Human Preferences》(2017)中系统提出,奠定了以人类偏好驱动强化学习的基础框架,成为后续研究的重要理论依据。
随后,Ouyang L 等人在《Training language models to follow instructions with human feedback》(2022)中将该方法应用于指令遵循能力的提升,成为 InstructGPT 系列模型的核心技术路径。该方法有效增强了模型对用户指令的理解与执行能力,同时在一定程度上提升了输出的安全性。
尽管如此,此类方法仍面临多重限制:依赖大量高质量人工标注数据、训练成本高昂、数据多样性不足影响泛化效果,且在面对精心设计的对抗性提示时仍可能被绕过,导致风险内容泄露。
为进一步提升模型自主治理能力,研究者提出了“宪法式对齐”(Constitutional AI)的理念。该方法通过预设一套明确的规则或原则(即“宪法”),引导模型在对话过程中自行评估、修正或拒绝不符合规范的内容,从而实现目标导向的自我约束机制。
Bai Y 等人在《Constitutional AI: Harmlessness from AI Feedback》(2022)中验证了该方法的有效性,展示了如何在无需持续人工干预的情况下,利用AI自反馈机制降低有害内容生成概率,增强模型对敏感话题的识别与规避能力。
相较于传统RLHF方法,宪法式对齐具备更高的可解释性与系统可控性,且在跨语言、跨文化场景下表现出更强的适应性。但其实际应用仍受限于规则体系的设计复杂度、更新维护难度以及覆盖范围的局限性,通常需结合人类偏好数据协同使用,以防因过度保守而导致输出质量下降。
当前人工智能风险防控面临的主要挑战
- 高对齐成本与强数据依赖: RLHF及其变体DRLHF高度依赖高质量的人工标注和持续评审,不仅成本高昂,而且难以扩展至所有应用场景,限制了规模化部署。
- 泛化性与鲁棒性不足: 模型在面对对抗性提示、提示注入攻击或跨领域、跨语言任务时表现脆弱,容易被“越狱”(Jailbreak)等手段突破安全围栏。
- 评估体系不健全: 缺乏统一、客观、可复现的评测基准,难以准确衡量不同安全机制在多样化场景下的有效性及潜在副作用(如过度过滤影响可用性)。
- 可解释性薄弱: 多层级治理流程结构复杂,外部用户难以理解为何某些内容被拦截或修改,影响信任建立与合规审计的透明度。
- 性能与安全的权衡难题: 引入多层过滤、奖励建模、PPO更新等机制会增加系统延迟、计算开销和部署复杂度,需在安全保障与响应效率之间做出平衡。
- 系统构建与维护门槛高: 需持续迭代宪法条款、风险分类标准,并适配新兴合规需求(如隐私保护、版权合规、数据溯源等),对工程实现与治理能力提出更高要求。
博特智能的技术解决方案
针对现有风险防控机制的局限性,博特智能提出一种基于多模型协同的风险识别架构,旨在通过异构模型组合与规则引擎联动,实现对生成式AI输入输出内容的高效、精准、多层次安全过滤。
系统核心架构
本方案采用多模型融合策略,构建灵活的内容过滤规则体系,具体包括以下两个关键模块:
1. 风险词库体系建设
通过构建精细化的风险关键词库与高敏提示词库,形成第一道外部拦截防线,实现对显性风险内容的快速初筛与初步判定,提升整体检测效率。
2. 多维度风险规则配置
结合不同风险敏感度的模型组合,设定四种可切换的拦截模式:宽松、较宽松、严格、较严格。根据不同业务场景的安全等级需求,动态启用相应策略,确保风险处理的灵活性与适应性。
网关级统一控制机制
为实现高效管理与便捷部署,系统引入全模型网关配置机制,支持一次配置、多端生效的安全管控模式:
- 网关集成配置: 统一定义各防护模型的访问接口、请求与响应的数据格式,实现无缝接入与内容安全中间件的即插即用。
- 服务监控与风险追踪: 提供实时监控能力,可视化展示风险内容的识别分布、拦截趋势,并支持风险事件的日志记录与后续分析,助力安全管理闭环。
综上,博特智能通过构建“词库+规则+多模型+网关”的立体化安全防御体系,有效提升大模型在复杂场景下的内容安全性、合规性与可控性,为生成式人工智能的稳健落地提供坚实支撑。
本系统采用多模型协同机制,构建了多层次的内容安全过滤体系,通过网关统一调度与控制,实现对人工智能生成内容的高效风险识别与响应处理。
在内容处理流程中,首先由已完成配置的网关接收需过滤的人工智能内容,并启动相应的处理操作:
- 用户输入内容经攻击过滤模型检测,判断是否存在潜在的攻击行为或恶意注入风险。若未通过检测,则直接触发拒答机制,不进入后续流程。
- 通过攻击检测后,系统将进一步对内容进行细粒度风险识别,输出对应的风险等级标签(如低、中、高)。若未能通过此阶段检测,将向业务方返回拒答响应。
- 根据风险标签执行差异化应答策略:针对中风险内容,启用安全模型生成合规回复;对于高风险内容,则执行拦截并拒答;若内容被判定为安全,则交由业务模型生成正常答复。
- 对业务模型输出的回答内容再次进行风险复检,确保回应的安全性。若发现敏感信息,则实施脱敏处理;若识别出存在风险,则转为拒答;仅当内容完全合规时,才允许对外输出。
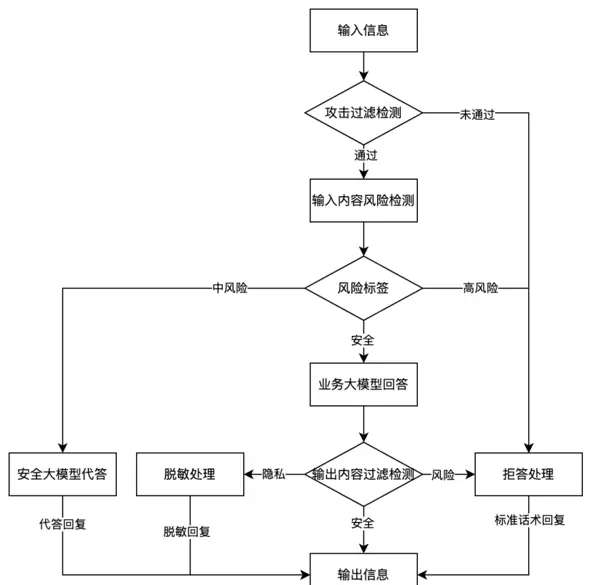
多模型组合式内容过滤规则构建
系统通过整合多个模型形成复合型过滤机制,提升风险识别的准确性与灵活性,主要包括以下两个层面:
- 风险词库建设:建立包含高危关键词与提示性语句的风险词库体系,作为第一道防线,实现对显性风险内容的快速拦截,完成初步筛查。
- 风险规则策略配置:结合风险敏感模型与风险宽松模型的不同组合方式,设定四种可切换的拦截模式——严格拦截、较严格拦截、较宽松拦截、宽松拦截,适配多样化的业务场景需求,实现精准化内容管控。
全模型网关统一配置机制
为实现一次配置、全局生效的目标,系统设计了集中式网关管理方案:
- 网关配置功能:支持对防护模型的调用方式、请求数据结构及响应格式进行标准化定义,无需改动业务逻辑即可集成内容安全能力,实现无缝过滤。
- 服务监控配置能力:提供对网关运行状态的实时监控,能够追踪风险内容的识别分布、拦截趋势,并支持对异常内容进行归集与管理,增强系统的可观测性与运维效率。
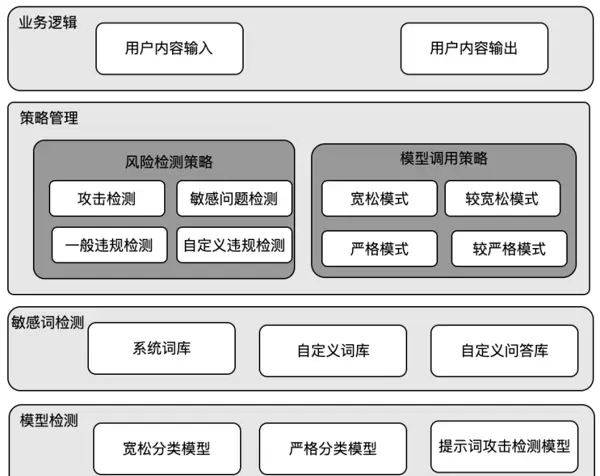
图1 系统架构
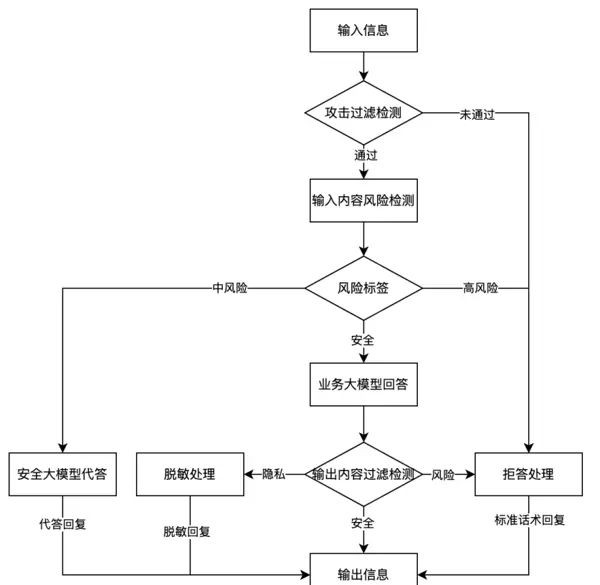
图2 风险内容过滤流程




 京公网安备 11010802022788号
京公网安备 11010802022788号







