


 雷达卡
雷达卡



实验目标
构建具备高可用性(HA)的Hadoop全分布式集群,并部署Kafka大数据处理环境与Flume数据采集开发环境,实现项目中的数据生成、采集、消费、存储、分析及可视化展示。
一、集群基础环境准备
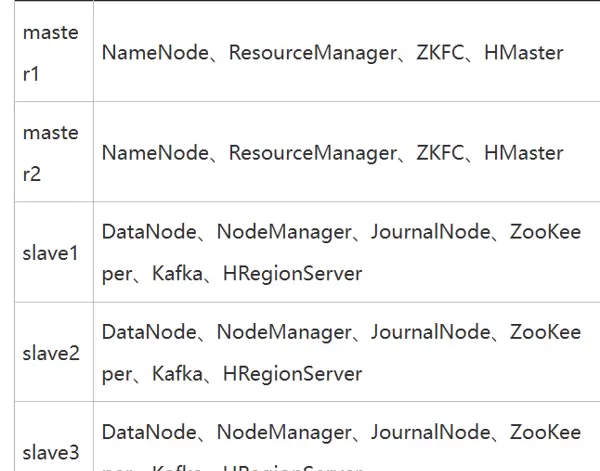
搭建包含五个节点的分布式系统架构。需预先下载并安装以下核心组件:JDK、Hadoop、HDFS、Hive、HBase、ZooKeeper、Kafka、MySQL 和 Flume。
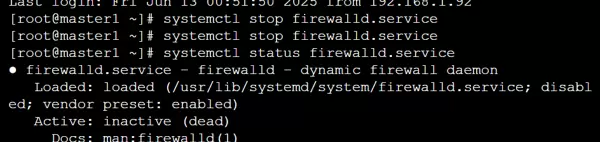
为确保各节点间通信畅通,需关闭防火墙并禁止其开机自启:
修改 SELinux 配置文件以禁用安全策略限制:

随后验证当前 SELinux 的运行状态,确认已正确设置为禁用模式:

二、网络初始化配置
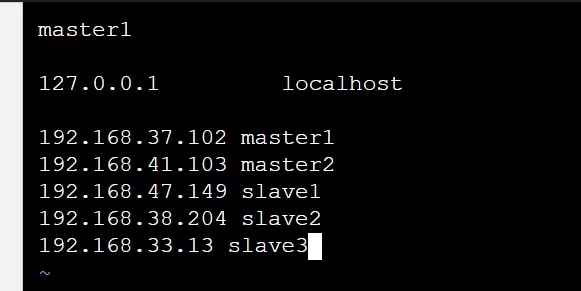
实施网络分配方案,包括调整网卡设置、设定主机名以及配置 hosts 映射关系。
使用命令 # vim /etc/hostname 对每个节点的主机名称进行重命名操作。
同时,在各节点的 hostname 文件中配置 IP 地址与域名的对应映射:
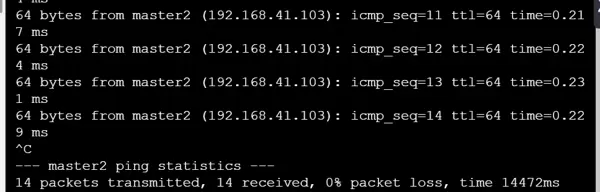
完成配置后,通过 ping 命令测试节点间的连通性,检查是否存在丢包现象,确保网络连接稳定有效:
三、SSH 免密登录配置
由于 Hadoop 集群由多个物理节点构成,频繁的密码输入会极大降低运维效率,因此需要配置节点之间的 SSH 免密码访问机制。
以 master1 节点为例:
首先执行命令生成 RSA 密钥对:

进入 .ssh 目录并将本地公钥写入 authorized_keys 文件:
cd /root/.ssh cat id_rsa.pub >> authorized_keys
接着将其他节点的公钥也合并至 master1 的 authorized_keys 中:
ssh root@master2 cat /root/.ssh/id_rsa.pub >> authorized_keys ssh root@slave1 cat /root/.ssh/id_rsa.pub >> authorized_keys ssh root@slave2 cat /root/.ssh/id_rsa.pub >> authorized_keys ssh root@slave3 cat /root/.ssh/id_rsa.pub >> authorized_keys

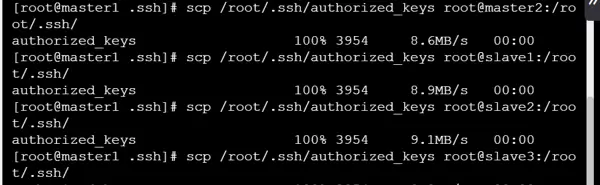
将整合后的 authorized_keys 文件分发至所有集群节点:
最后测试从 master1 到其他节点的 SSH 连接是否无需密码即可成功建立:
ssh root@master2

四、JDK 安装与环境变量配置
检查各节点 JDK 的安装情况,若未安装则进行部署并配置全局环境变量。
以 slave3 节点为例:
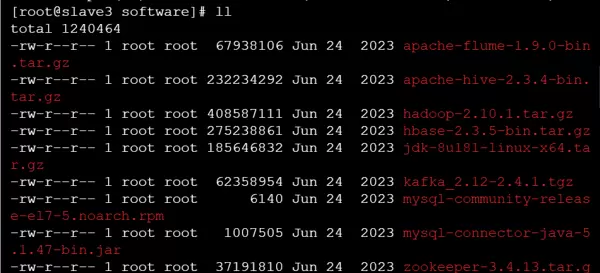
进入相应目录查看是否存在 JDK 压缩包:
解压文件后,配置 JAVA_HOME 等相关环境参数:

五、ZooKeeper 集群部署
ZooKeeper 在 HA 架构中用于主节点故障时的领导者选举,根据其投票机制要求,集群节点数量应为奇数个(即 2n+1,n ≥ 1)。本次在 slave1、slave2、slave3 上部署 ZooKeeper 服务。
以 slave2 为例,使用如下命令解压安装包至指定路径:
tar -zxf zookeeper-3.4.13.tar.gz -C /opt/app/

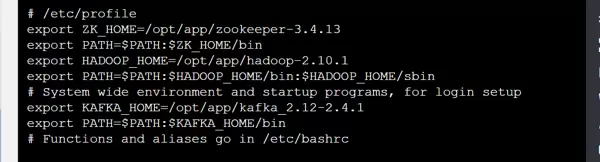
在三个 slave 节点上分别编辑 /etc/profile 文件,添加 ZooKeeper 用户环境变量:
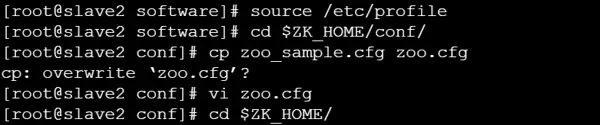
随后配置 ZooKeeper 的核心参数文件,包括 dataDir 等关键选项:
将 slave3 上已完成配置的内容同步复制到 slave1 和 slave2 节点,保持配置一致性:
最后启动三个节点上的 ZooKeeper 服务,形成高可用集群:

六、Hadoop 集群安装与配置
将 Hadoop 安装包解压至目标目录:

在所有集群节点上配置 Hadoop 运行环境:

接下来仅在 master 节点执行以下操作:
依次修改 Hadoop 相关的 XML 配置文件:
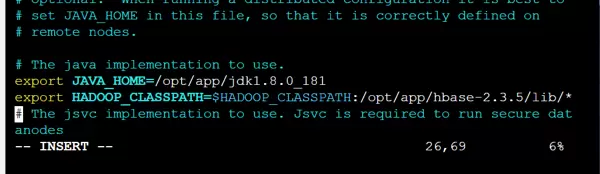
打开 hadoop-env.sh 文件,设置正确的 JAVA_HOME 路径:
vim hadoop-env.sh
编辑 slaves 文件(位于 $HADOOP_HOME/etc/hadoop 目录下),删除默认的 localhost 条目,并添加三个从节点的 IP 或主机名:
创建必要的目录结构,并将配置文件复制到对应路径:

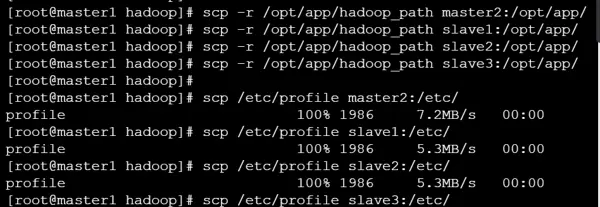
在所有节点上执行环境加载命令,使配置生效:

七、启动高可用 Hadoop 集群并处理潜在问题
首先格式化 ZKFC(ZooKeeper Failover Controller)组件:
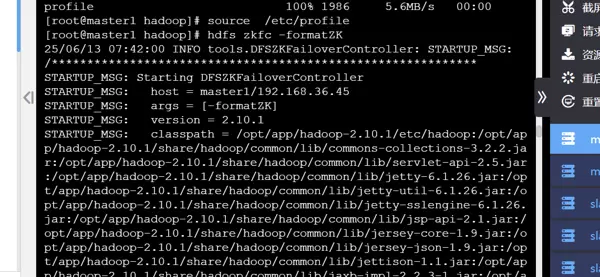
配置 HDFS 的 HA 集群名称,并查看已有命名空间:
ls /hadoop-ha
在每个 slave 节点上启动 journalnode 服务:
hadoop-daemon.sh start journalnode
对 NameNode 进行格式化操作,并将 master1 上的元数据同步至 master2 的 NameNode。
在 master1 上完成同步后,启动整个 HDFS 及 YARN 集群服务:

最后通过 jps 或相关命令查看各节点上的守护进程运行状态,确认服务正常启动。
在集群架构中,主节点与从节点的角色分配如下:
- master1 节点:运行 NameNode、ResourceManager 和 DFSZKFailoverController 服务
- master2 节点:同样部署了 NameNode、ResourceManager 和 DFSZKFailoverController 组件
- slave1 节点:作为从节点,承载 DataNode、NodeManager、JournalNode 以及 QuorumPeerMain 服务
- slave2 节点:配置与 slave1 一致,包含 DataNode、NodeManager、JournalNode 和 QuorumPeerMain
- slave3 节点:同样运行 DataNode、NodeManager、JournalNode 及 QuorumPeerMain 进程
9. HBase 的安装与部署流程
首先对 HBase 安装包进行解压,并完成环境变量的配置。
接着进入配置阶段,主要包括以下几个关键文件的设置:
- 修改
hbase-env.sh文件,配置 Java 环境及相关参数 - 编辑
hbase-site.xml文件,定义 HBase 的运行模式和存储路径 - 创建并配置
backup-masters文件,用于指定备用 Master 节点
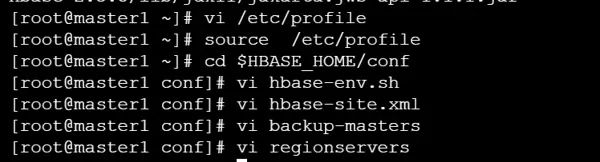
随后配置 regionservers 文件,列出所有运行 RegionServer 的主机名。

为了使 HBase 能够访问 HDFS,需将 Hadoop 的核心配置文件(如 core-site.xml 和 hdfs-site.xml)复制到 HBase 的 conf 目录下。
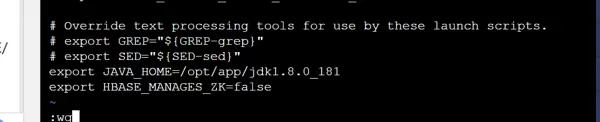
继续完善环境脚本 env.sh 的配置,确保各项参数正确无误。完成上述三个主要配置文件后,将其同步分发至集群其他节点对应目录。

全部配置就绪后,启动 HBase 集群,验证各组件是否正常运行。
10. 在 Hadoop 集群中部署 Hive
执行以下命令解压 Hive 安装包到指定目录:
tar -xzvf apache-hive-2.3.4-bin.tar.gz -C /opt/app/
将位于 /opt/software/ 目录下的 MySQL JDBC 驱动程序拷贝至 $HIVE_HOME/lib 路径下,以支持元数据存储连接。
接下来进行核心配置文件的设定:
- 配置
hive-site.xml,设置数据库连接信息、仓库路径等 - 修改
hive-env.sh,声明 Hadoop 和 Hive 的环境路径
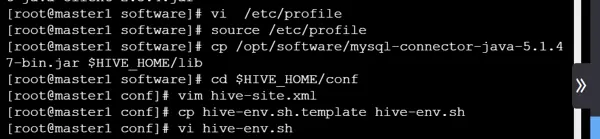
配置系统环境变量,确保 hive 命令可在任意路径下调用。

具体复制命令如下:
cp /opt/software/mysql-connector-java-5.1.47-bin.jar $HIVE_HOME/lib

完成配置后,初始化 Hive 的元数据结构,使用 schematool 工具创建数据库表。

最后启动 Hive 客户端,进入交互式查询界面。
11. 安装与配置 Java、Kafka 和 Zookeeper
首先确保 Java 环境已正确安装并配置,然后进行 Kafka 和 Zookeeper 的部署。
进入 Kafka 配置环节:

为 Kafka 创建专用的数据存储目录,用于保存日志片段。

编辑 server.properties 配置文件,设置当前 Broker 的唯一标识符:
broker.id=1
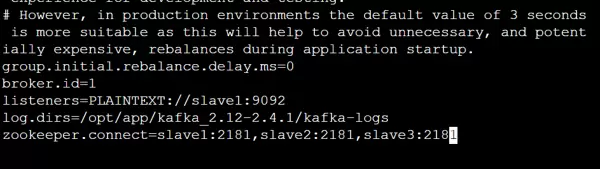
将配置好的 Kafka 目录复制到 slave2 和 slave3 节点,并分别修改其 server.properties 文件中的 broker.id 值。例如,在 slave2 上设为 2,在 slave3 上设为 3。
随后在 slave1、slave2 和 slave3 上依次启动 Kafka 的后台守护进程,确保集群通信正常。


12. Flume 环境的搭建与配置

Flume 的安装步骤如下:
- 解压 Flume 安装包至目标目录
- 配置全局环境变量,便于命令调用
- 修改 conf 目录下的配置文件,根据业务需求定义数据流
- 通过远程方式获取 Flume 所采集的数据内容
- 将采集到的数据输出并存储至 HDFS 系统中
执行解压命令:
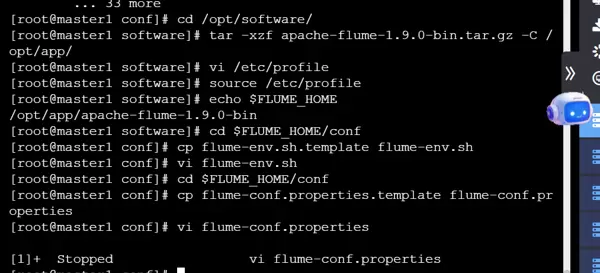
tar -xzf apache-flume-1.9.0-bin.tar.gz -C /opt/app/
在环境变量配置文件中添加以下内容:
export FLUME_HOME=/opt/app/apache-flume-1.9.0-bin
export PATH=$PATH:$FLUME_HOME/bin

进入 $FLUME_HOME/conf 目录,将模板文件 flume-env.sh.template 复制并重命名为 flume-env.sh,然后编辑该文件,添加如下配置:
JAVA_HOME=/opt/app/jdk1.8.0_181
JAVA_OPTS="-Xms100m -Xmx200m -Dcom.sun.management.jmxremote"

在相同目录下,修改 flume-conf.properties.template 文件,复制一份并更名为 flume-conf.properties,用于自定义 agent 的数据源、通道和接收器。
启动 Flume agent 的命令如下:
flume-ng agent -c ./conf/ -f ./conf/flume-conf.properties -n a1 -Dflume.root.logger=INFO,console
完成环境搭建后,进入数据生产、存储与分析阶段。
基于前期配置的环境,在 IDEA 开发工具中进行编码实现。
创建 producer 包,清理 Maven 缓存,并对整个项目执行打包操作。
生成可执行 jar 包的命令行指令如下:
cd /root/IdeaProjects/ct_producer/target
cp ct_producer-1.0-SNAPSHOT.jar /opt/app/
touch /opt/app/productlog.sh数据采集、消费与存储流程
基于 Flume 构建的数据处理链路如下图所示:
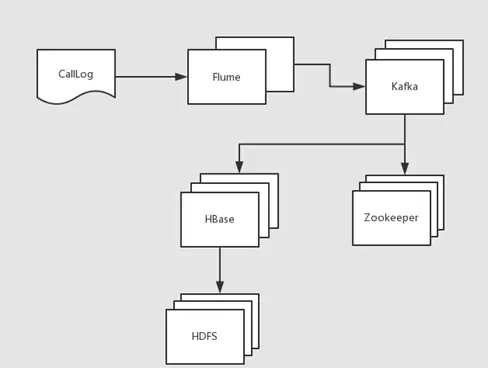
利用 Flume 实现数据的实时采集,并将采集结果发送至消息中间件 Kafka 中;Kafka 接收后对数据进行缓冲与分发,最终由下游应用将处理完成的数据写入 Hive 数据仓库,供后续分析使用。
将Hadoop的【core-site.xml】、【hdfs-site.xml】以及HBase的【hbase-site.xml】配置文件复制到项目的resources目录中,确保项目能够正确读取集群配置信息。随后,在pom.xml文件中添加所需的坐标依赖,完成项目的构建配置。 在本地开发环境中使用IDEA导入实验步骤中的相关代码,确保代码结构完整且无编译错误。
在本地开发环境中使用IDEA导入实验步骤中的相关代码,确保代码结构完整且无编译错误。
 完成代码开发后,进行以下操作:
1) 对ct_analysis项目执行打包操作,生成对应的jar文件。
2) 将MySQL的驱动包(JDBC驱动)放置于Hadoop安装目录下的lib文件夹中,以保证Hadoop任务执行时可加载数据库连接支持。
完成代码开发后,进行以下操作:
1) 对ct_analysis项目执行打包操作,生成对应的jar文件。
2) 将MySQL的驱动包(JDBC驱动)放置于Hadoop安装目录下的lib文件夹中,以保证Hadoop任务执行时可加载数据库连接支持。
cp /opt/software/mysql-connector-java-5.1.47-bin.jar $HADOOP_HOME/share/hadoop/
scp /opt/software/mysql-connector-java-5.1.47-bin.jar master2:$HADOOP_HOME/share/hadoop/
scp /opt/software/mysql-connector-java-5.1.47-bin.jar slave1:$HADOOP_HOME/share/hadoop/
scp /opt/software/mysql-connector-java-5.1.47-bin.jar slave2:$HADOOP_HOME/share/hadoop/
scp /opt/software/mysql-connector-java-5.1.47-bin.jar slave3:$HADOOP_HOME/share/hadoop/ 分析结果的展示部分采用SSM框架结合Tomcat服务器实现动态网页呈现。
分析结果的展示部分采用SSM框架结合Tomcat服务器实现动态网页呈现。
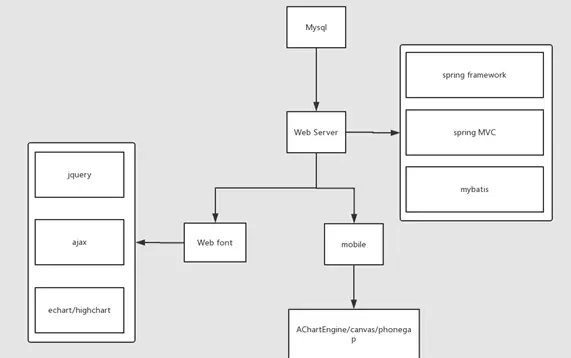 系统提供可视化界面,用户可通过点击查询按钮(btn)实时获取数据并生成对应图表,直观展示分析结果。
系统提供可视化界面,用户可通过点击查询按钮(btn)实时获取数据并生成对应图表,直观展示分析结果。


 京公网安备 11010802022788号
京公网安备 11010802022788号







