


 雷达卡
雷达卡



前言
随着大模型在企业场景中的应用不断深化,RAG(检索增强生成)技术已成为提升模型输出准确性、可控性与可解释性的核心技术之一。然而,构建一个高效且稳定的 RAG 系统,并非简单地将文本嵌入(Embedding)后存入向量数据库即可完成。它需要一套完整的基础设施来支持文档处理、知识组织以及多样化的检索模式。在 LlamaIndex 框架中,这一核心能力由 Index 提供。
作为 LlamaIndex 最关键但常被忽视的组件,Index 不仅负责将原始文档转化为结构化数据单元,还承担着知识组织、检索路由与查询优化等多重职责。如果说 RAG 系统是一辆汽车,那么 Index 就是驱动整辆车运行的引擎。本文将深入剖析 Index 的设计思想、工作机制、常见类型、构建流程及其与 Query Engine 和 Chat Engine 的协作关系,帮助开发者更高效地搭建高质量的 RAG 应用。
1. 什么是 Index?
1.1 Index 的定义与核心功能
LlamaIndex 官方对 Index 的描述如下:
Index 是一种用于从用户查询中快速检索相关上下文的数据结构,是实现 RAG 的基础。
尽管表述简洁,但这句话揭示了三个重要信息:
- 它是一种数据结构,而非单纯的数据库或模型;
- 其目标在于快速检索,强调响应速度和结果的相关性;
- 它是为问答和对话任务专门设计的,服务于RAG 流程。
换句话说,Index 是数据进入 RAG 系统的“入口”与“调度中心”,决定了以下关键环节:
- 原始文档如何被切分;
- 内容如何转换为 Node 单元;
- 是否进行向量化及结构化处理;
- 最终采用何种检索逻辑返回结果。
从系统架构来看,Index 实现了一层抽象封装:
输入 → 文档(Documents)
输出 → 检索器(Retriever)
而上层的 Query Engine 与 Chat Engine 均建立在此之上,依赖 Index 提供的检索能力。
1.2 Index 的三层数据结构:Documents → Nodes → Index
为了便于管理和高效检索,LlamaIndex 将所有输入文档统一划分为三个层级:
| 层级 | 含义 | 主要内容 | 作用 |
|---|---|---|---|
| Documents | 原始文档 | 文本文件、PDF、网页内容、数据库导出数据等 | 作为系统的初始数据来源 |
| Nodes | 文档片段 | 经过分割的文本块,附带 metadata 信息 | 决定检索的基本粒度 |
| Index | 节点组织结构 | 基于向量、树形、关键词等方式组织的结构 | 提供高效的检索能力 |
其中,Node 层最为关键,每个 Node 包含以下要素:
- 具体的文本内容(chunk);
- 原文位置信息(用于引用溯源);
- 关联的 metadata(如作者、时间、路径等);
- 结构化关系(如前后节点链接、所属章节等)。
Index 正是在这些 Node 的基础上,将其组织成适合特定检索方式的结构,从而支撑后续的查询过程。
2. 为什么说 Index 是 RAG 的核心?
2.1 RAG 的本质是检索质量的问题
无论使用何种模型,典型的 RAG 工作流都遵循以下链条:
- 接收用户提问;
- 判断模型是否具备直接回答的能力;
- 若无,则触发知识检索流程;
- 基于检索到的内容生成答案。
在这个过程中,能否准确获取相关的背景知识,直接决定了最终输出的质量。即使语言模型再强大,如果检索阶段未能命中关键信息,依然会产出错误或无关的回答。
Index 的核心使命正是解决以下问题:
- 如何合理拆分文档以保留语义完整性?
- 如何提高检索结果的相关性?
- 如何利用 metadata 进行精准过滤?
- 如何平衡查准率与查全率?
- 如何协调不同类型数据(如文本、表格)的联合检索策略?
正因如此,在 LlamaIndex 中,Index 的地位远高于单纯的向量存储——它不仅管理数据,更定义了整个系统的检索逻辑与策略。
2.2 统一检索接口:Retriever 的角色
在实际开发中,我们往往面临多种检索需求,包括但不限于:
- 向量相似度检索;
- 关键词匹配查询;
- 混合检索(结合语义与关键词);
- 基于 metadata 的条件过滤;
- rerank 排序优化;
- 多模态内容检索(图文混合)。
面对这种复杂性,LlamaIndex 通过 Retriever 提供了一个统一的对外接口。
无论底层使用的是 Faiss、Milvus、Weaviate、ElasticSearch,还是本地 JSON 文件系统,Retriever 都保持一致的调用方式。它的主要功能涵盖:
- 执行 top-k 相似度检索;
- 融合不同来源的检索结果并加权排序;
- 集成 reranker 模块重新调整顺序;
- 支持自定义过滤规则(如按文档类型筛选);
- 允许构建可插拔的检索流水线(pipeline)。
因此,“Index + Retriever” 构成了一个高度抽象的检索中间层,使得整个系统具备良好的扩展性和灵活性。
3. Index 的内部结构与构建流程
要真正掌握 Index 的作用机制,需了解其完整的构建路径。
3.1 文档加载与预处理
当原始文档进入系统时,首先经历一系列标准化处理步骤:
- 清理格式异常字符;
- 提取非纯文本内容(如 PDF 中的文字、HTML 标签解析);
- 识别段落结构(标题、列表、章节划分);
- 注入附加 metadata(如文件路径、创建时间等)。
该阶段确保输入数据的一致性与可用性,为后续处理打下基础。
3.2 节点切分(Node Parsing)
这是影响检索效果的核心环节之一。
常见的 Node 切分策略包括:
- 按固定长度切分(例如每 512 个 token 一段);
- 依据自然段落、标题或章节边界进行分割;
- 采用语义感知方法自动识别语义断点;
- 特殊处理结构化内容(如表格、项目符号列表)。
每一个生成的 Node 都包含:
- 实际文本内容;
- 指向原始文档的位置信息;
- 上下文连接关系(前驱/后继 Node);
- 继承自原文档的 metadata。
合理的切分策略能显著提升检索的精确度与上下文连贯性。
3.3 向量化处理(Embedding)
在 Node 创建完成后,系统会对每个文本块进行向量化编码。这一步通常借助预训练模型(如 BERT、Sentence-BERT 或 OpenAI embeddings)完成。
生成的向量被存储于 Index 所管理的结构中(如向量索引),并与对应的 Node 建立映射关系。此过程使得后续可通过语义相似度计算快速定位相关内容。
此外,部分高级 Index 类型还会同时维护关键词索引或其他辅助结构,以支持混合检索模式。
每个 Node 都会被转换成一个 embedding,用于实现向量检索功能。LlamaIndex 对所使用的 embedding 模型没有强制限制,用户可根据需求灵活选择,常见的模型包括:
- OpenAI text-embedding-3-large
- bge-large-zh
- jina embeddings
- 本地部署的 embedding 模型
4 常见 Index 类型及其适用场景
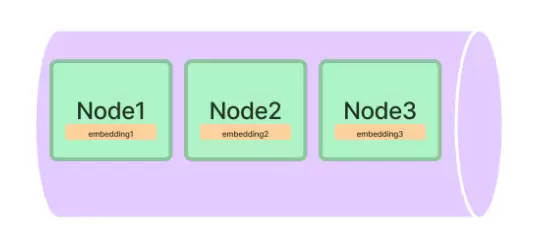
4.1 VectorStoreIndex:最常用的向量索引结构
该索引适用于所有典型的 RAG(Retrieval-Augmented Generation)应用场景,是系统默认推荐的选择。其主要特性包括:
- 基于向量相似度进行匹配
- 兼容主流向量数据库
- 检索速度快,召回结果稳定
- 支持 metadata 过滤条件
- 可与 reranker 模块良好集成
目前在 LlamaIndex 的实际应用中,VectorStoreIndex 是使用频率最高的索引类型。
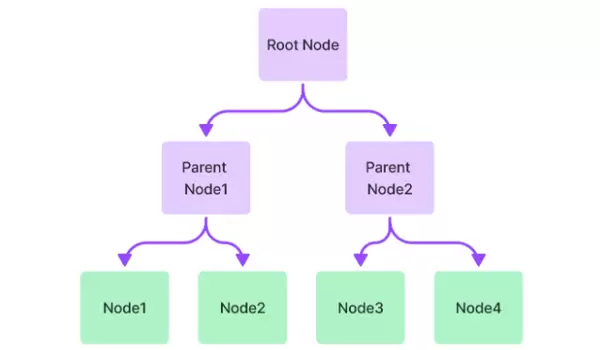
4.2 TreeIndex:适用于长文档内容总结
TreeIndex 将文档组织为多层级树状结构:
- 底层节点为原始文本分块(Node)
- 中间层由系统自动生成的摘要节点构成
- 顶层保存整个文档的全局摘要
这种结构特别适合以下场景:
- 处理超长文本并生成逐层摘要
- 支持分层次阅读和理解
- 应用于结构化程度高的文档类型,如法律条文或技术规范
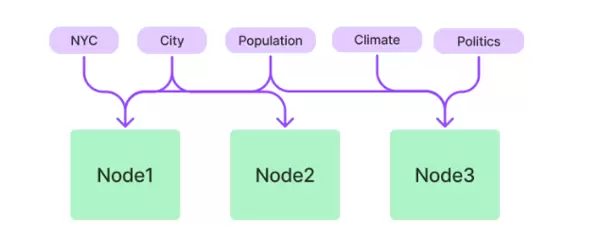
4.3 KeywordTableIndex:面向关键词检索的索引方式
此索引适用于术语固定、结构清晰的文档集合,无需依赖 embedding 向量进行检索。典型用例包括:
- 法律法规文档
- 操作手册
- API 接口说明文档
通过关键词表直接定位相关内容,提升精确匹配能力。
4.4 SummaryIndex:用于多文档或非结构化文本的摘要整合
该索引主要用于对多个文档或无明确结构的文本进行统一梳理与汇总,适用场景包括:
- 多份文档的内容聚合与总结
- 会议纪要的信息提炼
- 非结构化文本的数据预处理与组织
5 Retriever:作为 Index 的统一对外接口
Retriever 是 Index 功能输出的核心组件,提供了标准化的检索能力封装,主要包括:
- TopK 相似性搜索
- 基于 metadata 的条件过滤
- 混合检索(Hybrid Retrieval)支持
- 与 reranker 模块的协同工作
- 允许自定义检索逻辑与策略
这一抽象层极大增强了 RAG 系统的灵活性,使得不同类型的 Index 可以无缝切换,适应多样化的业务需求。
6 Index、Query Engine 与 Chat Engine 的关系解析
为了更清楚地理解 Index 在 LlamaIndex 整体架构中的核心地位,以下表格展示了各组件的功能划分:
| 组件 | 输入 | 输出 | 主要作用 |
|---|---|---|---|
| Index | 文档数据 | Retriever | 构建和管理知识库 |
| Query Engine | 用户查询请求 | 响应结果 | 执行问答、摘要生成及检索增强任务 |
| Chat Engine | 多轮对话上下文 | 回复内容 | 提供具备上下文记忆的智能对话能力 |
整体工作流程如下:
- 用户提出问题
- Chat Engine 调用 Query Engine 处理请求
- Query Engine 利用 Retriever 发起检索
- Retriever 向 Index 查询相关节点
- Index 返回匹配的 Node 列表
- 大模型基于这些 Node 内容生成最终答案
由此可见,Index 构成了整个系统中数据存储与检索的基础支撑层。
7 实战演示:构建一个最小可用的 Index 示例
以下是搭建一个基础 RAG 系统的最简代码示例:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("什么是微服务?")
print(response)
在实际生产环境中,你可以进一步扩展功能,例如:
- 接入 Faiss、Milvus 等专用向量数据库
- 替换为自定义的 embedding 模型
- 配置 reranker 提升排序质量
- 添加 metadata 过滤规则以支持精细化检索
结语
在快速演进的 RAG 技术生态中,LlamaIndex 中的 Index 扮演着“知识组织者”的关键角色——它位于向量数据库之上,又比 Query Engine 更贴近原始数据,是整个知识处理链条的核心枢纽。
深入理解 Index 的机制,不仅能帮助开发者构建高效且稳定的检索系统,还能根据具体业务需求灵活选择最优策略,进而打造可控、可解释、可扩展的企业级 RAG 应用。
无论采用本地模型、云服务还是混合部署模式,Index 均可作为统一的知识管理中枢,为各类 RAG 系统奠定坚实的数据基础。

 京公网安备 11010802022788号
京公网安备 11010802022788号







