


 雷达卡
雷达卡



低代码实现文本生成需求:Dify平台开发实战全解析
随着大模型技术的广泛应用,文本生成正成为企业数字化进程中的关键能力。无论是营销内容创作、知识文档管理,还是多语言本地化与SEO内容批量生产,高效、智能的文本自动化工具已成为刚需。Dify作为领先的低代码Agent开发平台,通过“提示词模板 + 变量配置 + 批量运行 + API对接”的架构设计,显著降低了企业级文本应用的开发门槛。无需掌握复杂的NLP算法或编程技能,业务人员与开发者均可快速构建功能完整的文本处理系统。
本文将深入剖析Dify在文本生成场景下的核心能力,并结合一个全新实战案例——多语种学术论文摘要翻译助手,系统讲解其开发流程与落地方法。
一、Dify文本应用的核心功能体系
Dify的设计理念在于“灵活适配”与“高效部署”,其功能覆盖了从输入到输出的完整文本处理链路,主要由四大模块构成:
1. 低门槛开发模式,提升构建效率
- 可视化操作界面:无需编写代码,通过拖拽组件、设置变量和编辑提示词即可完成应用搭建。
- 模块化组合机制:支持将提示词模板、变量、知识库及外部工具进行自由组合,满足多样化业务场景的定制化需求。
- 多模型兼容性:可接入OpenAI、DeepSeek、Qwen等主流大模型,根据实际需求灵活切换,在生成质量与调用成本之间实现平衡。
2. 全面的文本处理能力,覆盖多种应用场景
Dify适用于各类“文本加工”任务,典型应用包括:
- 信息提炼:如长文本摘要生成、科研论文要点提取、新闻事件关键点归纳,广泛用于媒体监测与学术研究领域。
- 语言处理:支持多语种互译、文本润色改写、术语标准化处理,适用于跨境业务沟通与专业写作场景。
- 内容创作:可自动生成广告文案、SEO优化文章、创意脚本等内容,助力市场推广与内容运营团队提效。
- 结构化内容生成:能自动产出简历、合同条款、实验报告、FAQ页面等格式化文档,推动办公流程自动化。
3. 支持批量处理与API集成,实现高效交付
- 双运行模式:既支持单条文本即时处理,也支持通过CSV文件批量导入数据,一次性生成数百甚至上千条结果,满足规模化内容生产需求。
- 自动API生成:应用发布后会自动生成RESTful API接口,便于与企业内部系统(如ERP、CMS、电商平台)无缝对接,打通业务闭环。
- 结果导出便捷:批量运行后的输出结果可直接导出为CSV文件,用于后续的内容发布、广告投放等环节。
4. 知识库融合能力,确保内容准确性
支持上传术语表、风格指南、行业规范等文档作为知识库,借助RAG(检索增强生成)技术,使大模型在生成过程中参考指定资料,避免出现术语不一致、表达不规范等问题。特别适用于对术语统一性要求高的场景,如品牌传播、学术出版、合规文档撰写等。
二、Dify文本应用的标准开发流程
无论面对何种文本生成任务,Dify均遵循一套清晰、可复用的开发路径:“新建应用 → 配置核心组件 → 调试预览 → 发布运行”。该流程逻辑严谨、步骤明确,极大提升了开发效率。
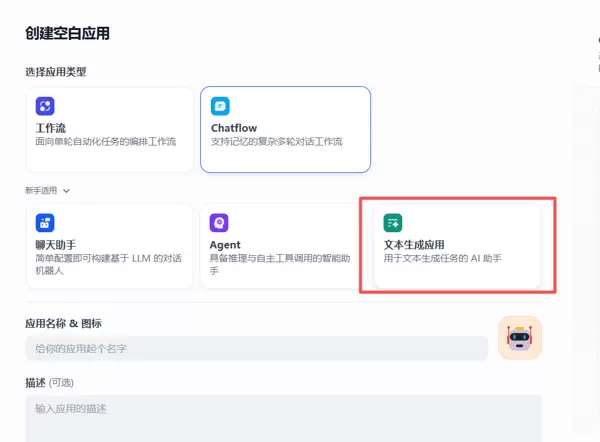
- 创建新应用:在Dify工作区选择“文本生成应用”类型,填写名称与描述,例如“学术论文摘要翻译助手”。
- 定义变量结构:依据具体使用场景设定变量,如源文本、源语言、目标语言、学科类别等,支持文本、下拉选项、数字、段落等多种数据类型。
- 编写提示词模板:明确模型需执行的任务指令、输出格式要求以及变量替换规则,确保生成结果符合预期标准。
- 配置知识库(可选):上传相关术语文档或风格规范,提升生成内容的专业性与一致性。
- 调试与测试:输入样例数据进行预览,检查输出效果,必要时调整提示词逻辑或变量设置。
- 发布并运行:支持三种方式:单次执行、批量运行(上传CSV文件)、或通过API接口接入外部系统。
三、实战演练:构建多语种学术论文摘要翻译助手
针对科研人员在论文发表与文献阅读中面临的语言障碍问题,我们设计并实现了一个“多语种学术论文摘要翻译助手”。该应用需具备以下能力:支持跨学科术语准确转换、多语言互译、保持原文结构,并兼容单条处理与批量操作,最终服务于高校、研究院所等科研团队。
1. 应用目标与使用场景
典型场景:研究人员需将中文或英文的论文摘要翻译成日语、德语、法语等目标语言,要求翻译结果术语精准(如计算机科学、生物学等领域专用词汇统一)、结构完整(保留“目的-方法-结果-结论”框架)、语气正式且符合学术规范。
核心目标:
- 支持多维度变量配置,包括源文本、源语言、目标语言、学科领域、格式模式等;
- 集成各学科术语表知识库,保障术语翻译的一致性;
- 提供单次翻译与CSV批量处理功能,结果支持导出;
- 预留API接口,便于未来与科研管理系统集成。
2. 应用架构设计
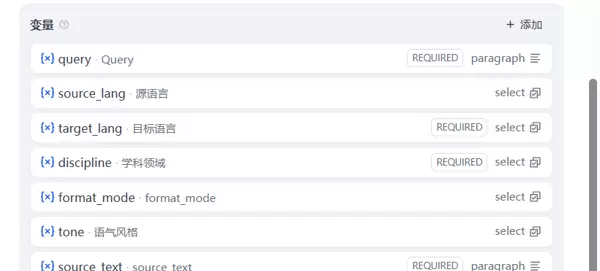
(1)变量设计:通过多个变量覆盖核心功能需求
| 变量名 | 类型 | 说明 | 可选值/默认值 |
|---|---|---|---|
| source_text | 段落(必填) | 待翻译的论文摘要内容 | - |
| source_lang | 下拉(可选) | 源语言识别 | auto(自动识别)、zh-CN、en-US |
| target_lang | 下拉(必填) | 目标语言选择 | ja-JP(日语)、de-DE(德语)、fr-FR(法语)、ko-KR(韩语) |
| discipline | 下拉(必填) | 所属学科领域,用于匹配对应术语表 | computer(计算机)、biology(生物)、physics(物理)、chemistry(化学) |
| format_mode | 下拉(可选) | 输出格式控制策略 | plain(纯文本)、markdown(保留标题层级) |
| tone | 下拉(可选) | 语言风格设定 | formal(正式学术)、neutral(中性) |
通过上述变量配置,用户可在前端灵活选择参数组合,系统则根据所选学科动态加载对应的术语知识库,确保翻译的专业性与一致性。
(2)知识库设定
上传各学科的术语对照表(采用Markdown格式),参考示例如下:
- 计算机学科: “transformer模型 → transformer模型(保留英文); 预训练 → 事前学習(日语)、Vortraining(德语)”
- 生物学科: “基因编辑 → 遺伝子編集(日语)、Genomeditierung(德语); CRISPR → CRISPR(保留英文)”
术语表规范说明:品牌名称、专有术语及模型/方法名称均保留原始英文形式,学科通用术语则依据统一译法进行转换。
(3)提示词模板设计(明确翻译规则)
你是一位专业的学术翻译专家,专注于多领域论文摘要的精准翻译。请依照以下准则执行翻译任务:
基础要求:
- 语言适配性:源语言为{{source_lang}}(若标记为auto则自动识别),目标语言为{{target_lang}},确保语法正确且符合目标语言的学术表达习惯。
- 术语一致性:严格遵循已配置的{{discipline}}学科术语表,所有品牌名、专有名词以及模型或方法名称不作翻译,维持原始格式。
- 格式还原度:当{{format_mode}}设为markdown时,保留原文中的标题层级与列表结构,仅对正文内容进行翻译;若为plain模式,则保证段落逻辑清晰连贯。
- 语气风格控制:根据{{tone}}指定的风格输出,默认使用academic(学术正式)语气,避免口语化或非正式表达。
- 结构完整性:翻译后的摘要必须包含“研究目的—研究方法—研究结果—研究结论”四个核心部分,不得遗漏关键信息。
- 输出纯净性:仅返回最终翻译文本,不附加任何解释、注释或格式说明。
待处理原文:
{{source_text}}
3. 单条摘要翻译示例
输入参数:
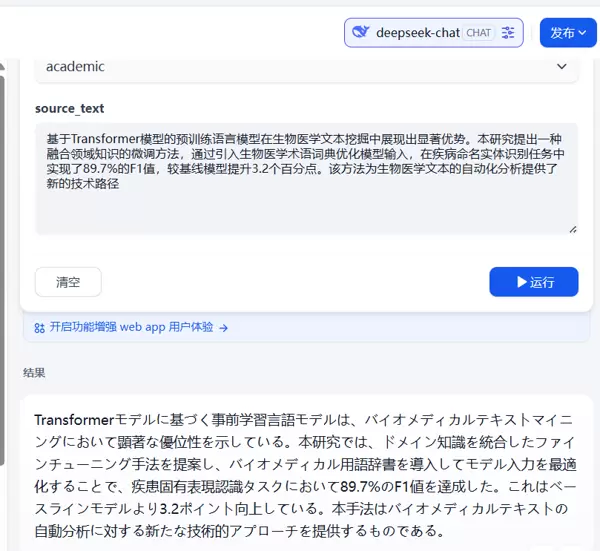
- source_text: “基于Transformer模型的预训练语言模型在生物医学文本挖掘中展现出显著优势。本研究提出一种融合领域知识的微调方法,通过引入生物医学术语词典优化模型输入,在疾病命名实体识别任务中实现了89.7%的F1值,较基线模型提升3.2个百分点。该方法为生物医学文本的自动化分析提供了新的技术路径。”
- source_lang:zh-CN
- target_lang:ja-JP(日语)
- discipline:biology(生物)
- format_mode:plain
- tone:academic
翻译结果:
“Transformerモデルに基づく事前学習言語モデルは、バイオメディカルテキストマイニングにおいて顕著な優位性を示している。本研究では、ドメイン知識を統合したファインチューニング手法を提案し、バイオメディカル用語辞書を導入してモデル入力を最適化することで、疾患固有表現認識タスクにおいて89.7%のF1値を達成した。これはベースラインモデルより3.2ポイント向上している。本手法はバイオメディカルテキストの自動分析に対する新たな技術的アプローチを提供するものである。”
4. 多条摘要批量翻译流程
步骤一:准备CSV数据文件
需包含以下字段的待翻译摘要数据:
| source_text | source_lang | target_lang | discipline | format_mode | tone |
|---|---|---|---|---|---|
| (计算机学科摘要)“Large language models have shown strong capabilities in code generation, but still face challenges in handling complex algorithm design tasks. This paper proposes a hybrid framework combining rule-based reasoning and neural networks…” | en-US | de-DE | computer | plain | academic |
| (物理学科摘要)“Quantum entanglement is a key concept in quantum mechanics, and its application in quantum communication has attracted extensive attention. This study verifies the stability of entanglement in long-distance transmission…” | en-US | fr-FR | physics | plain | concise |
步骤二:上传并执行批量处理
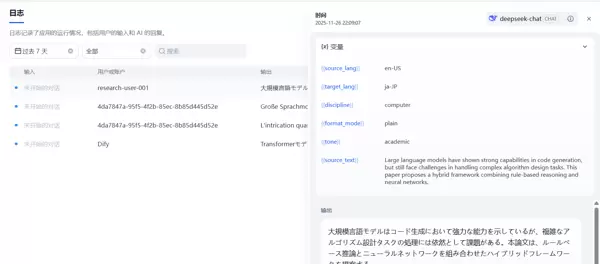
进入Dify应用界面,选择“批量运行”功能,上传上述CSV文件。系统将依据预设变量和提示词模板,自动完成多条摘要的翻译生成。
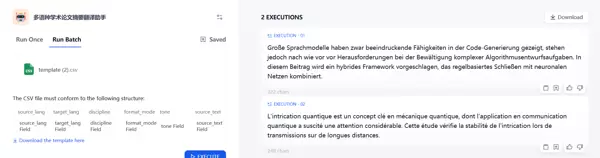
这里在实际运行中有个bug,如果在设置字段时输入的中文显示,下载的模板中字段是中文,就会报错步骤三:查看批量输出结果(部分样例)
计算机学科摘要(翻译为德语):
Dify文本应用凭借“低代码+高灵活度”的架构设计,突破了传统文本生成工具在应用场景和技术使用上的限制,展现出显著的核心优势:
- 业务人员无需深厚技术背景即可直接参与应用开发,将实际需求快速转化为可运行的解决方案;
- 支持从单条文本处理到批量自动化生产的完整流程,能够灵活适配从小范围验证到大规模部署的不同阶段;
- 通过知识库集成与多变量配置机制,确保输出内容的准确性与一致性,满足企业在合规性方面的严格要求。
在学术翻译之外,该应用还具备广泛的扩展潜力,可应用于品牌标准化话术生成、跨平台广告文案优化、电商平台商品描述的多语言本地化等多个场景。仅需调整提示词模板与变量结构,即可实现对新业务场景的快速响应与适配。
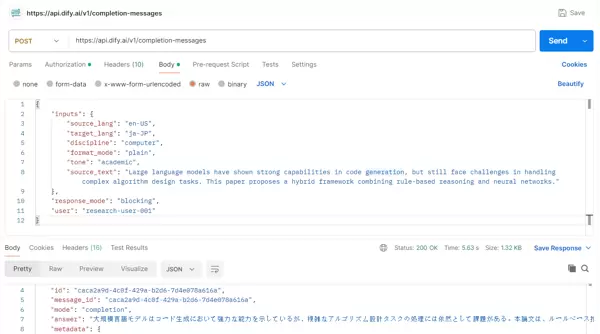
系统上线后,可通过以下API接口与科研管理系统对接,实现翻译任务的自动化调用:
curl -X POST 'https://api.dify.ai/v1/completion-messages' \
-H 'Authorization: Bearer {API_KEY}' \
-H 'Content-Type: application/json' \
-d '{
"inputs": {
"source_lang": "en-US",
"target_lang": "ja-JP",
"discipline": "computer",
"format_mode": "plain",
"tone": "academic",
"source_text": "Large language models have shown strong capabilities in code generation..."
},
"response_mode": "blocking",
"user": "research-user-001"
}'
开发者亦可借助Postman等工具进行接口测试与调试:
量子纠缠作为量子力学中的核心概念,其在量子通信领域的应用已引发广泛关注。本研究重点考察了长距离传输过程中纠缠态的稳定性表现,验证了其在复杂环境下的保持能力。
尽管大型语言模型在代码生成方面表现出较强能力,但在应对复杂算法设计任务时仍面临一定挑战。本文提出一种融合规则推理与神经网络的混合式框架,旨在提升模型在逻辑严密性与结构化思维方面的表现。

 京公网安备 11010802022788号
京公网安备 11010802022788号







