


 雷达卡
雷达卡



告别“单一评论”与“AI幻觉”!多模态虚假新闻检测新模型准确率超95%
随着新媒体和社交平台的快速发展,虚假新闻借助网络传播的即时性与广泛性迅速扩散,造成社会恐慌、误导公众判断,甚至影响金融市场稳定。例如,“美国白宫爆炸”这一虚假消息曾在两分钟内导致道琼斯指数骤降100点。为应对这一挑战,虞永毅、肖聪等人提出一种融合多元评论与三重视角分析的新型多模态虚假新闻检测方法,在多个主流数据集上实现突破性性能表现。
研究背景:传统方法的局限与LLM带来的新风险
当前虚假新闻检测面临两大核心问题:一是依赖“单一评论”导致模型泛化能力不足;二是大语言模型(LLM)虽具备强大分析能力,但易产生“幻觉”——即生成与事实不符的内容,严重影响检测准确性。
早期检测技术通常仅基于真实用户评论或纯文本内容进行判断,缺乏对多样化观点的捕捉能力,如同烹饪时只使用单一调料,难以适应复杂场景。而近年来兴起的LLM方法虽然能自动生成评论辅助分析,却存在“编造信息”的风险。例如,即便原始新闻中提及“某地降雨50毫米”,LLM可能误判为“100毫米”,从而引入错误信号。
针对这些问题,研究团队提出了结合真实评论与可控生成评论,并通过多层级机制抑制幻觉影响的新范式。

核心创新:三大策略协同提升检测精度
1. 多元评论融合:构建更全面的舆论视角
为克服评论数量不足与多样性缺失的问题,该研究采用GLM-4-flash生成8条模拟评论,同时考虑性别(男/女)、年龄(5个阶段)、教育程度(3类)、立场及宗教信仰等5类用户属性,使生成评论在风格与观点分布上更贴近真实社交环境。随后将这些结构化生成评论与新闻附带的真实评论相结合,形成互补优势:真实评论提供自然表达与情感倾向,生成评论弥补样本稀疏性并增强覆盖广度。
2. 三重视角抗幻觉机制:层层过滤虚假信号
为有效控制LLM生成过程中的“幻觉”干扰,研究设计了由浅入深的三级评估体系:
- 自我审查:首先由生成模型自身对其输出评论进行一致性校验,识别并修正明显与原文矛盾的信息;
- 同行评估:引入外部高参数模型DeepSeek-R1-32B作为独立评审方,进一步挖掘潜在逻辑偏差与隐性幻觉;
- 综合评测:最终通过深度神经网络中的SA/CA层与跨模态融合模块完成整体评估,确保前两步未能捕捉的细微错误也被有效排除。
这种分层过滤机制显著提升了系统鲁棒性,降低了因单点错误引发误判的风险。
3. 跨模态信息深度融合:从拼接到对齐
不同于传统方法简单拼接图文特征,本研究采用精细化对齐策略:
利用Swin-T模型提取图像局部细节(如篡改痕迹、异常构图),并通过BERT捕获文本深层语义(如逻辑漏洞、夸张表述)。在此基础上,借助CLIP实现图文语义空间的初步对齐,并通过交叉注意力机制完成跨模态特征交互,充分挖掘图文不一致这一关键造假线索。
此外,模型还引入动态评论交互融合模块,自动加权真实评论与生成评论的重要性,聚焦关键信息源,进一步削弱生成评论中残留幻觉的影响。
实验结果:性能全面超越现有基线
在Weibo、Weibo21和GossipCop三个公开数据集上的测试表明,该方法取得了显著提升:
- Weibo 数据集:准确率达 95.1%,较最新基线提升5.0个百分点,较纯LLM基线提升13.2%;
- Weibo21 数据集:准确率为 93.1%,优于现有方法1.4个百分点,领先LLM基线15.2%;
- GossipCop 数据集:达到 88.3% 的准确率,分别高出两类基线2.7%和16.6%。
上述结果验证了多元评论输入与三重抗幻觉机制的有效性,尤其在中文社交媒体环境中展现出强大的适应能力。
论文基本信息
标题:基于多元评论和三重视角的多模态虚假新闻检测
作者及单位:
虞永毅1)、肖聪2)、王明文1)、黄琪1)、罗文兵1)、朱莹婷3)
1) 江西师范大学 人工智能学院(南昌 330022)
2) 江西师范大学 财务处(南昌 330022)
3) 南昌师范学院 数学与信息科学学院(南昌 330032)
引文格式(GB/T 7714):
虞永毅, 肖聪, 王明文, 等. 基于多元评论和三重视角的多模态虚假新闻检测[J/OL]. 计算机学报, 2025-11-19. https://link.cnki.net/urlid/11.1826.TP.20251119.1319.014
网络首发日期:2025-11-19
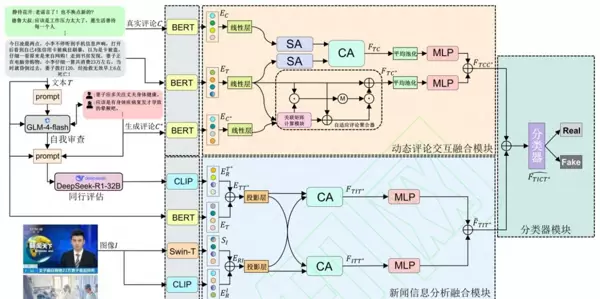
研究方法:四步拆解复杂模型,实现高效虚假新闻检测
尽管该论文提出的模型结构看似复杂,但其核心流程可清晰划分为四个步骤:“数据预处理 → 评论融合 → 图文与分析信息融合 → 最终分类”。这一“四步走”策略使得整个系统逻辑分明、模块化强,便于理解与优化。
第一步:数据准备——构建多元评论与抗幻觉分析数据集
生成多样化评论:针对每条新闻内容,利用 GLM-4-flash 模型,依据5类用户属性生成8条模拟评论,从而构造出具有代表性的“生成评论”集合,增强数据多样性。
三重分析机制提升可靠性:
- 自我审查阶段:由 GLM-4-flash 对原始新闻及其生成的评论进行初步分析,输出第一轮判断报告;
- 同行评估阶段:引入 DeepSeek-R1-32B 模型对同一新闻再次分析,提供更严谨、低幻觉的补充视角,形成高质量的“抗幻觉分析数据”。
第二步:动态评论交互融合——整合真实与生成评论信息
特征统一编码:使用 BERT 模型将新闻正文、真实用户评论以及生成评论全部转换为向量表示,并通过线性层将其映射至相同维度空间,确保后续操作的一致性。
自注意力机制(SA):如同“放大镜”,聚焦于关键语义单元,如新闻中的时间、地点、事件主体,以及评论中体现理性推理的部分,有效过滤噪声和无关内容。
交叉注意力机制(CA):作为“桥梁”,连接新闻文本与真实评论。例如当文本声称“某产品有害”时,CA 层会主动检索评论中支持或反驳该观点的相关证据片段。
自适应门控聚合:针对生成评论可能存在的“幻觉”问题,设计动态门控机制,智能筛选并剔除不可靠信息,保留可信度高的内容。
特征拼接融合:最终将“文本+真实评论”与“文本+生成评论”的融合特征分别组合,形成综合性的“评论融合特征”。
第三步:多模态信息深度融合——图文与LLM分析协同工作
多角度特征提取:
- 图像侧:采用 Swin-T 提取图像局部细节(如是否存在PS痕迹),同时使用 CLIP 获取图像的全局语义表达;
- 文本侧:借助 BERT 捕捉深层语义,并融合 LLM 输出的新闻分析结果,构建“文本融合特征”。
模态语义对齐:通过 CLIP 模型将文本、图像和 LLM 分析结果映射到统一的语义空间中,解决不同模态间“各说各话”的问题,实现跨模态一致性。
双向交叉注意力融合:建立图像与文本之间的深度互动机制。例如,若文本描述为“晴天”,而图像显示下雨场景,模型能够迅速识别此类矛盾,进而生成更具判别力的“图文融合特征”。
[此处为图片3]第四步:分类决策——输出真假判定结果
将前两步获得的“评论融合特征”与“图文融合特征”进行拼接,输入带有 softmax 函数的分类器中。训练过程中采用交叉熵损失函数,经过充分训练后,模型输出每条新闻属于“真实(1)”或“虚假(0)”的概率判断。
实验设置与主要成果
4.1 实验基础配置
数据集选择:在三个公开数据集上进行验证,涵盖中英文环境下的虚假新闻样本,具体统计如下:
| 数据集 | 虚假新闻数量 | 真实新闻数量 | 总样本数 | 生成评论数 | 真实评论数 | 总评论数 |
|---|---|---|---|---|---|---|
| Weibo21 | 1922 | 2592 | 4514 | 36112 | 20504 | 56616 |
| 2805 | 3058 | 5863 | 46904 | 34609 | 81513 | |
| GossipCop | 3868 | 4331 | 8199 | 65592 | 61684 | 127276 |
参数设定:
- 数据划分:训练集与测试集按 8:2 划分;中文文本最大长度限制为 200 token,英文为 300 token,单条评论上限为 200 token;
- 模型结构:BERT、Swin-T 和 CLIP 使用默认维度且不微调;SA/CA 层维度设为 d_m=512,注意力头数 n=8;
- 训练配置:Adam 优化器,学习率 5×10,batch size=32,epoch=50;
- 采样策略:生成评论时温度=0.7,核采样=0.9(保证多样性);新闻分析时温度=0.1,核采样=0.8(保障准确性)。
评估指标:Accuracy(准确率)、Precision(精确率)、Recall(召回率)、F1-score、AUC(用于衡量类别不平衡下的区分能力)。
4.2 性能表现:显著优于现有方法
对比最新基线模型:
| 数据集 | 本模型准确率 | 最优基线方法 | 准确率提升 |
|---|---|---|---|
| 95.1% | FSRU(2024) | 5% | |
| Weibo21 | 93.1% | CroMe(2025) | 1.4% |
| GossipCop | 88.3% | AKA-Fake(2024) | 2.7% |
对比大语言模型(零样本与少样本场景):在 Zero-Shot、Zero-Shot CoT、Few-Shot、Few-Shot CoT 四种提示方式下,本模型相较 GPT-3.5-turbo 和 Llama3-8B 等主流 LLM,准确率平均提升 13.2%~16.6%,其中在 Weibo 数据集上最高相对提升达 31.1%。
4.3 消融实验:验证各模块有效性
在 Weibo 数据集上进行消融研究,去除关键组件后性能变化如下:
| 消融项(w/o 表示“去除”) | 准确率 | 较完整模型下降 | 核心结论 |
|---|---|---|---|
| 自我审查(w/o S) | 93.1% | 2% | 有助于初步消除 GLM-4-flash 的生成幻觉 |
| 同行评估(w/o T) | 94.5% | 0.6% | 提供独立视角,增强抗幻觉能力 |
| 综合评测(w/o Z) | 69.8% | 25.3% | 深度学习与跨模态融合是抗幻觉的核心 |
| 动态评论模块(w/o cmts) | 93.4% | 1.7% | 多元评论能提供额外有效信息 |
| SA层(w/o SA) | 85.2% | 9.9% | 自注意力显著提升关键信息捕捉能力 |
实验结果表明,所有模块均对整体性能有实质性贡献,尤其是“综合评测”模块的缺失导致性能大幅下滑,证明了跨模态融合与深度学习架构在虚假新闻检测中的关键作用。
4. 实例分析:生成评论与真实评论的关联性探讨
通过对生成评论与真实用户评论进行多维度对比,揭示两者在语义和表达层面的关系:
| 相似度指标 | 数值 | 结论 |
|---|---|---|
| BERT相似度(语义层面) | 0.837 | 生成评论与真实评论在语义上高度相关,具备弥补真实评论数量或质量不足的潜力 |
| Jaccard相似度(用词层面) | 0.009 | 生成评论词汇使用较为单调、模式化;而真实评论包含颜文字、网络俚语、反讽等表达,语言更自然多样 |
效果验证结果显示:在包含1000条微博样本(其中500条为真实新闻,500条为虚假新闻)的数据集中,采用混合评论(融合真实与生成评论)的方式进行检测时,F1-score达到0.867。相较于仅使用真实评论(0.753)或仅使用生成评论(0.773)的情况,分别提升了15.1%和12.2%,充分证明了多元评论融合策略的有效性。
2. 核心贡献:三项切实可行的领域价值
- 提升虚假新闻检测准确率:有效缓解“单一评论泛化能力差”以及大模型固有的“幻觉”问题,显著增强检测系统的鲁棒性与准确性。
- 提出抗幻觉新范式:构建基于“三重视角”的三级防护机制,不仅服务于当前任务,也为其他依赖大语言模型的任务(如文本摘要、信息抽取)提供可借鉴的去幻觉框架。
- 推进多模态融合方法的发展:通过整合Swin-T、BERT与CLIP的跨模态策略,实现图文联合建模,能够更深入地识别复杂类型的虚假新闻,例如图文内容矛盾的情形。
3. 开源情况说明
论文未公开代码或自建数据集。实验所使用的数据集(Weibo、Weibo21、GossipCop)均为学术界公开资源,可通过相应研究平台合法获取。
关键问题解析:以问答形式梳理核心逻辑
Q1:三重视角如何应对LLM产生的“幻觉”?
A:采用逐层递进的抗幻觉设计:① 自我审查阶段由GLM对生成内容进行初步纠错,消除明显错误;② 同行评估引入DeepSeek模型进行交叉验证,挖掘潜在隐性幻觉;③ 综合评测结合深度学习模型与跨模态信息融合,彻底清除残留幻觉。其中第三步最为关键——若去除该模块,整体准确率将下降25.3%。
Q2:既然生成评论与真实评论语义高度相似(BERT相似度达0.837),为何不能完全取代真实评论?
A:尽管语义接近,但在词汇层面存在显著差异——Jaccard相似度仅为0.009,几乎无重合。生成评论语言风格刻板、表达方式单一,缺乏真实评论中常见的表情符号、口语化表达及讽刺语气,难以捕捉人类真实的互动特征。因此,真实评论提供的多样化表达仍不可替代。
Q3:动态评论模块中的SA层与CA层功能有何区别?
A:SA层(自注意力机制)主要用于内部聚焦,例如从主文本中提取关键事件要素,或在评论集合中识别理性观点;而CA层(交叉注意力机制)则强调外部关联,利用新闻文本作为引导信号,从海量评论中筛选出与事件直接相关的证据,并过滤无关干扰信息。
Q4:本方法最适合应用于哪些实际场景?
A:特别适用于评论丰富且图文并茂的社交媒体环境,如微博、微信公众号发布的资讯,或类似GossipCop这类娱乐新闻平台。这些场景通常具备大量用户互动和完整的多媒体信息,能充分发挥多元评论融合与跨模态分析的优势。
总结与展望
本文针对虚假新闻检测中存在的“评论来源单一导致泛化弱”和“大模型生成幻觉”两大难题,提出了一种融合“多元评论”与“三重视角”的多模态检测框架。通过构建动态评论融合模块,整合真实与AI生成评论,并借助三层递进式机制抑制幻觉影响,同时结合Swin-T、BERT、CLIP实现深层次的跨模态分析。实验结果表明,该方法在三个公开数据集上的表现均显著优于现有技术,为虚假新闻识别提供了兼具“抗幻觉能力”与“多模态理解深度”的创新路径。
然而,研究亦存在一定局限:出于实验稳定性考虑,剔除了涉及政治、暴力等内容的敏感样本,而此类信息恰恰是虚假新闻高发区域。未来若能在保障安全的前提下有效处理敏感内容,将进一步提升该方法的实际应用价值。

 京公网安备 11010802022788号
京公网安备 11010802022788号







