


 雷达卡
雷达卡



基于强化学习框架的交易策略建模与状态-动作体系设计
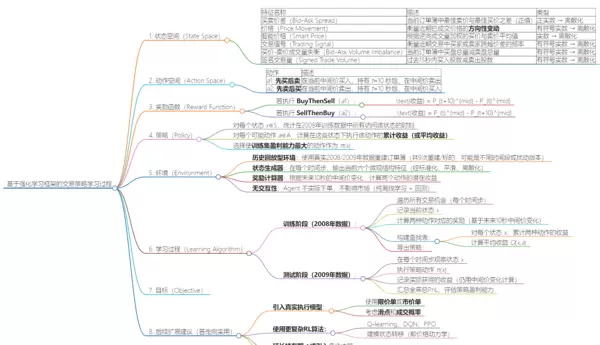
1. 状态空间构建(State Representation)
在本模型中,每个市场状态 s ∈ S 被表示为一个六维特征向量,用以刻画订单簿的微观结构动态及近期交易行为。所有输入特征均经过标准化、滑动时间平均和离散化处理,确保状态空间有限且具备良好的泛化能力。
所采用的六个核心特征如下:
| 特征名称 | 描述 | 数据类型处理方式 |
|---|---|---|
| 买卖价差(Bid-Ask Spread) | 当前最优卖价与最优买价之间的差值,反映市场流动性 | 正实数 → 离散化 |
| 价格变动(Price Movement) | 最近成交价格的趋势性变化方向 | 有符号实数 → 离散化 |
| 智能价格(Smart Price) | 基于成交量逆向加权的买卖报价均值,更贴近真实价值 | 实数 → 离散化 |
| 交易信号(Trading Signal) | 衡量买方或卖方主动跨越价差进行交易的频率 | 有符号实数 → 离散化 |
| 买卖成交量失衡(Bid-Ask Volume Imbalance) | 当前买盘总量减去卖盘总量,体现供需偏移 | 有符号实数 → 离散化 |
| 净交易量(Signed Trade Volume) | 过去15秒内买入股数减去卖出股数,反映短期资金流向 | 有符号实数 → 离散化 |
预处理流程说明:
- 首先对原始特征执行标准化:减去历史均值并除以其标准差;
- 随后在滑动时间窗口内进行平均,降低噪声影响;
- 最后将连续值映射至有限区间(如按 ±0.5σ, ±1σ, ±2σ 分段),完成离散化。
最终形成一个有限维度的离散状态集合 S,其中每个状态 x 表示为一个六元组,即由六个离散化后的特征构成的状态向量。
2. 动作空间定义(Action Set)
智能体在每一个观测到的状态下可选择以下两种理想化交易操作之一:
| 动作 | 操作描述 |
|---|---|
| a: 先买后卖(BuyThenSell) | 在当前中间价买入资产,持有10秒后在同一中间价卖出 |
| a: 先卖后买(SellThenBuy) | 在当前中间价卖出资产(做空),10秒后在同一价格买入平仓 |
该设定基于理想化执行假设:忽略滑点、市场冲击、订单未完全成交等现实摩擦因素,仅用于评估策略的方向预测能力。
因此,动作空间 A 为一个二元有限集:
A = {BuyThenSell, SellThenBuy}
3. 奖励机制设计(Reward Function)
奖励信号来源于执行某一动作后,在接下来10秒内由中间价变动带来的虚拟盈亏(PnL),计算基于理想化的无摩擦交易环境。
具体收益公式如下:
- 若执行 BuyThenSell(a):
收益 = Pt+10mid - Ptmid
- 若执行 SellThenBuy(a):
收益 = Ptmid - Pt+10mid
由此可见,奖励本质上是价格变动方向与所选动作方向的一致性度量:
- 当价格上涨时,BuyThenSell 获利,SellThenBuy 亏损;
- 当价格下跌时,SellThenBuy 获利,BuyThenSell 亏损;
- 若价格不变,则两个动作收益均为零。
综合表达式如下:
R(s, a) =
-ΔP, if a = SellThenBuy
其中 ΔP = Pt+10mid - Ptmid,表示10秒内的中间价变化量。
由于在理想执行条件下总存在至少一个非负收益动作(除非ΔP=0),该奖励函数能够有效引导策略学习价格趋势判断能力。
4. 策略学习方法(Policy Learning Mechanism)
策略 π 定义为从状态空间到动作空间的映射函数:
π: S → A
本研究采用确定性策略(deterministic policy),通过分析历史训练数据中的状态-动作回报统计结果来构建最优决策规则。
具体构建过程如下:
- 对于每一个离散状态 x ∈ S,收集2008年训练集中所有出现该状态的时间点;
- 针对每个可能的动作 a ∈ A,计算在这些时刻执行该动作后的平均或累计奖励;
- 选取在该状态下带来最高历史平均收益的动作作为最优响应,即:
π(x) = arg maxa∈A [Rt | St = x, At = a] (基于训练样本的经验期望估计)
这一方法属于无模型(model-free)的贪婪策略学习,其本质等价于对经验Q值的最大化选择:
π(x) = arg maxa Qtrain(x, a)
其中 Qtrain(x, a) 表示在训练数据中,从状态 x 执行动作 a 所获得的平均回报值。
该策略充分利用历史数据中的条件期望信息,旨在发现具有稳定盈利能力的状态-动作组合模式。
其中:
\( Q_{\text{train}}(x, a) \) 表示在训练数据集中,从状态 \( x \) 执行动作 \( a \) 所获得的平均收益。
5. 环境(Environment)
定义:环境为一个高频订单簿市场模拟器,基于历史数据重建订单簿并模拟市场价格演化过程。
核心特性包括:
- 历史回放机制: 利用2008至2009年的真实市场数据对订单簿进行重建,共完成9次重建,可能对应不同时间段或加入扰动以增强鲁棒性。
- 状态生成模块: 每个时间步输出当前的六个微观结构特征,这些特征经过标准化、平滑处理及离散化操作。
- 奖励计算机制: 基于未来10秒内的中间价变动,评估两种动作所能带来的潜在收益。
- 非交互性设计: 智能体不实际提交订单,无法影响市场状态,整个学习过程属于纯离线模式,仅用于回测分析。
该设置本质上属于离线强化学习(Offline RL)框架:
- 训练所用数据预先采集自2008年的市场记录;
- 学习得到的策略将在独立的测试集(2009年数据)上进行性能验证。
6. 学习流程(Learning Algorithm)
尽管未采用Q-learning、DQN等复杂算法,其逻辑可视为批量强化学习中的简化策略学习方法。
训练阶段(使用2008年数据):
- 遍历所有可用交易时机(即每个时间步);
- 记录当前状态 \( x \);
- 根据未来10秒内中间价的变化,分别计算执行两个动作所带来的即时奖励;
- 构建状态-动作收益累计表:对每一个状态 \( x \),统计两种动作的历史收益总和;
- 计算平均收益函数 \( Q(x, a) \);
- 导出最优策略: \( \pi(x) = \arg\max_a Q(x, a) \)
此方法可被看作是Fitted Q-Iteration 的极简版本,或一种基于均值估计的直接策略搜索方法。
测试阶段(使用2009年数据):
- 在每个时间步观测当前状态 \( x \);
- 依据已学习策略选择动作 \( \pi(x) \);
- 记录该动作下实际实现的收益(仍以未来10秒中间价变化为准);
- 汇总全年所有交易的盈亏(PnL),用于评估策略盈利能力。
7. 优化目标(Objective)
虽然文中未显式构造价值函数,但整体优化目标为最大化期望累计收益,即:
期望累计收益 = 平均单笔收益 × 交易频率
由于每笔交易周期较短(t=10秒),持仓时间短暂,且未建模状态之间的转移关系,该方法隐含假设:
- 各状态之间无长期依赖;
- 决策仅依赖当前上下文信息,关注即时回报。
因此,该框架更贴近上下文赌博机(Contextual Bandit)模型,而非完整的马尔可夫决策过程(MDP)强化学习体系。
8. 可行性扩展方向(迈向实际应用)
- 引入真实交易执行模型: 支持限价单与市价单类型,考虑滑点及成交概率的影响。
- 采用更先进的强化学习算法: 如Q-learning、DQN、PPO等,提升策略表达能力。
- 建模价格动态演化过程: 显式刻画状态转移机制,捕捉市场趋势与波动特征。
- 延长持有周期或支持多步决策: 允许更复杂的交易行为,如分批建仓或动态止盈止损。
- 在奖励函数中加入交易成本惩罚项:
定义实际收益为:
\( R_{\text{real}}(s,a) = \text{Directional PnL} - \text{Transaction Cost} - \text{Market Impact} \)
通过上述改进,系统可逐步从理论研究过渡到具备实战价值的自动化交易架构。

 京公网安备 11010802022788号
京公网安备 11010802022788号







