


 雷达卡
雷达卡



1. 查询构建
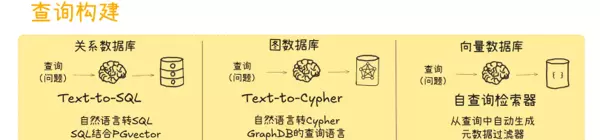
1.1 NL2SQL 技术演进路径
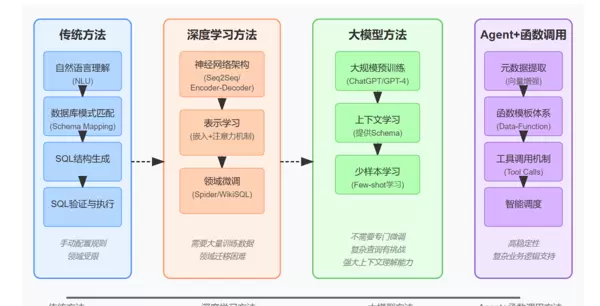 该内容系统梳理了“自然语言转数据库操作(NL2DB)”从传统方法到前沿 Agent 方案的四代技术发展脉络,涵盖各阶段的技术架构、核心机制与典型特征,清晰展现其迭代逻辑。
该内容系统梳理了“自然语言转数据库操作(NL2DB)”从传统方法到前沿 Agent 方案的四代技术发展脉络,涵盖各阶段的技术架构、核心机制与典型特征,清晰展现其迭代逻辑。
第一代:传统规则驱动方法
架构流程:自然语言理解(NLU)→数据库模式匹配(Schema Mapping)→SQL结构生成→SQL验证与执行ORDER BY ... DESC 操作。
主要特点:实现简单、成本低,但适用范围狭窄,具有明显的**领域局限性**——一旦更换数据库结构或业务场景,需重新编写大量规则。
第二代:深度学习模型驱动方法
架构流程:神经网络架构(Seq2Seq/Encoder-Decoder)→表示学习(嵌入+注意力)→领域微调(用Spider/WikiSQL数据集)第三代:大模型少样本生成方法
架构流程:大规模预训练(ChatGPT/GPT-4)→上下文学习(给数据库Schema)→少样本学习(给少量示例)第四代:Agent + 函数调用智能协作方法
架构流程:元数据提取(向量增强)→函数模板体系→工具调用机制→智能调度1.2 NL2SQL 核心处理流程
 此部分详细描述了一个完整的 NL2SQL 系统如何将用户输入的自然语言问题转化为可执行的 SQL 查询,并返回结构化结果。整个流程遵循“知识准备→上下文检索→SQL生成→执行反馈”的闭环逻辑。
此部分详细描述了一个完整的 NL2SQL 系统如何将用户输入的自然语言问题转化为可执行的 SQL 查询,并返回结构化结果。整个流程遵循“知识准备→上下文检索→SQL生成→执行反馈”的闭环逻辑。
步骤一:Schema 提取与切片 —— 构建 DDL 知识库
操作说明:从数据库的 DDL 语句(如 CREATE TABLE 等建表语句)中提取出完整的 Schema 信息,包括表名、字段名、字段类型、主外键关系等,并根据语义或结构进行合理切分(如按表拆分、按功能归类)。 目的意义:建立数据库的“结构化知识底座”,帮助系统准确理解数据组织方式,是后续生成正确 SQL 的前提条件。例如明确知道“订单表”包含“订单金额”字段及其数据类型。 关联说明:DDL 是定义数据库物理结构的语言,本步骤正是将其转化为机器可读、可推理的知识表示形式。 对应图示:CREATE TABLE步骤二:示例对注入 —— 构建 Q→SQL 映射知识库
操作说明:收集并存储一系列“自然语言问句(Question)→ 对应 SQL 语句”的配对样本,如:“查2025年11月的订单金额” → 相关 SELECT 查询语句。这些样本被统一管理于知识库中。 目的意义:为系统提供可供参考的历史案例,在面对相似问题时能借鉴已有模式,尤其支撑大模型的少样本学习(Few-shot Learning)能力。 对应图示:SELECT SUM(amount) FROM orders WHERE month='2025-11'步骤三:业务描述补充 —— 构建 DB 业务语义知识库
操作说明:添加关于数据库字段的业务含义注释,例如说明“订单表中的 status 字段,1 表示‘已支付’,2 表示‘已取消’”。将技术化的字段编码转化为人类可理解的业务语言。 目的意义:消除 Schema 中存在的语义模糊问题,防止模型误解字段含义而导致错误查询(如误将 status=1 解读为“未支付”)。 对应图示:status步骤四:检索增强生成(RAG)—— 动态获取上下文
操作说明:当接收到用户的自然语言提问后,系统首先启动检索机制,从上述三个知识库(DDL/Schema、Q→SQL 示例、业务描述)中查找与当前问题相关的上下文信息。例如,若问题提及“订单金额”,则检索相关表结构、历史查询范例及金额计算规则。 目的意义:通过引入外部知识增强提示词内容,提升大模型的理解准确性,有效减少“幻觉”现象,确保生成的 SQL 符合实际数据库结构与业务逻辑。步骤五:SQL 生成 —— 调用大语言模型
操作说明:将用户原始问题与检索得到的上下文拼接成完整的提示词(Prompt),输入至大语言模型(如 GPT-4、Llama 等),由模型输出对应的 SQL 语句。 关键要点:模型基于丰富的上下文信息综合判断意图,结合 Schema 结构、历史示例和业务规则,生成语法合规、语义正确的 SQL 查询。步骤六:执行与反馈 —— 完成查询并返回结果
操作说明:将生成的 SQL 发送给数据库执行,获取原始查询结果;随后将数值型或表格型结果转换为易于理解的自然语言表述(如“2025年11月订单总金额为XXX元”)反馈给用户。 可选优化:若 SQL 执行失败(如语法错误、字段不存在),系统可捕获错误信息并触发修正机制,如重新检索上下文或再次调用 LLM 进行优化重试。 整个流程体现了“**先沉淀知识、再按需检索、最后智能生成**”的设计思想,借助“知识库 + RAG”机制弥补大模型在专有数据库知识上的盲区,保障最终输出既符合语法规范,又契合实际业务需求,实现端到端的自然语言到数据库结果的自动化转换。1.3 TextToSql 实现方案
1.3.1 Vanna 框架简介
Vanna 是一个专注于实现 Text-to-SQL 转换的开源框架,支持基于大语言模型和向量数据库的混合架构,能够通过训练和检索机制提升自然语言到 SQL 的转换精度。它整合了 Schema 管理、示例存储、语义检索与模型调用等功能模块,适用于企业级 NL2DB 场景的快速搭建与部署。Vanna 是一个遵循 MIT 许可证的开源 Python 框架,专为实现自然语言到 SQL 的转换而设计,属于典型的 RAG(检索增强生成)架构。其主要作用是将用户的日常语言自动转化为可执行的 SQL 查询语句,从而显著降低数据库操作的技术门槛。借助该工具,产品经理、运营人员等非技术背景的用户无需掌握复杂的 SQL 语法,也能轻松完成数据查询并获取所需结果。
1.3.2 Chat2DB
Chat2DB 是一款融合 AI 能力的通用智能 SQL 客户端与数据分析报告工具。它支持多数据库连接,能够帮助用户更高效地编写 SQL 语句、管理数据库结构、探索数据内容,并自动生成可视化报告,提升整体数据交互效率。
1.3.3 DB-GPT
DB-GPT 是一个专注于数据库交互的 AI 框架,具备强大的自然语言理解能力,可用于数据库查询优化和语义解析。相关资源可通过以下链接访问:
- GitHub 项目地址:https://github.com/eosphoros-ai/DB-GPT
- 官方文档地址:https://www.yuque.com/eosphoros/dbgpt-docs
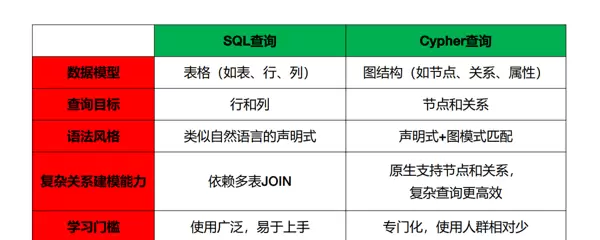
1.4 TextToCypher
在处理用户输入的自然语言请求前,系统需预先构建图数据库的“元知识”库,类似于 TextToSQL 中的 Schema 描述体系。该知识库存储了图结构的核心定义信息,主要包括:
- 节点信息:描述图中存在的节点类型(如 Person、Movie)及其属性字段(例如 Person 包含 name、age 等属性);
- 关系信息:定义节点之间的关联类型(如 Person 与 Person 之间存在 FRIEND 关系,Person 与 Movie 之间存在 ACTED_IN 关系),以及这些关系所携带的属性(如 FRIEND 可能包含 since 字段表示建立时间)。
1.5 Self-query Retriever
Self-query Retriever(自查询检索器)是一种用于 RAG 应用场景中的智能化检索组件,常见于 LangChain 等框架中。它利用大语言模型(LLM)对用户输入的自然语言进行深度解析,从中提取出两部分内容:一是用于语义匹配的核心查询意图,二是潜在的元数据过滤条件(如时间范围、类别标签、评分阈值等)。随后结合向量数据库的语义检索能力,实现高精度的内容召回。
整个流程高度自动化,依赖 LLM 的理解能力和向量数据库的存储机制,具体步骤如下:
- 解析与信息提取:LLM 对原始查询进行分析,识别关键语义内容及隐含的筛选条件。例如,“第三讲里关于回归分析的内容”会被解析为关键词“回归分析”和元数据条件“讲次 = 第三讲”。
- 结构化查询生成:将提取到的信息分别处理——核心语义转为向量检索的查询字符串,元数据条件则转换成数据库可识别的过滤表达式,如将“评分高于 8 分的科幻电影”转化为 “genre = 科幻 AND rating>8”。
- 联合检索与结果返回:系统将语义向量查询与结构化过滤条件一并提交至向量数据库。数据库首先依据过滤规则缩小候选集范围,再在限定范围内执行语义相似性匹配,最终返回精准且相关的结果。
2. 查询翻译
查询翻译是指通过提示工程(Prompt Engineering)手段,对用户输入的问题进行语义重构与优化。当原始查询存在表述模糊、含有噪声、信息不完整或未能全面覆盖目标检索维度时,需要采用重写、分解、澄清和扩展等多种策略对其进行改进,以提升后续检索阶段的准确率与覆盖率。

2.1 查询重写——重构原始问题为更适配的形式
作为 RAG、TextToSQL 和 TextToCypher 等任务中的关键环节,查询重写旨在解决原始问题中存在的模糊性、歧义、信息缺失或表达不精确等问题。通过设计合理的 Prompt 指令引导大语言模型(LLM)对原始查询进行优化,使其更符合下游检索或代码生成模块的需求,从而提高整体系统的输出质量。例如,将“最近卖得好的产品”重写为“过去30天内销量排名前10的商品”,使语义更加明确。

2.2 查询分解——拆解复杂查询为多个子问题
面对多意图、跨领域或逻辑链条较长的复杂查询,直接处理容易导致信息遗漏或生成错误结果。查询分解技术借助大模型的能力,将这类复合型问题拆分为若干个独立、清晰且可执行的子问题,分别处理后再整合答案。
典型应用场景包括:
- 多意图分离:如“查 2025 年 Q3 手机和电脑的销量及同比增速”可被拆解为四个子任务:“查 2025 年 Q3 手机销量”、“查 2025 年 Q3 手机同比增速”、“查 2025 年 Q3 电脑销量”、“查 2025 年 Q3 电脑同比增速”;
- 长逻辑链拆解:如“查小明的朋友中参与过科幻电影的人的年龄”可分步为:“找出小明的朋友” → “筛选其中参演过科幻电影者” → “获取这些人的年龄”;
- 跨数据源适配:如“查某产品的线上销售额和线下门店数量”可拆为:“从电商数据库获取线上销售额” + “从门店管理系统获取线下门店总数”;
- 降低执行复杂度:每个子问题更简单明确,有利于提升 SQL 或 Cypher 语句生成的准确性与稳定性。
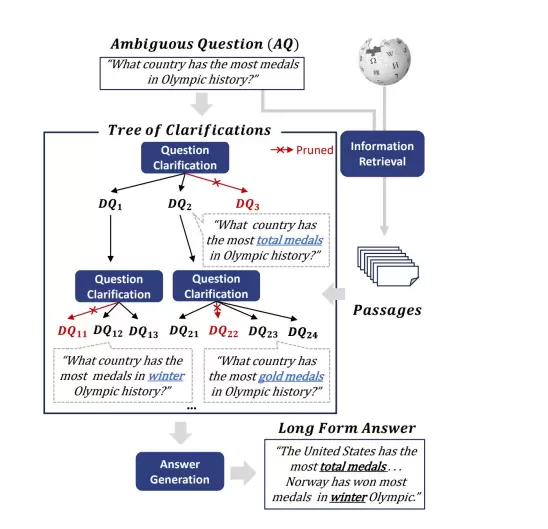
2.3 查询澄清——逐步细化并明确用户意图
该方法通过递归方式构建“问题澄清树”,不断追问和补充上下文,逐步厘清用户的真实需求。尤其适用于初始提问过于宽泛或信息不足的情况,通过多轮交互动态完善查询条件,确保最终生成的查询语句能准确反映用户期望。
查询澄清是处理模糊、歧义或信息不完整查询的关键流程,广泛应用于 RAG、TextToSQL 等场景。该过程通过大模型(LLM)主动向用户发起追问,逐步补全缺失信息、消除语义歧义,最终将“不明确的自然语言查询”转化为“可执行的精准指令”。
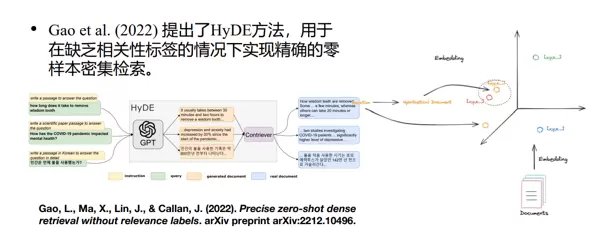
2.4 查询扩展——基于HyDE生成假设文档
Gao et al. (2022) 提出的 HyDE 方法,旨在在缺乏相关性标注数据的情况下,实现高精度的零样本密集检索。该方法通过生成“假设性回答文档”来增强查询表示,从而提升后续检索阶段的相关性匹配能力。
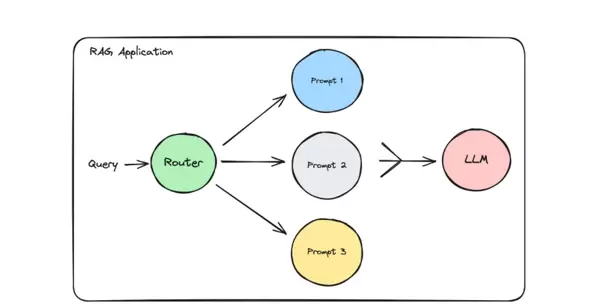
3. 查询路由
作为 RAG、TextToSQL/TextToCypher 等复杂系统的调度核心,查询路由根据用户输入的内容特征、意图和业务背景,智能地将其分发至最合适的处理单元,例如不同的知识库、检索器、数据源或生成模块。通过“分类分发、各司其职”的策略,避免统一处理带来的效率低下与结果偏差,显著提升系统响应速度与准确性。
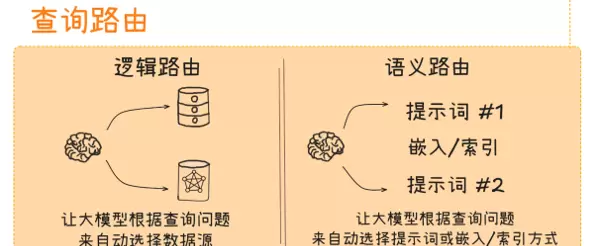
3.1 逻辑路由(Logical Routing)
3.1.1 核心定义
逻辑路由是一种基于预设明确规则进行查询分发的“硬性导航”机制。它依赖关键词匹配、条件判断(如 if-else 结构)等确定性逻辑,将查询定向到指定处理模块。这些规则由工程师结合业务需求、数据分布及各模块功能手动构建,具备强可解释性和高确定性。
3.1.2 规则设计主要维度
规则制定聚焦于查询中“可量化的表面特征”,无需深入理解语义内容,常见维度包括:
- 关键词匹配:如包含“销量”“销售额”则路由至电商数据库;出现“病历”“症状”则导向医疗知识库;
- 查询意图类型:事实型查询使用向量检索,统计类交由 SQL 生成器,闲聊对话转接通用 LLM;
- 业务领域归属:员工考勤类问题接入人力资源系统,财务报销相关送入财务数据库,产品咨询对接产品知识库;
- 数据类型关联:涉及图片调用多模态检索器,纯文本走文本知识库,实时数据请求触发 API 接口;
- 复杂度等级:单条件简单查询由基础检索器处理,多条件复合查询分配给复杂 SQL 生成模块。
3.1.3 工作流程
- 规则库定义:工程师建立结构化规则集,例如“若查询含‘销量’且有时段描述 → 路由至电商 SQL 模块”;
- 特征提取:系统自动识别查询中的关键词、意图类别、所属业务属性等显性特征;
- 规则匹配校验:将提取特征与规则库逐条比对,筛选唯一匹配项或优先级最高的规则;
- 路由分发执行:将查询发送至规则指定的目标处理单元;
- 兜底逻辑处理:当无任何规则匹配时,统一转发至默认模块(如通用 LLM 或人工客服)。
3.1.4 典型应用示例(电商平台)
| 规则ID | 匹配条件 | 路由目标 |
|---|---|---|
| R1 | 包含“销量”“销售额”“订单数”,并含有时间范围(如“2025年Q3”“近30天”) | 电商SQL生成器(对接订单库) |
| R2 | 包含“产品名称”“型号”“功能”,无统计类需求 | 产品知识库向量检索器 |
| R3 | 包含“售后”“退款”“保修” | 售后工单系统检索器 |
| R4 | 以上均未匹配 | 通用LLM对话模块 |
路由实例:
- 用户查询:“2025年Q3手机品类的销售额” → 特征提取(含“销售额”+时间范围)→ 匹配R1 → 分发至电商SQL生成器;
- 用户查询:“iPhone 16的摄像头功能” → 特征提取(含“产品名称”“功能”)→ 匹配R2 → 路由至产品知识库向量检索器。
3.1.5 优势与局限
| 优势 | 局限 |
|---|---|
| 响应速度快,通常可在毫秒级完成规则匹配 | 规则维护成本高,业务变化需频繁调整规则库 |
| 可解释性强,每一步路由均有清晰依据 | 难以应对模糊或未定义场景,无匹配即失效 |
| 无需调用LLM,运行成本低 | 多个规则冲突时,优先级管理复杂 |
| 准确性高,规则明确减少主观误差 | 仅依赖表层特征,无法理解深层语义,易误判 |
3.1.6 适用场景
- 适用于业务模式稳定、查询模式固定的系统,如企业OA、标准化电商平台;
- 适合对响应延迟敏感、预算有限的部署环境,无需引入额外模型推理开销;
- 适用于规则数量适中、易于管理和迭代的中小型系统架构。
3.2 语义路由(Semantic Routing)
3.2.1 核心定义
语义路由是一种基于查询深层语义意图的“柔性导航”方式,利用大语言模型(LLM)或嵌入模型(Embedding Model)理解用户提问的本质含义,而非仅仅匹配关键词字符串。其核心理念是“理解意图而非字符匹配”,特别适用于复杂、模糊或多意图交织的查询分发任务。
3.2.2 技术原理
语义路由依赖两大核心技术:“语义意图识别”与“向量相似度计算”。主要实现路径包括:
- LLM驱动意图分类:借助大模型将输入查询归类到预设意图类别(如“电商统计”“医疗咨询”),每个类别对应一个固定处理模块;
- 嵌入驱动相似度匹配:
- 模块语义建模:为每个处理单元撰写语义描述(如“订单统计模块:负责销量、销售额分析”),并生成对应的嵌入向量存入向量库;
- 查询编码:将用户查询转换为语义向量;
- 相似度计算:采用余弦相似度等算法,衡量查询向量与各模块描述向量之间的关联程度,选择最接近的模块进行路由;
- 混合驱动模式:结合LLM初步分类与嵌入向量微调,形成两级路由机制,进一步提升匹配精度。
3.2.3 工作流程(以嵌入驱动为例)
- 模块语义建模:为各个目标处理模块编写准确的语义描述,并生成对应的嵌入向量,存储于向量数据库中;
- 查询语义编码:将用户的自然语言查询编码为语义向量;
相似度计算:通过生成查询向量,并与各模块对应的向量进行比对,计算其语义相似程度;
路由决策:依据相似度结果,选取最高得分或超过预设阈值的模块作为目标处理单元;
兜底处理:当所有模块的相似度均未达到设定阈值时,请求转入默认模块,或启动问题澄清流程以获取更明确的用户意图。
3.2.4 典型示例(跨领域智能问答系统)
系统模块及语义描述
| 模块名称 | 语义描述(用于生成嵌入向量) |
|---|---|
| 医疗知识库 | 涵盖疾病症状、治疗建议、药物使用说明和健康科普等内容,适用于患者咨询与医学知识普及场景。 |
| 金融数据分析模块 | 支持股票、基金、理财产品等金融产品的收益查询、数据解读与风险分析,连接专业金融数据库及外部API接口。 |
| 生活服务模块 | 提供出行规划、旅游推荐、餐饮信息、购物指南等日常生活相关服务,支持查询、推荐与预约功能。 |
| 通用闲聊模块 | 应对无具体业务指向的对话内容,如情绪交流、话题探讨、趣味互动等非任务型会话场景。 |
路由过程
用户输入:“2025年Q3哪些基金收益率较高” → 系统将其转化为查询嵌入向量;
相似度对比结果显示:与“金融数据分析模块”的语义匹配度为0.92,显著高于其他模块(医疗:0.15,生活:0.23,闲聊:0.08);
基于该结果,系统将请求路由至金融数据分析模块,并调用后端数据库返回相应的收益分析数据。
模糊查询处理
用户提问:“苹果的相关数据”——若仅依赖关键词匹配,易产生歧义(可能指科技品牌或水果);
采用语义路由机制,结合历史上下文判断倾向:此前讨论“手机销量”则导向电商模块;若前文涉及“水果价格”,则进入生活服务模块;
在缺乏上下文线索的情况下,系统将发起澄清询问:“你指的是苹果公司产品还是水果苹果?”以确认真实意图。
3.2.5 优势与局限
| 优势 | 局限 |
|---|---|
| 能够理解深层次语义,有效应对模糊或多层意图的复杂查询 | 依赖大语言模型或嵌入模型,带来额外成本(如API调用、计算资源消耗) |
| 维护简便,新增或调整模块只需更新其语义描述文本 | 响应速度低于规则驱动的逻辑路由方式,因需执行向量编码与相似度运算 |
| 支持多意图识别与跨领域问题处理,扩展性强 | 可解释性较差,难以直观展示为何选择某一特定模块 |
| 适应业务快速迭代,新增功能模块仅需补充对应语义定义 | 路由准确性高度依赖模块语义描述的质量,描述不当可能导致误分发 |
3.2.6 适用场景
- 适用于用户查询表达模糊、意图不清晰的系统,例如智能助手、综合性问答平台;
- 适合模块数量多、业务频繁更新的大规模系统,如企业级知识中枢或服务平台;
- 在关键词匹配容易出错的场景中表现更优,尤其针对多义词、结构歧义句等复杂语言现象。

 京公网安备 11010802022788号
京公网安备 11010802022788号







