


 雷达卡
雷达卡



深度学习与大模型的关系解析
大模型并非取代了深度学习,而是建立在其基础之上的进一步发展。二者之间并非并列或替代关系,而是一种“子集与父集、进阶与基础”的层级结构。简而言之,大模型是深度学习在海量数据和复杂网络架构条件下的极致演化形态,而深度学习则是支撑大模型运行的核心技术底座。
深度学习(Deep Learning, DL)
作为人工智能的重要分支,深度学习的核心理念在于利用多层神经网络自动提取数据特征,无需依赖人工设计特征工程。相较于传统机器学习方法,它实现了从“手动规则”向“端到端学习”的跨越。其应用范围广泛,涵盖多种经典神经网络结构,如用于图像处理的CNN、处理序列数据的RNN,以及当前主流的通用架构Transformer等。
大模型(Large Language Model / Foundation Model)
可视为深度学习的“超级升级版本”,特指那些具备亿级以上参数规模、基于大规模无标注数据进行预训练,并能灵活适配多种下游任务的模型。典型代表包括自然语言领域的GPT、BERT,计算机视觉中的SAM、ViT,以及支持图文交互的多模态模型如GPT-4V等。
传统模型(Traditional Machine Learning)
指的是在深度学习兴起之前主流的机器学习算法体系,其核心流程为人工提取特征 + 简单模型映射输出。常见的算法包括线性回归、决策树、SVM、随机森林等。这类方法对领域知识依赖较强,泛化能力有限。
三者之间的包含关系清晰明确:
传统模型 ? 机器学习 ? 深度学习 ? 大模型
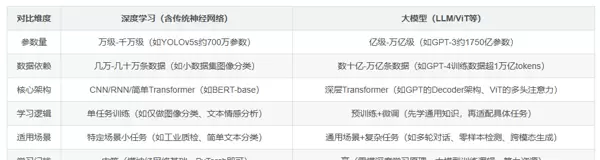
尽管常有人将“大模型”等同于“深度学习”,但实际上它们在技术边界、应用场景及学习门槛上存在显著差异。以下为关键对比:
大模型 ≠ 深度学习,深度学习 ≠ 大模型
大模型并未脱离深度学习的基本原理,而是在此基础上实现了规模扩张与范式革新,具体体现如下:
继承的技术内核
- 特征自动学习:延续深度学习“端到端”训练的优势,摆脱对手工特征的设计依赖。例如LLM能够自动捕捉文本语义,ViT可自主提取图像高层特征。
- 神经网络架构基础:本质上仍是多层神经元连接系统,依赖反向传播、梯度下降、激活函数等深度学习核心技术实现训练过程。
- 损失函数机制:沿用交叉熵、均方误差(MSE)等基本损失函数框架,仅根据具体任务做适应性调整,如LLM采用自回归语言建模损失。
实现的关键突破
- 架构规模化:通过加深加宽Transformer等基础结构,使参数量级从千万跃升至百亿甚至万亿级别。
- 数据规模化:训练数据由传统的十万级标注样本扩展为万亿级无监督文本或图像数据,借助预训练获取通用表征能力。
- 任务泛化能力提升:从单一任务专用模型进化为支持零样本(zero-shot)和少样本(few-shot)推理的通用模型,例如直接使用GPT-4完成翻译、摘要生成等任务而无需额外训练。
常用深度学习框架概述
深度学习框架是一类用于简化模型开发流程的软件工具,极大降低了进入该领域的技术门槛。用户无需从底层编写复杂的神经网络代码,即可调用已有组件构建、训练并部署模型。这些框架提供了一系列API与优化工具,支持在不同硬件平台上高效运行。
典型的深度学习框架通常包含以下几个核心模块:
- 前端API:用于定义网络结构、配置层类型、激活函数、优化器等参数。
- 计算引擎:负责执行前向传播与反向传播运算,完成梯度计算与权重更新。
- 数据管理与预处理:支持数据加载、清洗、增强、批量化处理等功能,提升训练效率与模型鲁棒性。
- 硬件加速与分布式计算:可在GPU集群或多节点系统中实现并行训练,显著缩短训练周期。
主要功能特性
- 神经网络定义与配置:通过高级接口快速搭建复杂模型结构。
- 模型训练与优化:集成自动微分与优化算法,支持SGD、Adam等多种优化策略。
- 数据处理支持:内置丰富的数据管道工具,适用于大规模数据集的读取与变换。
- 大数据训练能力:能够在TB级数据上进行有效训练,增强模型精度与泛化性能。
- 硬件兼容性:支持CPU、GPU乃至TPU等多种计算设备,部分框架还支持移动端部署(如iOS、Android)。
- 模型部署与推理:提供模型导出、序列化与推理接口,便于在生产环境中落地应用。
主流开源框架简介
目前市面上涌现了众多开源深度学习框架,各具特色,适用场景各异。常见框架包括:PyTorch、TensorFlow、Caffe、Keras、MXNet、CNTK、Theano、Torch7、DeepLearning4J、Lasagne、Neon、Leaf 等。关于“哪个更好”的问题,并无统一评判标准,往往取决于项目需求、团队习惯与硬件环境。
TensorFlow
由Google Brain团队研发的开源深度学习平台,底层以C++实现,具备高度可扩展性。支持多种编程语言接口,如Python、JavaScript、Java、Go、C++、C#、Julia和R等。同时兼容多种硬件平台,包括CPU、GPU和Google自研的TPU芯片。此外,TensorFlow Lite版本可在移动设备(如Android和iOS)上部署轻量化模型,满足边缘计算需求。
由加州大学伯克利分校(BVLC)开发的开源深度学习框架Caffe,专注于图像分类与目标检测等视觉任务。其全称为Convolutional Architecture for Fast Feature Embedding,具有高效、清晰且易于使用的特性,在卷积神经网络方面表现尤为出色。该框架以C++为核心语言,同时结合CUDA和Python实现高性能计算,支持命令行、Python以及MATLAB接口,能够在CPU和GPU之间灵活切换,并具备多GPU训练能力。
Caffe的主要特点包括:
- 主要采用C++/CUDA/Python编写,运行速度快,性能优越;
- 采用工厂设计模式,代码结构清晰,可读性强,便于扩展;
- 提供多种接口,使用灵活便捷;
- 支持CPU与GPU间的无缝切换,适合多GPU环境下的并行训练;
- 配套工具丰富,拥有活跃的技术社区。
然而,Caffe也存在一些明显的局限性:
- 修改源码门槛较高,需手动实现前向与反向传播逻辑;
- 缺乏自动求导功能;
- 仅支持数据级并行,不支持模型级并行;
- 对非图像相关任务的支持较弱。
MXNet是由李沐等人主导开发、后由亚马逊重点支持的开源深度学习框架,具备良好的可扩展性和高效的资源利用能力。它支持多种编程语言(如Python、C++、R、Matlab、Scala、JavaScript等),可在多种硬件平台上运行,包括CPU、GPU、移动设备、服务器集群等。MXNet在分布式训练方面表现出色,尤其在内存和显存优化方面优势明显,适合大规模模型部署。
尽管MXNet功能强大,但其文档和教程体系相对不够完善,初学者上手可能有一定难度。
[此处为图片2]PyTorch是一个由Facebook AI Research团队开发的开源深度学习平台,其前身是Torch,但完全使用Python重构,支持动态图与静态图两种计算模式,兼具灵活性与高效性。PyTorch的核心功能主要包括:
- 支持GPU加速的张量运算;
- 集成自动微分机制,便于模型优化。
PyTorch的优势体现在以下几个方面:
- 简洁易懂:API设计统一,层级分明,主要分为tensor、autograd和nn三个层次,学习曲线平缓;
- 易于调试:由于采用动态计算图机制,用户可以像调试普通Python程序一样逐行排查问题,错误提示信息清晰明了;
- 功能强大且高效:内置丰富的模块组件,能够快速验证和实现新想法;
- 多语言支持:兼容C/C++与Python,便于底层扩展与集成。
Theano是一个早期的Python数值计算库,常被视为现代深度学习框架的先驱之一。它允许用户定义、优化并评估涉及多维数组的数学表达式,特别适用于复杂的神经网络构建。虽然Theano已不再积极维护,但它对后续框架(如Keras)的发展产生了深远影响。
TensorFlow则采用静态计算图机制进行操作。这意味着用户必须先完整定义整个计算图结构,再启动实际运算过程。若需调整网络架构,则往往需要重新构建图形甚至重新训练模型。这种设计虽牺牲了一定灵活性,却提升了运行效率。相比之下,许多现代框架已在训练过程中实现了动态调整能力,而不会显著影响性能。因此,TensorFlow在这一方面的主要竞争者正是PyTorch。
[此处为图片4]Keras是由Fran?ois Chollet开发的高级神经网络API,完全基于Python编写,支持TensorFlow、Theano和CNTK作为后端引擎。严格来说,Keras本身并非独立的深度学习框架,而是建立在其他框架之上的高层接口。它的最大特点是简单易用,非常适合入门者快速搭建模型,开发效率高。
尽管Keras在常见应用场景中表现出色,但其灵活性受限,难以满足复杂定制化需求,运行效率也不及底层框架直接操作。RStudio为R语言用户提供了与Keras和TensorFlow交互的API接口,并在其官网及GitHub页面发布相关学习资源。
相关链接如下:
https://tensorflow.rstudio.com/keras/
https://github.com/rstudio/keras
https://tensorflow.rstudio.com/tensorflow/
https://github.com/rstudio/tensorflow
各框架的GitHub源码地址:
https://github.com/pytorch/pytorch
https://github.com/BVLC/caffe
https://github.com/keras-team/keras
https://github.com/apache/incubator-mxnet
https://github.com/tensorflow/tensorflow
Theano 起源于蒙特利尔大学的 LISA 实验室,自2008年起开始研发,是首个在Python深度学习领域产生广泛影响的框架。其设计核心为一个数学表达式编译器,能够将用户定义的运算结构转化为可在CPU或GPU上高效执行的代码。
该框架具备良好的可移植性与计算效率,支持自动求导以及GPU加速,专为深度学习中复杂的大型神经网络计算任务而设计。然而,目前项目已不再进行维护。
PaddlePaddle 是由百度自主研发并开源的深度学习平台,作为国内最早发布且功能完整的深度学习框架之一,它提供了最全面的工业级模型支持,覆盖多个应用场景。平台具备强大的多端部署能力,并支持稠密与稀疏参数场景下的超大规模深度学习并行训练。
支持的主要编程语言包括:C++ 和 Python。
Deeplearning4j(简称 DL4J)是一个面向Java及其JVM生态的语言所构建的开源深度学习框架,适用于Java、Scala等语言环境。它支持多种主流神经网络结构,如受限玻尔兹曼机、卷积神经网络(CNN)和循环神经网络(RNN),并通过ND4J库实现对CUDA内核的调用,从而利用GPU提升计算性能。
此外,DL4J 可与 Hadoop 和 Spark 集成,支持分布式计算与大规模数据集上的模型训练,广泛应用于金融、工业制造、推荐系统等行业场景。
支持的语言类型包括:Java、Scala 等。
[此处为图片2]

 京公网安备 11010802022788号
京公网安备 11010802022788号







