


 雷达卡
雷达卡



人工智能(AI)的三大核心工具链:重塑现代开发范式
在当今技术浪潮中,人工智能正以前所未有的速度与深度渗透至各个行业。这一变革的背后,离不开一套日趋完善且高效的AI工具生态系统。从代码编写、数据处理到模型训练,每一个关键环节都已被智能化工具重新定义。本文将聚焦于三大支柱性工具——智能编码辅助系统、专业数据标注平台和高效模型训练环境,深入剖析它们如何协同驱动AI应用的发展,并通过代码片段、流程图、Prompt示例及图表展示其实际运作机制。
一、智能编码辅助系统:你的AI编程伙伴
以GitHub Copilot为代表的智能编码工具,已从早期的“辅助补全”功能进化为开发者日常工作中不可或缺的“虚拟结对程序员”。这类工具依托大型语言模型(LLM),能够理解当前项目的上下文环境,实时提供高质量的代码建议,甚至自动生成完整函数逻辑。
1.1 GitHub Copilot:超越传统自动补全
基于OpenAI GPT系列模型构建,GitHub Copilot的核心优势在于其强大的上下文感知能力。它不仅能读取当前文件内容,还能分析项目中的其他相关代码以及注释信息,从而生成语义连贯、结构合理的代码建议。
主要价值体现:
- 提升开发效率:自动化完成大量模板化编码任务,使开发者能集中精力解决复杂业务逻辑。
- 促进技术学习:面对陌生API或新语言特性时,Copilot可即时提供可用示例,降低学习成本。
- 增强代码规范性:遵循主流编码风格与最佳实践,有助于统一团队代码质量标准。
- 降低入门难度:对新手而言,Copilot如同一位随时在线的导师,引导其逐步掌握编程技巧。
1.2 实战演示:从自然语言注释生成可执行代码
以下是一个Python场景实例,展示Copilot如何将一段简单描述转化为完整的异步网络请求处理函数。
需求说明: 编写一个函数,接收一组URL地址,使用异步方式批量检测每个链接是否返回HTTP状态码200(即正常响应)。
开发者仅需输入如下注释:
# 编写一个异步函数,名为check_urls,它接收一个URL列表。
# 该函数应使用aiohttp库异步检查每个URL的HTTP状态码。
# 返回一个字典,键是URL,值是布尔值,表示URL是否可访问(状态码为200)。Copilot可能自动生成如下实现代码:
import aiohttp
import asyncio
from typing import List, Dict
async def check_urls(urls: List[str]) -> Dict[str, bool]:
"""
Asynchronously checks the status code of a list of URLs.
Args:
urls: A list of URL strings to check.
Returns:
A dictionary where keys are URLs and values are booleans
indicating if the URL is accessible (status code 200).
"""
results = {}
async with aiohttp.ClientSession() as session:
# 为每个URL创建一个任务
tasks = [check_single_url(session, url) for url in urls]
# 并发执行所有任务
accessible_statuses = await asyncio.gather(*tasks)
# 将结果组装成字典
for url, is_accessible in zip(urls, accessible_statuses):
results[url] = is_accessible
return results
async def check_single_url(session: aiohttp.ClientSession, url: str) -> bool:
"""Helper function to check a single URL."""
try:
async with session.get(url, timeout=10) as response:
return response.status == 200
except Exception:
return False
# --- 使用示例 ---
if __name__ == "__main__":
urls_to_check = [
"https://www.google.com" ,
"https://www.github.com" ,
"https://www.nonexistent-website-12345.com"
]
# 运行异步函数
results = asyncio.run(check_urls(urls_to_check))
print("URL Accessibility Check Results:")
for url, is_ok in results.items():
status = "OK" if is_ok else "Failed"
print(f"- {url}: {status}")该过程体现了Copilot的综合理解能力:准确识别“异步”、“aiohttp库调用”、“状态码判断”等关键词,并合理构建包含错误捕获、类型提示和调用示例的完整函数结构。
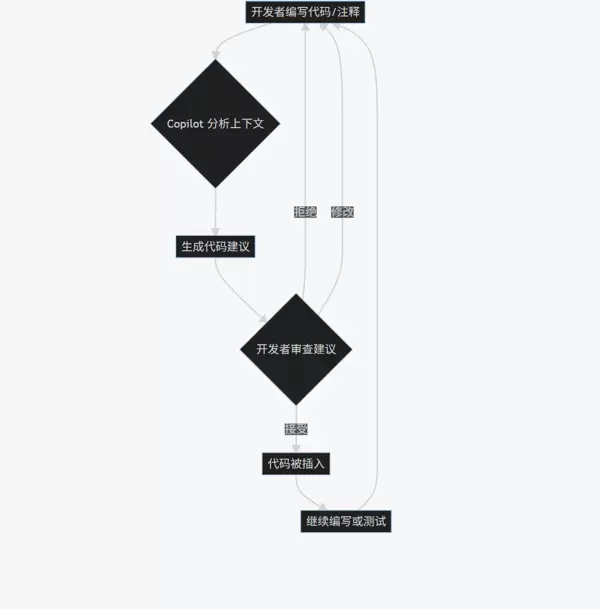
1.3 协作流程解析:人机共编的典型路径
下图展示了开发者与Copilot交互的标准工作流:
1.4 Prompt设计指南:如何有效“指挥”AI助手
在Copilot系统中,用户的代码与注释本身就是向AI发出的指令(Prompt)。高质量的Prompt能显著提升输出结果的准确性与实用性。
Prompt 示例 1(Web开发场景):
// 使用React和TypeScript创建一个名为UserProfile的组件。
// 该组件接收userId作为prop。
// 组件内部使用useState和useEffect钩子,
// 当userId改变时,从'/api/users/{userId}'获取用户数据并显示。
// 显示内容包括:name, email, 和一个头像。Prompt 示例 2(数据处理任务):
# 使用pandas读取'sales_data.csv'文件。
# 数据包含'product_id', 'sale_date', 'amount'三列。
# 请将'sale_date'转换为datetime对象,并设置为索引。
# 然后,按月计算总销售额,并生成一个条形图。优化建议:
- 表述清晰具体:越详细的注释描述,越有利于AI精准理解意图。
- 保持上下文可见:确保相关的类、函数或依赖文件处于打开状态,便于Copilot获取完整信息。
- 迭代式引导:若首次生成不理想,可通过追加注释逐步修正方向。
- 必须人工审核:AI生成代码存在潜在风险,务必经过严格审查与测试后方可上线。
二、数据标注平台:打造AI学习的“标准教材”
如果说算法是人工智能的“大脑”,算力是“肌肉”,那么数据便是其赖以生存的“血液”。在监督学习体系中,模型的表现高度依赖于训练数据的质量。“垃圾进,垃圾出”这一原则始终成立。因此,构建高精度、结构化的标注数据集至关重要,而专业的数据标注工具正是为此而生。
2.1 为何需要专用标注工具?
使用通用编辑器进行手动标注不仅效率低下,而且难以保证一致性与可管理性。专业的数据标注平台提供了系统化的解决方案,涵盖:
- 标准化操作流程:统一标注规则,减少人为偏差。
- 多用户协作支持:实现任务分发、进度跟踪与团队协同作业。
- 质量保障机制:内置审核流程、共识校验与抽检功能,确保标注准确率达标。
- 效率优化特性:集成快捷键、AI预标注、自动分割等功能,大幅提升标注速度。
- 数据生命周期管理:支持版本控制、元数据记录与多种格式导出。
2.2 常见标注类型及其对应功能
| 数据模态 | 典型任务 | 工具核心功能 |
|---|---|---|
| 图像标注 | 图像分类、目标检测、语义/实例分割 | 绘制边界框、多边形、关键点、像素级掩码 |
| 文本标注 | 文本分类、命名实体识别(NER)、情感分析、关系抽取 | 文本高亮、标签选择、实体间关系连线 |
| 音频标注 | 语音识别(ASR)、声学事件检测、说话人日志 | 时间轴切片、语音转写、标签标注 |
| 视频标注 | 行为识别、目标跟踪 | 逐帧或关键帧标注、轨迹路径绘制 |
2.3 数据标注典型工作流
一个完整的数据标注流程通常包括以下几个阶段:
- 数据导入与预处理:上传原始数据并进行清洗、去重、格式转换。
- 任务分配:根据项目需求将数据划分为子集,分配给不同标注人员。
- 标注执行:标注员使用工具完成指定类型的标记任务。
- 质检与复核:由高级标注员或质检团队对结果进行抽查与修正。
- 数据导出:将最终确认的标注结果以标准格式(如COCO、Pascal VOC、JSONL等)导出用于模型训练。
一个标准的数据标注项目通常包含一系列有序的步骤,其中专业化的工具在整个流程中起到关键作用。以下是典型的工作流:
flowchart LR
A[原始数据] --> B(导入标注平台);
B --> C{创建标注任务};
C --> D[分配给标注员];
D --> E[标注员进行标注];
E --> F{质检/审核};
F -- 通过 --> G[导出标注数据];
F -- 不通过 --> E;
G --> H[用于模型训练];

经过严格的质量控制后,最终输出的标注数据将被用于后续的模型训练阶段,确保输入数据的准确性和可用性。
2.5 给标注员的指令示例(Prompt)
在数据标注系统中,“Prompt”指的是提供给标注人员的具体操作指南,要求清晰且无歧义,以保证标注结果的一致性。
Prompt 示例1:图像目标检测
任务描述:
对城市道路场景中的各类车辆绘制精确的边界框。
可选标签类别:
carbustruck标注规范:
- 边界框应紧密贴合车辆轮廓,尽可能减少包含背景区域。
- 若车辆被部分遮挡但可见面积超过50%,仍需进行标注。
- 对于严重模糊或可见度低于50%的情况,则不予标注。
- 行人对象使用
pedestrianPrompt 示例2:文本命名实体识别
任务描述:
在指定新闻文本中识别并标注所有命名实体。
实体类型定义:
PERORGLOC标注规则说明:
- 实体需完整标注,例如“北京大学”应整体标注为
ORGLOCORG- 需结合上下文判断同名实体的正确类别,避免误标。 [图片:数据标注工具界面截图,显示图像上的边界框和标签列表]
2.4 标注数据的输出格式示例
标注工具最终生成的是结构化数据文件,JSON 是最常用的格式之一。以下是一个基于 COCO 标准的目标检测 JSON 片段示例:
{
"images": [
{
"id": 1,
"file_name": "image_001.jpg",
"height": 720,
"width": 1280
}
],
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 1, // 假设1代表"cat"
"bbox": [450, 300, 200, 150], // [x, y, width, height]
"area": 30000,
"iscrowd": 0
},
{
"id": 2,
"image_id": 1,
"category_id": 2, // 假设2代表"dog"
"bbox": [800, 320, 180, 160],
"area": 28800,
"iscrowd": 0
}
],
"categories": [
{"id": 1, "name": "cat"},
{"id": 2, "name": "dog"}
]
}此类结构化的标注结果可直接被主流深度学习框架(如 PyTorch、TensorFlow)读取和处理,进而投入到模型训练流程中。
2.6 不同标注任务的复杂度与成本对比图表
bar-chart
title 不同数据标注任务的相对复杂度与成本
x-axis 标注类型
y-axis "相对成本/时间"
series 成本
"图像分类": 1
"目标检测": 3
"语义分割": 8
"文本分类": 2
"命名实体识别": 4
该图表表明,随着标注粒度的提升——从简单的分类到像素级的语义分割——所需的人力投入和时间成本呈显著上升趋势,反映出高精度标注任务更高的资源消耗特性。
第三部分:模型训练平台 —— AI 的“工厂与指挥中心”
在完成数据准备与代码实现之后,模型训练进入资源消耗最大、技术复杂度最高的阶段。为此,模型训练平台(也称 MLOps 平台)应运而生,旨在为机器学习工程师提供覆盖实验、训练到部署全生命周期的一体化管理环境。
3.1 为何需要模型训练平台?
在本地设备上执行模型训练,尤其面对大规模数据集和深层网络结构时,常面临以下问题:
- 算力不足:个人电脑的 GPU 资源有限,难以支持分布式或大规模训练任务。
- 管理混乱:实验记录、参数设置、模型版本多依赖人工维护,容易出错且难以复现。
- 协作困难:团队成员之间缺乏统一平台共享成果,影响效率与知识沉淀。
- 部署鸿沟:从开发环境迁移到生产服务存在兼容性与稳定性挑战,即所谓的“最后一公里”难题。
模型训练平台通过标准化流程与自动化机制,有效缓解上述痛点。
3.2 平台的核心功能模块
| 组件 | 功能 | 常见工具/服务 |
|---|---|---|
| 计算资源管理 | 动态调度 CPU/GPU/TPU 集群,支持分布式训练 | Kubernetes, NVIDIA DGX, AWS SageMaker, Google Vertex AI |
| 实验跟踪 | 记录每次运行的代码、配置、超参数及评估指标 | Weights & Biases (W&B), MLflow, TensorBoard |
| 模型注册表 | 集中存储训练好的模型及其元信息,支持版本控制 | MLflow Model Registry, SageMaker Model Registry |
| 自动化流水线 | 整合数据预处理、训练、评估、部署等环节,形成可复现流程 | Kubeflow Pipelines, TensorFlow Extended (TFX), Azure ML Pipelines |
| 特征存储 | 统一管理特征数据,保障训练与推理阶段的一致性 | Feast, Tecton |
3.3 MLOps 生命周期流程图
模型训练平台是实现 MLOps 理念的关键支撑。下图展示了其驱动下的完整生命周期:
flowchart TD
subgraph "开发与实验"
A[数据准备] --> B[模型开发与实验];
B --> C[实验跟踪];
end
subgraph "生产与运维"
D[模型注册与版本控制] --> E[自动化部署];
E --> F[线上监控];
end
C -- 选出最佳模型 --> D;
F -- 性能衰退/数据漂移 --> G[触发再训练];
G --> A;
3.5 Prompt示例:定义自动化任务流程
在现代模型训练平台中,“Prompt”往往体现为对自动化系统(如超参数搜索、训练流水线等)的声明式配置。通过简洁的配置文件或代码,开发者可以指示系统如何自动执行复杂任务。Prompt示例1(超参数搜索配置 — 使用W&B Sweep):
# sweep_config.yaml
program: train.py
method: bayes # 使用贝叶斯优化进行搜索
metric:
name: val_accuracy
goal: maximize
parameters:
learning_rate:
min: 0.0001
max: 0.1
distribution: log_uniform_values
batch_size:
values: [32, 64, 128]
dropout:
min: 0.1
max: 0.5
distribution: uniform该YAML配置本质上是一种“Prompt”,用于指导W&B的Sweep控制器启动指定训练脚本
train.pyval_accuracyPrompt示例2(构建机器学习流水线 — 基于Kubeflow Pipelines):
# 这是一个简化的Python DSL示例
from kfp import dsl
@dsl.component
def preprocess_op(data_path: str):
# ... 数据预处理逻辑 ...
return processed_data_path
@dsl.component
def train_op(processed_data_path: str, learning_rate: float):
# ... 模型训练逻辑 ...
return model_path
@dsl.pipeline
def my_ml_pipeline(data_path: str, learning_rate: float = 0.01):
preprocess_task = preprocess_op(data_path=data_path)
train_task = train_op(
processed_data_path=preprocess_task.output,
learning_rate=learning_rate
)上述代码段定义了一个任务执行的“蓝图”或称为“Prompt”,明确指出了
preprocesstrain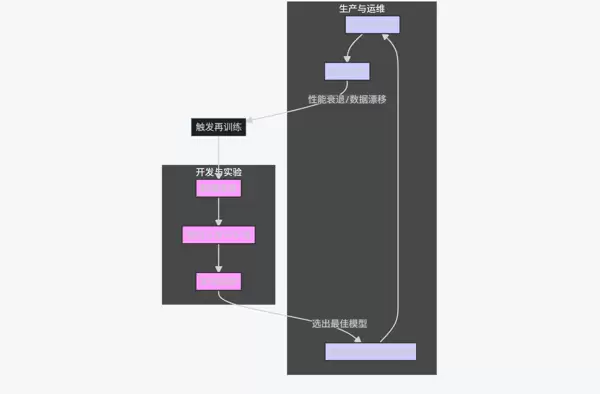
3.4 代码实践:集成W&B实现实验追踪
Weights & Biases(简称W&B)是当前广泛使用的实验跟踪工具之一。以下代码展示了如何将其嵌入一个基础的PyTorch训练流程中,以实现全过程监控。import wandb
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 1. 初始化W&B项目
wandb.init(
project="my-mnist-project",
config={
"learning_rate": 0.01,
"batch_size": 64,
"architecture": "CNN",
"epochs": 10,
}
)
# 从wandb.config中获取超参数,便于在UI中调整
config = wandb.config
# 简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = torch.relu(x)
x = self.conv2(x)
x = torch.relu(x)
x = torch.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = torch.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = torch.log_softmax(x, dim=1)
return output
# 数据准备和模型实例化
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True)
model = SimpleCNN()
optimizer = optim.Adam(model.parameters(), lr=config.learning_rate)
criterion = nn.NLLLoss()
# 训练循环
model.train()
for epoch in range(config.epochs):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 2. 记录指标到W&B
if batch_idx % 100 == 0:
wandb.log({
"epoch": epoch,
"batch_loss": loss.item(),
# 可以记录更多自定义指标
})
print(f"Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item()}")
# 3. (可选) 保存模型到W&B
wandb.save("my_model.pth")
wandb.finish()执行该脚本后,可在W&B仪表盘中实时观察到清晰的可视化图表,动态反映
batch_lossepoch[图片:模型训练平台(如W&B或TensorBoard)的实验跟踪仪表盘截图]
结语:三位一体,推动AI持续创新
智能编码工具、数据标注系统与模型训练平台并非彼此割裂,而是共同构成了现代人工智能开发体系中不可或缺的三大支柱,环环相扣,协同增效。- 数据标注工具 负责生成高质量的“燃料”——即经过精确标注的数据集,为模型学习提供基础。
- 智能编码工具 协助开发者高效打造“引擎”——即模型架构与核心算法代码,提升研发效率。
- 模型训练平台 则扮演着“工厂”与“指挥中心”的双重角色,整合数据与代码,实现模型的大规模训练、部署与性能监控。

 京公网安备 11010802022788号
京公网安备 11010802022788号







