


 雷达卡
雷达卡



目前市面上常见的爬虫工具主要可以分为三类:通用型、浏览器自动化型以及无代码交互式。其中,通用型框架如Scrapy,或基于浏览器自动化的Selenium,都需要使用者具备一定的编程基础才能完成数据采集任务。而无代码交互式工具则不同,像八爪鱼、Web Scraby这类软件,用户只需掌握其配置规则,通过简单的拖拽操作即可实现网页数据的抓取,使用方式类似于Excel或Photoshop等图形化应用。
八爪鱼是一款广受欢迎的桌面端数据采集工具,以其无需编写代码、操作界面直观便捷著称。用户只需设定目标URL,并通过可视化界面进行简单操作,便可实现大规模网络数据的批量提取。
无论是文本、图片、视频还是表格内容,八爪鱼均能有效抓取。此外,它还提供了大量预设的采集模板,覆盖电商、新闻资讯、短视频平台等多个主流领域。这些模板已预先配置好采集流程,用户可直接调用,实现一键式数据爬取。
使用八爪鱼的基本步骤非常清晰,主要包括以下三个环节:
- 从官网下载并安装客户端,随后注册账号登录;
- 输入目标网页地址(例如新浪微博评论页),选择“自动识别网页”功能;
- 点击开始采集,完成后将数据导出为Excel或CSV格式文件。
对于较为复杂的采集需求,可能需要手动调整页面元素的抓取逻辑,配置难度相对较高。但即便如此,八爪鱼仍为用户提供了上百种针对主流网站的内置爬虫任务模板,涵盖电商平台、社交媒体、新闻站点、论坛社区、游戏及APP等多种场景,相当于已经完成了整个爬虫流程的设置工作。
用户只需选择对应模板并启动任务,即可自动执行数据抓取。这种设计极大降低了技术门槛,无论是否具备开发背景,都能快速上手,显著提升数据采集效率。
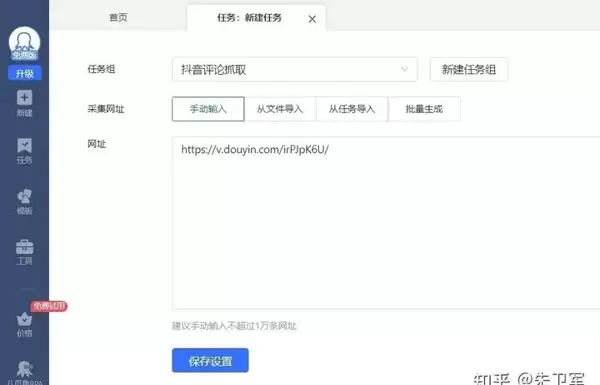
接下来以抖音评论数据采集为例,说明具体操作流程:
第一步是创建新的采集任务,填写任务名称(如“抖音评论抓取”)以及目标视频的URL链接。
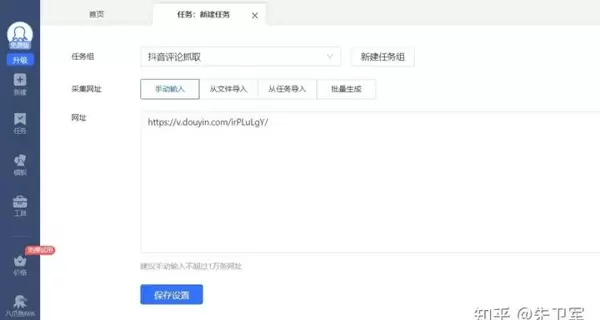
进入配置界面后,需先登录抖音账号,系统会自动保存登录状态,确保后续操作可在已登录环境下进行。
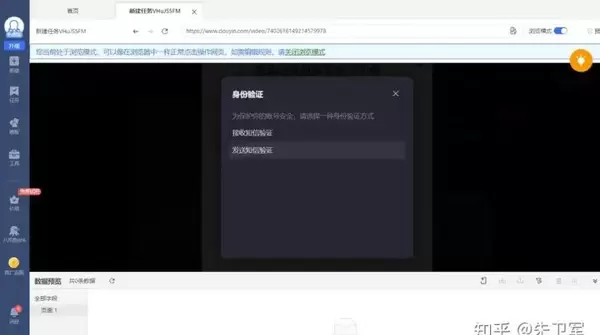
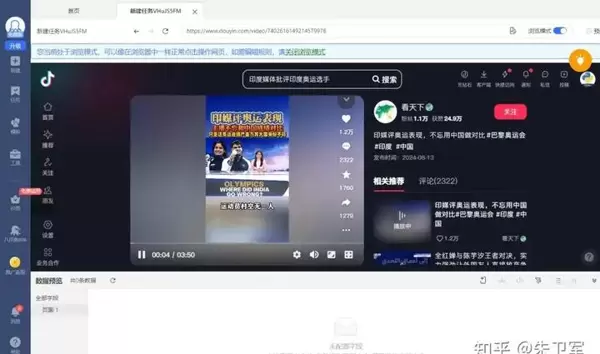
然后设置具体的采集步骤:确定抓取文本内容 → 配置循环翻页规则 → 确认数据提取方式。你也可以启用“自动识别网页”功能,由系统智能识别并提取评论区域的信息。
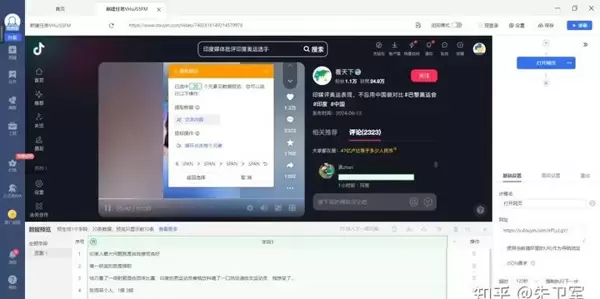
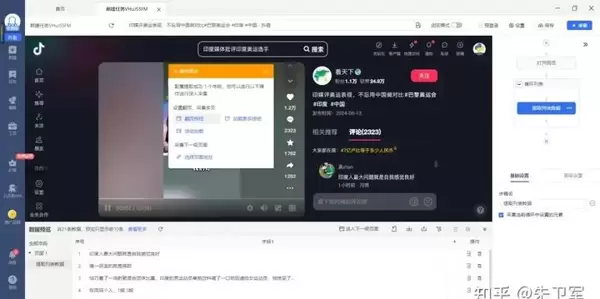
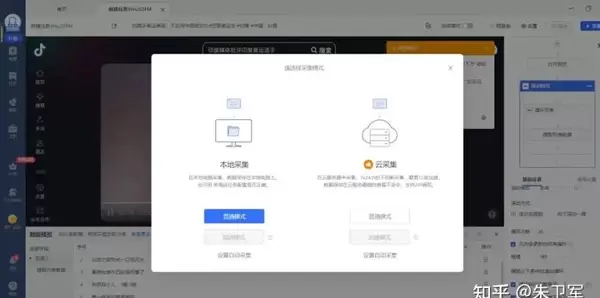
在整个过程中,可通过数据预览功能实时查看即将获取的评论内容,确认无误后即可执行完整采集,并将结果导出保存。
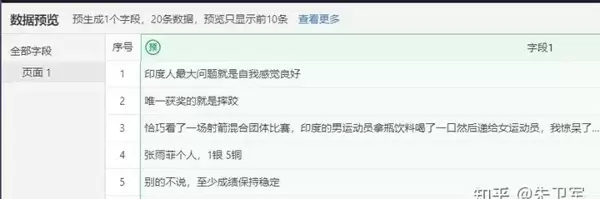
若不想手动配置,还可直接使用八爪鱼提供的抖音评论专用模板。仅需输入目标视频链接,即可实现全自动一键采集所有评论信息。
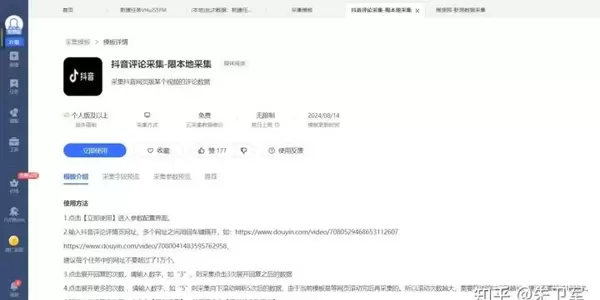
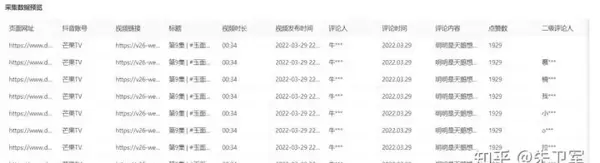
对于其他类型的抖音数据抓取任务,比如用户主页信息采集,也有相应的教程可供参考,内容详实易懂。
总体而言,八爪鱼作为一款完全图形化的数据采集工具,操作简便,支持多种数据类型和应用场景。它不仅提供丰富的模板资源,还集成了从网页登录、批量抓取到数据清洗的一整套自动化流程,能够满足大多数用户的实际需求。无论是IT技术人员、自媒体运营者、商铺管理者还是商业分析人员,都可以借助该工具高效完成数据收集工作。
建议初学者可以从一个简单的案例入手,亲自尝试操作一遍,快速掌握其核心功能。

 京公网安备 11010802022788号
京公网安备 11010802022788号







