


 雷达卡
雷达卡



训练营概览
2025年昇腾CANN训练营第二季正式开启,依托CANN开源开放的全场景能力,推出面向不同开发阶段人群的系列课程,涵盖零基础入门、码力强化特辑以及真实开发者案例解析等内容。无论你是初学者还是进阶开发者,都能在此快速提升Ascend C算子开发技能。
成功获得Ascend C算子中级认证后,可领取专属精美证书;积极参与社区任务还有机会赢取华为手机、平板、开发板等丰富奖品。

引言:从“跑通”到工程化思维
在算子开发初期,目标通常是“先让代码运行起来”。例如,写一个
Add算子,通过复制粘贴改造成
Sub算子,再稍作修改变为
Mul算子。
然而,随着项目中算子数量不断增长,这种“复制-粘贴”式开发方式逐渐暴露出严重问题:
- 维护成本高:若需优化流水线结构(如引入Double Buffer机制),必须逐一修改每个算子文件。
- 代码冗余明显:核心业务逻辑被大量重复的内存管理与数据搬运代码掩盖,阅读困难。
- 易出错风险大:每次手动编写
AllocTensorFreeTensor真正优秀的工程实践,核心在于抽象与复用。本文将引导你使用C++模板技术对原有代码进行重构,构建一个适用于工业级开发的Ascend C算子微框架。
一、设计哲学:基于策略的设计模式(Policy-Based Design)
观察常见的Element-wise类算子,可以发现它们具有高度一致的执行流程——即通用骨架:
- Init:完成Tensor与Tiling的初始化。
- Process:按块循环处理数据。
- CopyIn/Out:负责Host与Device间的数据搬入与搬出。
其本质差异仅体现在
Compute阶段所调用的具体计算指令上(如Add、Sub、Mul等)。
由此,我们可以将公共流程提取为模板骨架,而将变化部分封装为独立的计算策略(Policy),实现解耦与复用。
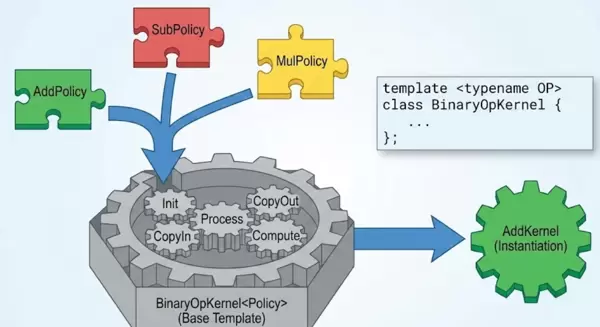
二、实战重构:构建BinaryOpKernel模板
我们的目标是创建一个通用的“二元操作算子模板”,统一处理双输入单输出场景下的所有数据搬运与流水线调度逻辑。
2.1 定义计算策略接口
首先明确策略类需要实现的基本行为规范。
// math_ops.h
// 加法策略
struct AddPolicy {
// 静态函数,将被模板内联,无性能损耗
__aicore__ static inline void Exec(LocalTensor<half>& z,
LocalTensor<half>& x,
LocalTensor<half>& y,
uint32_t len) {
Add(z, x, y, len);
}
};
// 减法策略
struct SubPolicy {
__aicore__ static inline void Exec(LocalTensor<half>& z,
LocalTensor<half>& x,
LocalTensor<half>& y,
uint32_t len) {
Sub(z, x, y, len);
}
};2.2 构建通用执行骨架
接下来进入核心环节:定义一个接受
OpPolicy作为模板参数的通用类。
// binary_op_base.h
#include "kernel_operator.h"
using namespace AscendC;
template <typename OpPolicy>
class BinaryOpKernel {
public:
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z,
uint32_t totalLen, uint32_t tileLen) {
// ... 标准的初始化代码 ...
// 复用之前的 Init 逻辑,完全通用
this->tileLength = tileLen;
// ...
}
__aicore__ inline void Process() {
// ... 标准的 Process 循环 ...
int32_t loopCount = this->totalLength / this->tileLength;
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}
private:
__aicore__ inline void Compute(int32_t i) {
LocalTensor<half> xLoc = inQueueX.DeQue<half>();
LocalTensor<half> yLoc = inQueueY.DeQue<half>();
LocalTensor<half> zLoc = outQueueZ.AllocTensor<half>();
// 【关键点】调用策略类的静态函数
// 编译器会在这里直接内联展开 Add(z, x, y, len)
// 就像直接写在这一样,没有函数调用开销
OpPolicy::Exec(zLoc, xLoc, yLoc, this->tileLength);
inQueueX.FreeTensor(xLoc);
inQueueY.FreeTensor(yLoc);
outQueueZ.EnQue(zLoc);
}
// CopyIn 和 CopyOut 也是完全通用的,此处省略...
// ...
};三、成效展示:五步实现新算子
当该框架搭建完成后,实现一个新的
Add算子需要多少行代码?答案是极简的几行即可完成。
// add_custom.cpp
#include "binary_op_base.h"
#include "math_ops.h"
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z, GM_ADDR tiling) {
GET_TILING_DATA(tiling_data, tiling);
// 实例化模板:使用 AddPolicy
BinaryOpKernel<AddPolicy> op;
op.Init(x, y, z, tiling_data.totalLength, tiling_data.tileLength);
op.Process();
}如果要实现
Sub算子呢?仅需替换一个关键词:
BinaryOpKernel<SubPolicy> op;至此,我们成功将原本需要编写上百行代码的工作,简化为“定义一个Policy + 模板实例化”的标准化流程。
四、应对复杂场景:扩展策略接口
你可能会提出疑问:这种方式是否只适用于简单的逐元素运算?对于RoPE这类结构复杂的算子是否依然适用?
答案是肯定的——只要我们增强策略接口的能力。
例如,在设计
ComplexOpKernel时,可要求其实现的Policy提供
Init()(用于预生成Sin/Cos查找表)和
Exec()等额外方法。
struct RoPEPolicy {
LocalTensor<half> sinTable, cosTable;
__aicore__ inline void Init(TPipe& pipe) {
// 预加载 Sin/Cos 表到 UB
}
__aicore__ inline void Exec(LocalTensor<half>& out, LocalTensor<half>& in, ...) {
// 执行复杂的旋转逻辑
}
};借助C++的
SFINAE(Substitution Failure Is Not An Error)
或C++20中的Concept特性,模板甚至能自动检测Policy是否包含
Init函数,并据此决定是否执行相关逻辑。尽管AI Core编译器对现代C++特性的支持有限,但基础的模板特化(Template Specialization)功能完全可用,足以支撑此类高级抽象。
五、结语:工程美学的价值所在
追求良好的工程结构并非为了炫技,而是为了切实提升开发效率与代码质量。
- 高复用性:通用逻辑只需编写一次、测试一次,所有依赖该框架的算子均可共享成果。
- 强可维护性:一旦发现流水线存在缺陷,只需修复一处,所有派生算子同步受益。
- 零成本抽象:采用C++模板而非虚函数继承,所有抽象在编译期展开,运行时无任何性能损耗(Zero-overhead Abstraction)。
Happy Coding!

 京公网安备 11010802022788号
京公网安备 11010802022788号







