


 雷达卡
雷达卡



在大模型工程化落地的实践中,本地部署常面临模型适配复杂、硬件资源利用率低等挑战。作为一名长期从事该领域的开发者,我深刻体会到高效部署工具的重要性。
OpenStation 新版本针对“模型兼容性差”与“资源分配粗放”两大核心问题,在模型生态支持和推理调度机制上进行了关键升级,显著提升了开发效率与系统灵活性。以下从技术实践角度,解析其主要改进点。
1. 模型生态扩展:满足多样化场景需求,降低接入成本
不同业务场景对模型能力的要求差异明显,单一模型难以覆盖全部应用。为此,新版本在模型下载中心新增了 DeepSeek-V3、Moonshot 和 ZhipuAI 等主流模型系列,全面覆盖技术研发、知识库问答及商业服务等多种应用场景。所有新增模型均已通过平台级适配,实现“即下即用”,大幅减少开发者的基础配置工作量。
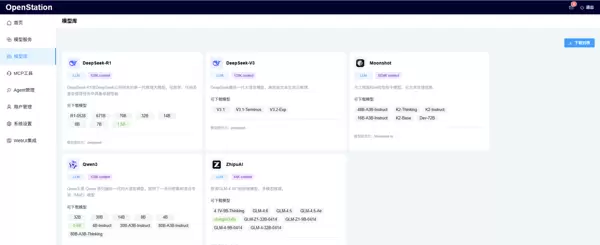
DeepSeek-V3:在代码生成任务中表现优异,尤其在 SWE-bench 测试中,复杂算法逻辑的完整性较前代有显著提升,适用于高要求的技术研发类项目;
Moonshot:具备强大的长文本处理能力,部署于知识库问答系统时可稳定解析超过 5000 字的文档,长文本理解准确率优于通用基础模型;
ZhipuAI 系列:面向商业服务场景优化,具备出色的多轮对话上下文保持能力,行业术语输出精准,适合金融等领域智能客服系统的定制化部署。
从平台架构角度看,这些主流模型的集成构建了“业务需求—模型选择—场景匹配”的闭环体系。OpenStation 通过统一模型元数据标准和推理接口规范,使开发者能够根据实际需要快速切换模型。例如,在同一服务框架下,仅需修改配置文件即可实现在 DeepSeek-V3(用于代码生成)与 ZhipuAI(用于客户服务)之间的无缝迁移。这种灵活性在多业务融合场景中具有重要价值。
2. 推理调度机制升级:从整机到卡级调度,提升资源利用效率
传统部署方式中,旧版 OpenStation 仅支持整机级别的资源分配,导致明显的资源浪费——例如运行 7B 参数模型本只需单张 GPU 卡,却不得不独占整台设备。新版本引入 GPU 精细化调度机制,支持在单机或分布式环境下按需分配具体加速卡资源,开发者可通过图形界面精确指定使用某一张或多张 GPU 卡,极大提升了硬件利用率。
部署模式与节点选择策略如下:
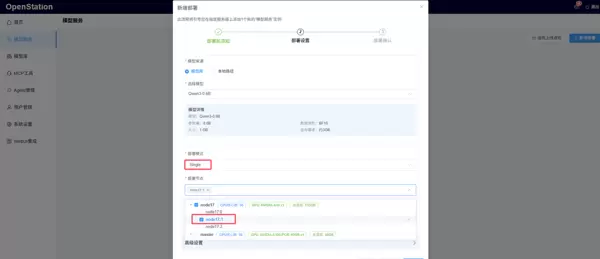
- Single(单机部署):可选择一个 GPU 节点,并至少分配一张加速卡来运行单个实例;支持 SGLang (GPU) 和 vLLM (GPU) 推理引擎,适用于中小参数量模型的独立部署;
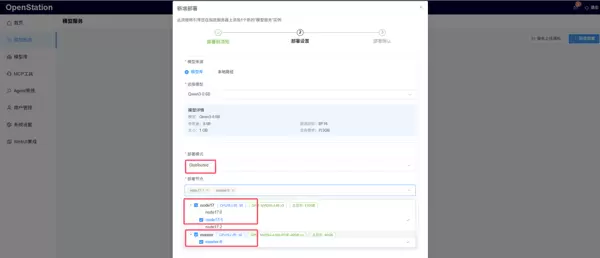
- Distributed(分布式部署):需选择两个及以上计算节点,且每个节点分配相同数量的加速卡;平台自动启用张量并行与流水线并行策略,推荐使用 vLLM (GPU) 引擎,适用于大参数模型的跨节点部署;
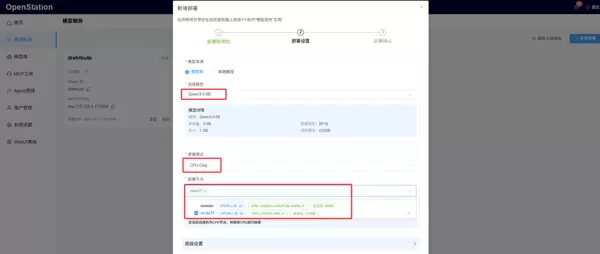
- CPU-Only(纯 CPU 部署):可在任意 GPU 或 CPU 节点上部署单个实例,选用 vLLM (CPU-only) 推理引擎,满足无 GPU 环境下的轻量化运行需求。
典型部署示例:
单机部署场景:以 node17 节点(配备 3 张 NVIDIA-A40 加速卡)为例,开发者可仅选择其中一张卡进行模型部署,避免整机资源被独占。
分布式部署场景:可在 master 节点(含 1 张 NVIDIA-A100)与 node17 节点(含 3 张 NVIDIA-A40)之间各选取一张加速卡协同部署,平台将自动完成跨节点通信与任务分发。
CPU 部署场景:可在任意可用节点上执行 CPU 模式部署,灵活应对资源受限环境。
部署后管理功能:服务上线后,平台界面清晰展示实例状态、Model ID、API 访问地址及部署时间,支持查看与删除操作,便于日常运维。
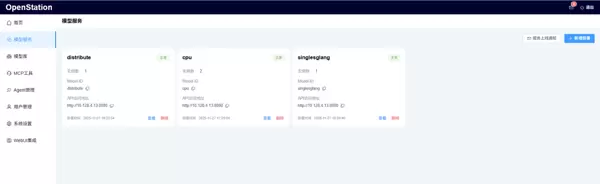
此外,新版本还引入了基于卡级别的性能校准与动态任务分配机制,有效缓解分布式部署中的“算力瓶颈”问题。通过对每张加速卡的性能特征与负载情况进行匹配调度,确保整体系统运行在最优状态,从而提升训练与推理的整体吞吐效率。
3. 快速部署指南:三步完成环境搭建
OpenStation 提供便捷的安装流程,支持在线与离线两种方式,适配多种 Linux 发行版。
项目源码地址:
https://github.com/fastaistack/OpenStation
- 在线安装(支持 Ubuntu 22.04 / 20.04 / 18.04 及 CentOS 7 系列)
curl -O https://fastaistack.oss-cn-beijing.aliyuncs.com/openstation/openstation-install-online.sh
bash openstation-install-online.sh --version 0.6.7也可手动下载在线安装包 openstation-pkg-online-v0.6.7.tar.gz,上传至目标服务器后执行安装命令。
tar -xvzf openstation-pkg-online-v0.6.7.tar.gz
cd openstation-pkg-online-v0.6.7/deploy && bash install.sh true- 离线安装(仅限 Ubuntu 22.04.2 / 20.04.6 / 18.04.6)
点击「离线 OpenStation 安装包下载」,并参考上述 GitHub 项目仓库中的离线安装说明文档进行操作。
完成部署后,登录界面如下所示:
4. 总结
OpenStation 新版本的核心突破在于从模型生态建设与资源调度粒度两个维度解决了本地大模型部署的关键难题。通过拓展主流模型支持范围,实现了“开箱即用”的便捷体验;借助 GPU 级别的精细化调度能力,显著提升了硬件资源的利用效率。这两项改进共同为开发者提供了更加灵活、高效的本地化部署解决方案,切实推动大模型技术向真实业务场景的深度落地。
在资源调度层面,通过精细化的 GPU 管理机制,有效避免了“大马拉小车”式的资源浪费现象,在提升硬件利用效率的同时,显著降低了部署成本。
在模型生态建设上,借助对主流模型的适配以及统一接口的设计,大幅减少了开发者重复开发的工作量,加快了从模型获取到实际部署的整个周期。
未来期望平台能够持续完善对异构算力的支持能力,例如实现对国产加速卡的调度管理,从而为大模型的本地化部署提供更加全面和灵活的技术保障。

 京公网安备 11010802022788号
京公网安备 11010802022788号







