


 雷达卡
雷达卡



人工智能之数据分析 Matplotlib
第七章 项目实践
前言
通过实际项目来掌握 Matplotlib 的使用,是提升数据可视化能力的有效途径。本文将引导你完成一个完整的端到端分析流程,涵盖从数据生成、清洗处理到多维度可视化的全过程,结合 NumPy 与 Pandas 工具,深入应用 Matplotlib 进行探索性数据分析。
项目目标
对某电商平台的用户月度销售数据进行综合分析,挖掘销售趋势、品类分布、区域表现及数据分布特征。
数据内容(模拟)
- 日期:
date - 销售额:
sales - 商品类别:
(如 “Electronics”, “Clothing”, “Books”)category - 用户地区:
(如 “North”, “South”, “East”, “West”)region
第一步:环境准备与数据生成
# 导入必要库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
# 设置中文字体支持(适用于Windows系统)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 生成模拟数据(实际项目中通常来自CSV或数据库)
np.random.seed(42)
dates = pd.date_range(start='2024-01-01', end='2024-12-31', freq='D')
data = []
categories = ['Electronics', 'Clothing', 'Books']
regions = ['North', 'South', 'East', 'West']
for date in dates:
for _ in range(np.random.randint(5, 15)): # 每日随机生成订单数量
data.append({
'date': date,
'sales': np.round(np.random.uniform(20, 500), 2),
'category': np.random.choice(categories),
'region': np.random.choice(regions)
})
df = pd.DataFrame(data)
print(df.head())
第二步:数据预处理
为后续分析做准备,需提取时间中的月份信息,并按月汇总销售额。
# 创建月份字段
df['month'] = df['date'].dt.to_period('M')
# 按月统计总销售额
monthly_sales = df.groupby('month')['sales'].sum().reset_index()
monthly_sales['month'] = monthly_sales['month'].astype(str) # 转换为字符串类型以便绘图
第三步:Matplotlib 可视化分析
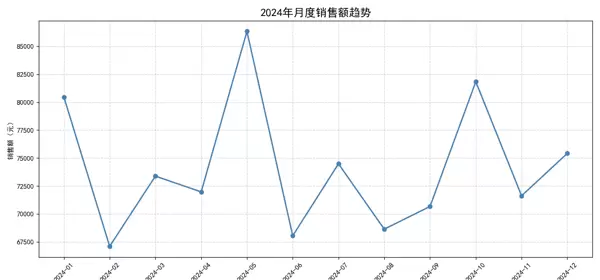
1. 月度销售额趋势(折线图)
通过折线图观察全年销售额的变化趋势。
plt.figure(figsize=(12, 6))
plt.plot(monthly_sales['month'], monthly_sales['sales'], marker='o', linewidth=2, color='steelblue')
plt.title('2024年月度销售额趋势', fontsize=16)
plt.xlabel('月份')
plt.ylabel('销售额(元)')
plt.xticks(rotation=45)
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()
2. 各商品类别销售额占比(饼图)
展示不同商品类别在总体销售额中的占比情况。
category_sales = df.groupby('category')['sales'].sum()
plt.figure(figsize=(8, 8))
plt.pie(category_sales, labels=category_sales.index, autopct='%1.1f%%', startangle=140, colors=plt.cm.Set3.colors)
plt.title('各商品类别销售额占比')
plt.axis('equal') # 确保饼图为圆形
plt.show()
3. 各地区月度销售对比(分组柱状图)
分析不同地区在每个月的销售表现差异。
# 按地区和月份汇总销售额
region_month_sales = df.groupby(['month', 'region'])['sales'].sum().unstack(fill_value=0)
# 绘制分组柱状图
regions = region_month_sales.columns
months = region_month_sales.index
x = np.arange(len(months))
width = 0.2
fig, ax = plt.subplots(figsize=(14, 7))
for i, region in enumerate(regions):
ax.bar(x + i * width, region_month_sales[region], width, label=region)
ax.set_xlabel('月份')
ax.set_ylabel('销售额')
ax.set_title('各地区月度销售对比')
ax.set_xticks(x + width)
ax.set_xticklabels(months, rotation=45)
ax.legend()
plt.tight_layout()
plt.show()
4. 销售额分布(直方图 + 箱线图组合)
联合使用直方图与箱线图,全面了解销售额的数据分布形态与异常值情况。
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# 直方图:查看销售额频率分布
ax1.hist(df['sales'], bins=30, color='skyblue', edgecolor='black', alpha=0.7)
ax1.set_title('销售额分布直方图')
ax1.set_xlabel('销售额')
ax1.set_ylabel('频次')
# 箱线图:检测离群点与分布范围
ax2.boxplot(df['sales'], patch_artist=True, boxprops=dict(facecolor='lightcoral'))
ax2.set_title('销售额箱线图')
ax2.set_ylabel('销售额')
plt.tight_layout()
plt.show()
第四步:保存所有图表(可选)
可将生成的图像逐一保存为文件,便于报告撰写或分享。
# 示例:保存折线图
plt.figure(figsize=(12, 6))
plt.plot(monthly_sales['month'], monthly_sales['sales'], marker='o', linewidth=2, color='steelblue')
plt.title('2024年月度销售额趋势', fontsize=16)
plt.xlabel('月份')
plt.ylabel('销售额(元)')
plt.xticks(rotation=45)
plt.grid(True, linestyle='--', alpha=0.6)
plt.tight_layout()
plt.savefig('monthly_sales_trend.png', dpi=300, bbox_inches='tight')
plt.close() # 避免图像重叠显示
项目收获
通过本项目实践,你已掌握以下技能:
- 使用 Pandas 进行时间序列数据处理与聚合
- 利用 Matplotlib 绘制多种常见图表(折线图、饼图、柱状图、直方图、箱线图)
- 合理设置图表样式、标签、网格与布局,提升可视化效果
- 结合多个子图进行复合分析,增强数据洞察力
扩展建议(进阶练习)
- 添加滑动平均线以平滑月度趋势波动
- 按季度重新聚合数据并绘制季节性变化图
- 引入用户行为指标,如客单价、订单量等进行多维分析
- 尝试使用 Seaborn 或 Plotly 实现更高级的交互式可视化
3. 各地区月度销售对比(分组柱状图)
基于数据集中的区域与月份信息,对销售额进行分组聚合处理,并生成各地区按月分布的销售总额矩阵。通过将数据转换为以月份为列、区域为行的透视表形式,实现多区域销售趋势的直观对比。
region_monthly = df.groupby(['region', 'month'])['sales'].sum().unstack(fill_value=0)
region_monthly.columns = region_monthly.columns.astype(str)
region_monthly = region_monthly.reindex(columns=sorted(region_monthly.columns))
x = np.arange(len(region_monthly.columns))
width = 0.2
fig, ax = plt.subplots(figsize=(14, 7))
ax.bar(x - 1.5*width, region_monthly.loc['North'], width, label='North')
ax.bar(x - 0.5*width, region_monthly.loc['South'], width, label='South')
ax.bar(x + 0.5*width, region_monthly.loc['East'], width, label='East')
ax.bar(x + 1.5*width, region_monthly.loc['West'], width, label='West')
ax.set_xlabel('月份')
ax.set_ylabel('销售额(元)')
ax.set_title('各地区月度销售额对比')
ax.set_xticks(x)
ax.set_xticklabels(region_monthly.columns, rotation=45)
ax.legend()
ax.grid(axis='y', linestyle='--', alpha=0.6)
plt.tight_layout()
plt.show()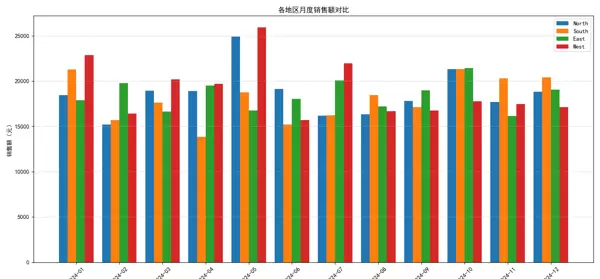
4. 销售额分布分析(直方图与箱线图组合)
采用组合图表方式展示订单金额的整体分布特征:左侧为直方图,反映频次分布;右侧为箱线图,揭示数据离散程度及异常值情况。
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
ax1.hist(df['sales'], bins=30, color='lightcoral', edgecolor='black', alpha=0.7)
ax1.set_title('订单金额分布(直方图)')
ax1.set_xlabel('订单金额(元)')
ax1.set_ylabel('频次')
ax2.boxplot(df['sales'], vert=True, patch_artist=True, boxprops=dict(facecolor='lightgreen'))
ax2.set_title('订单金额分布(箱线图)')
ax2.set_ylabel('订单金额(元)')
ax2.set_xticks([1], ['All Orders'])
plt.tight_layout()
plt.show()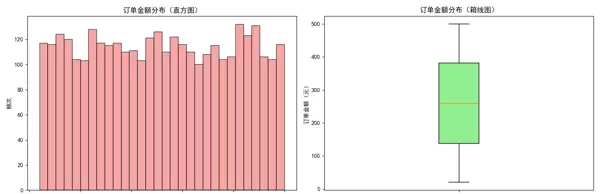
商品类别销售额占比可视化(饼图)
通过绘制饼状图呈现不同商品类别在总销售额中所占比例,突出显示主导品类的贡献度。
plt.title('商品类别销售额占比', fontsize=16)
plt.axis('equal')
plt.show()
图表保存操作(可选步骤)
若需导出生成的可视化结果,可在每次调用 plt.show() 前插入以下代码,用于高分辨率保存图像文件:
plt.savefig('monthly_trend.png', dpi=300, bbox_inches='tight')项目核心技能总结
- 数据分组与聚合:使用 groupby 实现多维度统计分析。
- 时间序列处理:对时间字段进行解析、排序与结构化整理。
- 多种图表绘制能力:涵盖折线图、饼图、分组柱状图、直方图及箱线图等常用可视化类型。
- 图表美化技术:包括标题设置、坐标轴标签优化、网格线添加、颜色搭配、文本旋转与布局调整。
- 子图与多图管理:利用 subplots 进行多面板图形排布控制。
- 中文支持与图像导出:确保中文字体正常显示并支持高质量图像输出。
groupby()sum()pd.date_range.dt.to_periodsubplots()tight_layout()rcParamssavefig()进阶扩展建议
- 增强交互性:引入
或Plotly
实现鼠标悬停显示具体数值功能。mplcursors - 动态图表更新:结合
制作销售增长过程的动画演示。FuncAnimation - 构建可视化仪表盘:集成
或Dash
开发基于 Web 的交互式界面。Streamlit - 替换为真实业务数据:可选用 Kaggle 平台上的 E-commerce Sales Data 数据集进行实战演练。
后续说明
部分 Python 项目的过渡代码已上传至 Gitee 平台,后续将持续更新完善。
以下是一些在机器学习、深度学习及人工智能相关领域中广受认可的技术书籍与参考资料,涵盖了从基础理论到实际应用的多个方面:
《模式识别(第四版)》系统地介绍了模式识别的基本概念与方法,内容涵盖统计模式识别、结构模式识别以及神经网络在识别任务中的应用,适合希望深入理解分类与特征提取机制的读者。
《深度学习 deep learning》(又称“花书”),由伊恩·古德费洛等人撰写,是深度学习领域的权威著作。书中详细阐述了深度神经网络的数学原理、优化方法和典型架构,为研究人员和工程师提供了坚实的理论基础。
《Sklearn与TensorFlow机器学习实用指南》则更侧重于实践操作,通过Scikit-learn和TensorFlow两个主流工具,引导读者构建完整的机器学习项目流程,包括数据预处理、模型训练与评估等环节。
《Python深度学习第二版(中文版)》(Francois Chollet 著)以Keras之父的视角讲解如何使用Python进行深度学习开发,内容清晰易懂,结合大量代码示例,非常适合初学者入门并逐步进阶。
《深入浅出神经网络与深度学习》由迈克尔·尼尔森编写,采用直观的方式解释神经网络的工作机制,强调对反向传播、梯度下降等核心算法的理解,帮助读者建立扎实的直觉认知。
在自然语言处理方向,《自然语言处理综论 第2版》是一部全面且经典的教材,覆盖句法分析、语义表示、信息抽取、机器翻译等多个子领域,被广泛用于高校教学与科研参考。
《Natural-Language-Processing-with-PyTorch》则聚焦于使用PyTorch框架实现NLP任务,介绍词向量、RNN、Transformer等关键技术的实际编码方法,适合希望将理论转化为代码的开发者阅读。
关于计算机视觉,《计算机视觉-算法与应用(中文版)》提供了一个全面的视角,讨论图像处理、特征检测、三维重建等核心技术,并结合真实案例展示其工程价值。
《Learning OpenCV 4》作为OpenCV官方支持的重要学习资料,详细讲解了OpenCV 4版本中的函数用法与视觉算法实现,适用于需要进行实时视觉处理的应用场景。
进入生成式AI时代,《AIGC:智能创作时代》由杜雨与张孜铭合著,探讨了人工智能生成内容的发展趋势及其在文本、图像、音频等领域的创新应用。
《AIGC原理与实践:零基础学大语言模型、扩散模型和多模态模型》则进一步深入技术细节,从零开始讲解大语言模型、扩散模型(Diffusion Models)以及多模态系统的构建逻辑,适合希望掌握前沿生成模型的读者。
《从零构建大语言模型(中文版)》专注于大型语言模型的全流程搭建过程,涵盖数据准备、模型设计、训练策略与推理优化等内容,具有很强的实战指导意义。
《实战AI大模型》强调在真实业务环境中部署大模型的方法与挑战,涉及分布式训练、模型压缩、服务化部署等关键问题,适合从事工业级AI系统开发的技术人员。
最后,《AI 3.0》从宏观角度审视人工智能的发展阶段,提出AI演进的新范式,探讨未来智能系统的可能形态,为读者提供战略层面的思考视角。

 京公网安备 11010802022788号
京公网安备 11010802022788号







