


 雷达卡
雷达卡



三大核心计算机视觉任务解析
此前我们主要聚焦于图像分类模型:给定一张图片,模型输出一个对应的标签。例如,“这张图可能包含一只猫”或“那张图中可能有只狗”。然而,图像分类仅仅是深度学习在计算机视觉领域应用的一部分。实际上,有三项基础且关键的视觉任务值得深入掌握。
图像分类(Image Classification)
该任务的目标是为输入图像分配一个或多个类别标签。它可以分为两类:
- 单标签分类:每幅图像仅归属于一个特定类别;
- 多标签分类:一幅图像可同时属于多个类别。
以谷歌照片为例,当你搜索某个关键词时,后台会调用一个庞大的多标签分类系统,该系统基于超过20,000个类别,并在数百万张图像上进行训练而成,如图9-1所示。
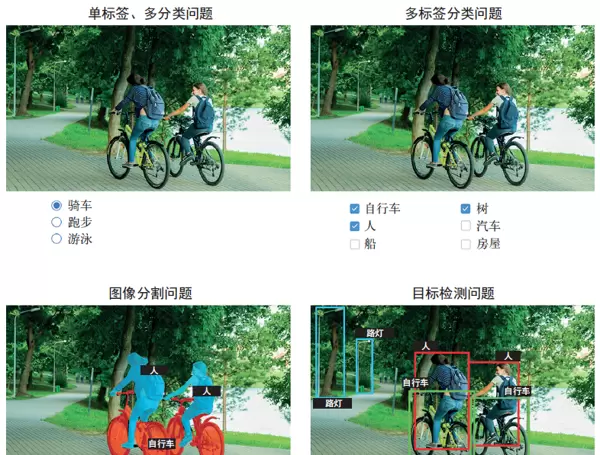
图像分割(Image Segmentation)
这项技术旨在将图像划分为若干区域,每个区域对应一个语义类别,实现像素级别的识别。例如,在视频通话中使用虚拟背景功能,就是通过图像分割模型将人物与背景分离,从而精确保留前景主体。
图像分割广泛应用于医学影像分析、自动驾驶、机器人导航等领域,其核心目标是对图像中的每一个像素进行分类。
目标检测(Object Detection)
目标检测的任务是在图像中定位感兴趣的物体,通常通过绘制矩形框(即边界框)来标出物体位置,并为每个框标注所属类别。例如,自动驾驶车辆利用此类模型实时识别道路上的行人、其他车辆和交通标志。
尽管应用场景丰富,但由于其实现复杂度较高,本书作为入门读物暂不深入讲解目标检测的具体实现。有兴趣的读者可参考Keras官网提供的RetinaNet示例,该项目仅用约450行代码便实现了从零构建并训练一个完整的目标检测模型。
除了上述三大任务外,计算机视觉还包括一些更专业的子任务,如图像相似性评分(判断两张图的视觉接近程度)、关键点检测(如识别人脸特征点)、姿态估计以及三维网格重建等。但无论如何,图像分类、图像分割和目标检测构成了机器学习工程师必须掌握的基础知识体系,绝大多数实际应用均可归结为这三类之一。
深入理解图像分割
第8章已对图像分类进行了实践介绍,接下来我们将重点探讨图像分割技术。这一方法极具实用价值,且可通过已有知识体系直接实现。
基于深度学习的图像分割原理
深度学习驱动的图像分割,本质上是为图像中每一个像素指派一个类别标签,从而将整幅图像划分成多个具有明确语义的区域,例如“道路”、“汽车”、“人行道”或简单的“前景”与“背景”。这种细粒度的处理方式支撑了众多高价值应用,包括智能剪辑、医疗图像分析、自主导航系统等。
你应当熟悉以下两种主要的图像分割形式:
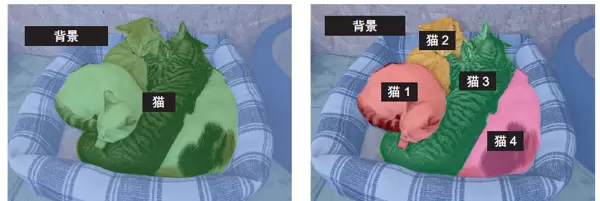
语义分割(Semantic Segmentation)
将每个像素归类到其对应的语义类别中,比如“猫”。如果图像中有两只猫,所有属于猫的像素都会被统一标记为“猫”类别,不会区分个体,如图9-2所示。
实例分割(Instance Segmentation)
不仅按类别分类像素,还能进一步区分开同一类别的不同对象实例。例如,对于两只猫的图像,模型会分别标记为“猫1”和“猫2”,实现个体级别的识别,如图9-2所示。
实战案例:语义分割的应用
本节将以语义分割为重点,结合猫狗图像数据集,演示如何实现前景与背景的分离。我们将采用Oxford-IIIT宠物数据集,其中包含7390张猫狗图像,以及对应的前景-背景分割掩码。
分割掩码(Segmentation Mask)可视作图像分割任务的“标签”。它是一幅与原始图像尺寸完全相同的单通道图像,其中每个像素值代表相应位置的类别归属。在本例中,掩码像素取值如下:
- 1:表示前景
- 2:表示背景
- 3:表示轮廓区域
首先,我们需要下载并解压数据集,过程中将使用shell工具wget和tar完成操作。
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
!wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
!tar -xf images.tar.gz
!tar -xf annotations.tar.gz图像文件以JPG格式存储于images/目录下(如images/Abyssinian_1.jpg),而对应的分割掩码则以同名PNG文件存放于annotations/trimaps/目录中(如annotations/trimaps/Abyssinian_1.png)。
接下来,构建输入图像路径列表及其对应的掩码路径列表:
input_img_paths = sorted(
[os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")])
target_paths = sorted(
[os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")])
import os
input_dir = "images/"
target_dir = "annotations/trimaps/"
input_img_paths = sorted(
[os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")])
target_paths = sorted(
[os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")])这些数据的实际形态如何?我们可以通过可视化手段快速查看。以下代码将展示一张样本图像,效果如图9-3所示。


首先,我们通过代码展示该样本对应的目标,具体结果如图9-4所示。


由于数据集规模较小,所有数据都可以直接加载到内存中。接下来,我们将输入数据和对应的目标分别载入两个NumPy数组,并进一步划分为训练集与验证集。

随后,开始构建模型结构。

调用 model.summary() 后的输出如下:
该模型的前半部分与图像分类任务中常用的卷积神经网络结构类似,均采用多个 Conv2D 层堆叠的形式,且滤波器数量逐步增加。在此过程中,图像经历了三次两倍的下采样操作,最终得到形状为 (25, 25, 256) 的激活特征图。这一阶段的主要作用是将原始图像编码为一个尺寸更小的特征表示,使得每个空间位置(像素点)都蕴含了原图较大范围内的上下文信息,可视为一种空间压缩机制。
然而,与第8章中的分类模型相比,本例在下采样策略上有所不同:之前使用的是 MaxPooling2D 层进行降维处理,而本模型则选择在每隔一个卷积层中使用带有步幅(stride)的卷积操作来实现下采样。(若需回顾卷积步幅的工作原理,可参考第8.1.1节“理解卷积步幅”。)之所以做出这种调整,是因为图像分割任务对空间位置信息高度敏感——最终需要为每一个像素生成对应的类别掩码。而传统的 2×2 最大池化会破坏局部窗口内的精确位置信息,因为它仅输出一个标量值,无法反映该值来自窗口内哪一个具体位置。这在分类任务中影响不大,但在分割任务中会显著降低性能。相比之下,带步幅的卷积能够在有效缩小特征图尺寸的同时,较好地保留空间结构信息。后续章节(例如第12章的生成式模型)也会体现这一原则:当模型依赖于特征的空间定位能力时,通常优先选用步幅卷积而非最大池化。
模型的后半部分由多个 Conv2DTranspose 层堆叠而成。这类层的作用是对特征图进行上采样(upsampling),以恢复至目标输出所需的分辨率。前半部分输出的特征图尺寸为 (25, 25, 256),但我们需要最终输出与目标掩码一致的形状,即 (200, 200, 3)。因此,必须执行一系列逆向变换来还原空间维度。Conv2DTranspose 层正是为此设计的一种可学习的上采样机制,可以看作反向卷积操作。举例来说,若输入形状为 (100, 100, 64),经过一个参数为 Conv2D(128, 3, strides=2, padding="same") 的层后,输出为 (50, 50, 128);再将其送入 Conv2DTranspose(64, 3, strides=2, padding="same") 层,则可恢复为原始输入大小 (100, 100, 64)。因此,在通过多层 Conv2D 将输入压缩至 (25, 25, 256) 后,利用相应的 Conv2DTranspose 层序列即可逐步重建出 (200, 200, 3) 的完整图像。
完成模型定义后,接下来进行编译与训练过程。
model.compile(optimizer="rmsprop", loss="sparse_categorical_crossentropy")
callbacks = [
keras.callbacks.ModelCheckpoint("oxford_segmentation.keras",
save_best_only=True)
]
history = model.fit(train_input_imgs, train_targets,
epochs=50,
callbacks=callbacks,
batch_size=64,
validation_data=(val_input_imgs, val_targets))
我们绘制训练过程中的损失变化情况,包括训练损失和验证损失,结果如图9-5所示。
epochs = range(1, len(history.history["loss"]) + 1)
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.figure()
plt.plot(epochs, loss, "bo", label="Training loss")
plt.plot(epochs, val_loss, "b", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
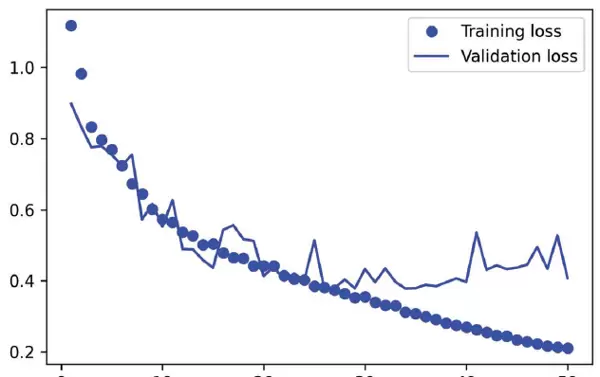
从图9-5可以看出,模型大约从第25个epoch开始出现过拟合现象。因此,我们根据验证损失最小的检查点重新加载最优模型,并演示其在实际样本上的分割预测效果,示例结果如图9-6所示。


尽管预测出的掩码整体表现良好,但仍存在一些细小瑕疵,主要出现在前景与背景交界处的几何结构区域。这些误差可能源于复杂形状边界的模糊性或训练数据本身的标注局限。
到目前为止,系统似乎依然保持良好的运行状态。
在前文的学习中,你已经掌握了图像分类与图像分割的基本概念,并能够利用这些知识开展多种实际任务。
尽管如此,现实中经验丰富的工程师所构建的卷积神经网络远比之前展示的模型复杂得多。他们凭借长期积累的专业直觉,能迅速而准确地设计出高性能的网络结构。这种深层次的思维模式和架构决策能力,正是当前你需要进一步掌握的核心内容。
为了缩小这一差距,深入理解常见的架构模式(architecture pattern)至关重要。接下来,我们将对此展开详细探讨。
以下是完整的实现代码:
import os
import numpy as np
import matplotlib
matplotlib.use('Agg') # 使用非交互式后端
import matplotlib.pyplot as plt
import sys
# 设置TensorFlow日志级别
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
print("开始执行图像分割程序...")
# 检查必要的目录和文件
print("检查数据目录...")
current_dir = os.getcwd()
print(f"当前工作目录: {current_dir}")
# 根据项目规范,使用更可靠的方式定位项目根目录
# 使用当前文件的路径来确定项目根目录,而不是依赖于当前工作目录
script_dir = os.path.dirname(os.path.abspath(__file__))
project_root = os.path.dirname(script_dir)
print(f"脚本目录: {script_dir}")
print(f"项目根目录: {project_root}")
# 准备文件路径 - 使用相对于项目根目录的路径
input_dir = os.path.join(project_root, "images")
target_dir = os.path.join(project_root, "annotations", "trimaps")
print(f"输入图像目录: {input_dir}")
print(f"目标掩码目录: {target_dir}")
# 检查目录是否存在
if not os.path.exists(input_dir):
print(f"错误: 输入目录 {input_dir} 不存在")
print("请确保已下载并解压 Oxford-IIIT Pet Dataset 数据集")
print("数据集下载命令:")
print("wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz")
print("wget http://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz")
print("tar -xf images.tar.gz")
print("tar -xf annotations.tar.gz")
sys.exit(1)
if not os.path.exists(target_dir):
print(f"错误: 目标目录 {target_dir} 不存在")
sys.exit(1)
# 获取文件列表
try:
input_img_paths = sorted([
os.path.join(input_dir, fname)
for fname in os.listdir(input_dir)
if fname.endswith(".jpg")
])
target_paths = sorted([
os.path.join(target_dir, fname)
for fname in os.listdir(target_dir)
if fname.endswith(".png") and not fname.startswith(".")
])
print(f"找到 {len(input_img_paths)} 张输入图像")
print(f"找到 {len(target_paths)} 个目标掩码")
if len(input_img_paths) == 0 or len(target_paths) == 0:
print("错误: 没有找到图像文件")
sys.exit(1)
except Exception as e:
print(f"获取文件列表时出错: {e}")
sys.exit(1)
# 限制处理的图像数量以减少内存使用
max_samples = min(500, len(input_img_paths)) # 进一步减少样本数量
input_img_paths = input_img_paths[:max_samples]
target_paths = target_paths[:max_samples]
# 限制图像处理数量为 max_samples 张,以降低内存消耗
print(f"限制处理图像数量为 {max_samples} 张以减少内存使用")
# 跳过图像可视化步骤,直接进入数据预处理流程
print("跳过图像显示,直接进入数据处理...")
# 延迟导入 TensorFlow 相关模块,防止潜在的依赖冲突
try:
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.utils import load_img
print("TensorFlow模块导入成功")
except ImportError as e:
print(f"导入TensorFlow模块时出错: {e}")
sys.exit(1)
# 简化版图像加载与预处理函数
def load_images_simple(input_img_paths, target_paths, size=(128, 128)):
"""
加载输入图像和对应标签掩码,并进行标准化处理
使用较小尺寸以节省资源
"""
print(f"开始加载 {len(input_img_paths)} 张图像...")
input_imgs = []
targets = []
for i in range(len(input_img_paths)):
if i % 50 == 0:
print(f"已加载 {i}/{len(input_img_paths)} 张图像")
try:
# 读取原始图像并调整大小,转换为归一化的数组
img = load_img(input_img_paths[i], target_size=size)
img_array = np.array(img, dtype="float32") / 255.0
# 加载目标分割掩码(灰度模式)
mask = load_img(target_paths[i], target_size=size, color_mode="grayscale")
mask_array = np.array(mask, dtype="uint8")
# 标签值调整:适用于 Oxford-IIIT Pet 数据集
# 将原始标签 1,2,3 映射为 0,1,2;并将边界像素(255)归为类别2
mask_array = mask_array - 1
mask_array[mask_array == 255] = 2
mask_array = np.expand_dims(mask_array, 2) # 添加通道维度
input_imgs.append(img_array)
targets.append(mask_array)
except Exception as e:
print(f"跳过图像 {input_img_paths[i]}: {e}")
continue
print(f"成功加载 {len(input_imgs)} 张图像")
return np.array(input_imgs), np.array(targets)
# 执行图像加载操作
try:
input_imgs, targets = load_images_simple(input_img_paths, target_paths, size=(128, 128))
if len(input_imgs) == 0:
print("错误: 没有成功加载任何图像")
sys.exit(1)
except Exception as e:
print(f"加载图像时出错: {e}")
sys.exit(1)
# 划分训练集与验证集
# 验证样本数取总量的五分之一或最多100张
num_val_samples = min(100, len(input_imgs) // 5)
train_input_imgs = input_imgs[:-num_val_samples]
train_targets = targets[:-num_val_samples]
val_input_imgs = input_imgs[-num_val_samples:]
val_targets = targets[-num_val_samples:]
print(f"训练集大小: {len(train_input_imgs)}")
print(f"验证集大小: {len(val_input_imgs)}")
# 构建轻量级语义分割模型
def get_simple_model(img_size, num_classes):
print("正在构建简化模型...")
inputs = keras.Input(shape=img_size + (3,))
# 编码阶段:特征提取
x = layers.Conv2D(32, 3, activation='relu', padding='same')(inputs)
x = layers.MaxPooling2D(2)(x)
# 构建简化模型的结构
x = layers.Conv2D(64, 3, activation='relu', padding='same')(x)
x = layers.MaxPooling2D(2)(x)
# 解码器部分开始上采样恢复空间分辨率
x = layers.Conv2DTranspose(64, 3, activation='relu', padding='same')(x)
x = layers.UpSampling2D(2)(x)
x = layers.Conv2DTranspose(32, 3, activation='relu', padding='same')(x)
x = layers.UpSampling2D(2)(x)
# 输出层生成最终的分类结果
outputs = layers.Conv2D(num_classes, 1, activation='softmax')(x)
model = keras.Model(inputs, outputs)
print("简化模型构建完成")
return model
# 初始化模型实例
model = get_simple_model(img_size=(128, 128), num_classes=3)
model.summary()
# 配置训练参数:编译模型
print("正在编译模型...")
model.compile(
optimizer="adam", # 使用自适应矩估计优化器,收敛更稳定
loss="sparse_categorical_crossentropy",
metrics=['accuracy']
)
# 确保标签数据为整型格式
train_targets = train_targets.astype(np.int32)
val_targets = val_targets.astype(np.int32)
# 定义训练过程中的回调机制
callbacks = [
keras.callbacks.ModelCheckpoint(
"simple_oxford_segmentation.keras",
save_best_only=True
),
keras.callbacks.EarlyStopping(patience=3) # 当性能不再提升时提前终止训练
]
# 开始模型训练流程
print("开始训练模型...")
try:
history = model.fit(
train_input_imgs, train_targets,
epochs=5, # 设定较小的训练轮数用于快速验证
callbacks=callbacks,
batch_size=8, # 减小批量大小以适应显存限制
validation_data=(val_input_imgs, val_targets),
verbose=1
)
print("模型训练完成")
# 可视化训练过程:绘制损失曲线
if len(history.history["loss"]) > 0:
epochs = range(1, len(history.history["loss"]) + 1)
loss = history.history["loss"]
val_loss = history.history["val_loss"]
plt.figure()
plt.plot(epochs, loss, "bo-", label="Training loss")
plt.plot(epochs, val_loss, "ro-", label="Validation loss")
plt.title("Training and validation loss")
plt.legend()
plt.savefig('simple_training_loss.png', dpi=150, bbox_inches='tight')
plt.close()
print("训练损失图表已保存为 simple_training_loss.png")
# 执行预测任务
print("进行预测...")
if os.path.exists("simple_oxford_segmentation.keras"):
model = keras.models.load_model("simple_oxford_segmentation.keras")
# 在验证集中选取样本进行测试
test_idx = min(5, len(val_input_imgs) - 1)
test_image = val_input_imgs[test_idx]
# 模型推理并获取预测掩码
mask_pred = model.predict(np.expand_dims(test_image, 0), verbose=0)[0]
predicted_mask = np.argmax(mask_pred, axis=-1)
# 生成可视化结果图像
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# 显示原始图像
axes[0].imshow(test_image)
axes[0].set_title("Test Image")
axes[0].axis('off')
# 展示预测得到的掩码结果
axes[1].imshow(predicted_mask, cmap='viridis')
axes[1].set_title("Predicted Mask")
axes[1].axis('off')
# 对比真实标签中的掩码图像
axes[2].imshow(val_targets[test_idx][:, :, 0], cmap='viridis')
axes[2].set_title("Ground Truth")
axes[2].axis('off')
plt.tight_layout()
plt.savefig('simple_prediction_result.png', dpi=150, bbox_inches='tight')
plt.close()
print("预测结果图表已保存为 simple_prediction_result.png")
print("程序执行成功完成!")
except Exception as e:
print(f"训练过程中发生错误: {e}")
import traceback
traceback.print_exc()
print("程序执行遇到问题,但已尽力完成")

 京公网安备 11010802022788号
京公网安备 11010802022788号







