


 雷达卡
雷达卡




一、研究背景:开源与闭源模型之间的差距持续扩大
近期,人工智能领域呈现出一个显著趋势:尽管开源社区在技术探索和模型迭代方面不断取得进展,但以GPT-5、Gemini-3.0-Pro为代表的闭源模型在性能提升速度上明显领先。这表明,开源与闭源之间的技术鸿沟并未缩小,反而正在进一步拉大。
DeepSeek团队经过深入分析,识别出当前开源大模型面临的三大核心瓶颈:
- 架构效率受限:传统注意力机制在处理长序列时计算开销巨大,严重制约了模型的训练效率与实际部署能力。
- 后训练资源投入不足:多数开源模型在预训练完成后,缺乏足够的计算资源进行高质量的后训练优化。
- 智能体能力薄弱:在AI Agent等复杂应用场景中,开源模型在指令遵循、环境泛化及工具调用等方面表现落后于主流闭源系统。
核心突破概述
为应对上述挑战,DeepSeek-V3.2实现了三项关键技术革新:
- DeepSeek Sparse Attention (DSA):提出一种高效稀疏注意力机制,将原始的O(L)计算复杂度降低至O(Lk),在显著减少计算负担的同时保持对长文本的强大建模能力。
- 可扩展的强化学习框架:在后训练阶段投入超过预训练成本10%的计算预算,采用先进的GRPO算法实现稳定高效的策略优化,使模型性能达到GPT-5级别。
- 大规模智能体任务合成管线:构建包含1,800+虚拟环境和85,000+复杂提示的任务体系,全面增强模型的工具使用与多步推理能力。
尤为引人注目的是,高算力版本DeepSeek-V3.2-Speciale在2025年国际数学奥林匹克(IMO)与国际信息学奥林匹克(IOI)中均斩获金牌水平成绩,整体表现与Gemini-3.0-Pro相当。
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2
ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2DeepSeek-V3.2-Speciale
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
ModelScope:https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale二、相关工作综述
推理模型的发展里程碑
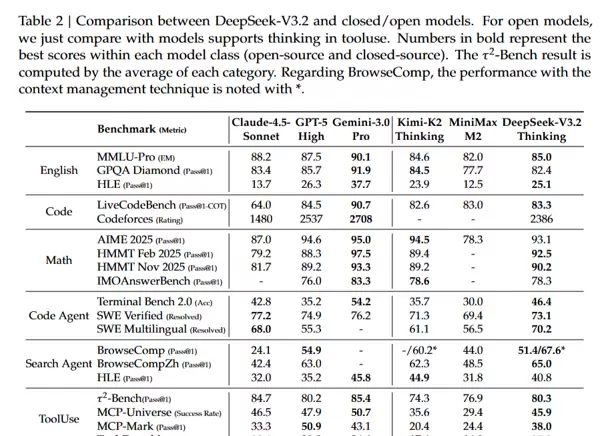
近年来,推理专用模型如DeepSeek-R1与OpenAI o1的发布,标志着大语言模型在可验证推理任务上的重大突破。然而,闭源体系(如Anthropic Claude、Google Gemini、OpenAI GPT系列)的技术演进节奏远超开源阵营(如MiniMax、MoonShot、ZhiPu-AI等),形成了明显的代际差距。
注意力机制的演进路径
标准全注意力结构(Vanilla Attention)在长序列建模中面临严重的效率瓶颈。虽然已有多种稀疏注意力方案尝试解决该问题,但DeepSeek-V3.2所提出的DSA机制通过引入闪电索引器(Lightning Indexer)与细粒度token选择策略,实现了更优的性能-效率权衡,在保持精度的前提下大幅提升吞吐能力。
后训练中的强化学习应用现状
目前大多数开源模型在后训练阶段对强化学习的应用仍处于初级阶段,训练强度和稳定性均不足。DeepSeek-V3.2则基于GRPO(Group Relative Policy Optimization)框架,结合无偏KL估计、离策略序列掩码等技术创新,成功实现了大规模、高收敛性的强化学习训练流程。
三、核心技术详解
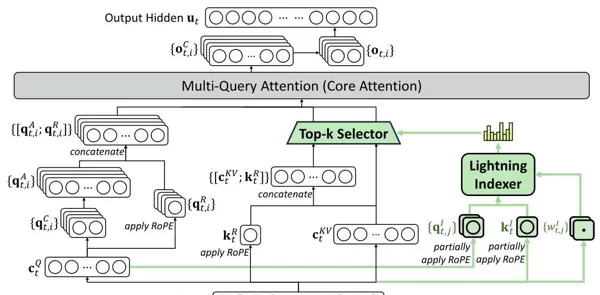
3.1 DeepSeek Sparse Attention (DSA)
DSA作为DeepSeek-V3.2的核心架构创新,由以下两个关键模块构成:
(1)闪电索引器(Lightning Indexer)
该组件负责从历史序列中筛选关键信息。对于当前查询token ht 与前序token hs,索引器计算其关联分数:
It,s = ∑j=1HI wt,jI ReLU(qt,jI ksI)
其中 HI 表示索引头数量,ReLU激活函数被用于提升计算吞吐率。索引器运行于FP8低精度模式,具备极高的执行效率。
(2)细粒度Token选择机制
基于上述索引分数,系统仅保留top-k个最具相关性的key-value对,并在此基础上完成注意力输出计算:
ut = Attn(ht, { cs | It,s ∈ Top-k(It,: ) })
持续预训练策略
DSA的训练过程分为两个阶段:
密集预热阶段:冻结主干网络参数,单独训练索引器约1000步(覆盖21亿tokens),利用KL散度最小化目标,使索引器输出分布逼近原始注意力分布:
LI = ∑t DKL(pt,: ∥ Softmax(It,: ))
该策略有效保障了稀疏结构在早期训练中的稳定性与收敛性。
新模型技术报告已同步发布:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolve/master/assets/paper.pdf
稀疏训练阶段通过引入 token 选择机制实现高效学习,共训练 15000 步,累计处理 9437 亿 tokens。训练过程中采用的学习率为 \(7.3 \times 10^{-6}\),每个查询任务中固定选择 2048 个 key-value tokens 进行处理。
目标函数定义如下:
\[ \mathcal{L}^I = \sum_t \mathbb{D}_{\text{KL}}(p_{t,:} \parallel \text{Softmax}(I_{t,:})) \]3.2 可扩展的强化学习框架
DeepSeek-V3.2 采用了 GRPO 算法,并结合多项技术创新以提升训练稳定性与效率:
(1)无偏 KL 估计
传统 K3 估计器在策略分布 \(\pi_\theta \ll \pi_{\text{ref}}\) 的情况下容易产生有偏梯度。为此,新方法引入重要性采样比进行修正,其 KL 散度计算形式为:
(2)离策略序列掩码(Off-Policy Sequence Masking)
为控制策略更新的稳定性,对具有负优势且策略偏离过大的样本实施掩码处理。具体阈值由超参数 \(\delta\) 控制,掩码规则如下:
(3)保持路由(Keep Routing)
针对 MoE 架构,在训练阶段强制沿用推理时的专家路由路径,确保模型在相同参数子空间内优化,防止因路由变化引发的训练不稳定性。
(4)保持采样掩码(Keep Sampling Mask)
在 top-p 或 top-k 采样过程中保留原始截断掩码,使新旧策略在一致的动作子空间中进行比较和更新,增强策略演进的一致性。
3.3 工具使用中的思考链整合
(1)思考上下文管理
为适配工具调用场景,设计了精细化的上下文管理机制:
- 仅当接收到新的用户消息时,才清除历史推理内容;
- 若仅是追加工具执行结果,则完整保留原有推理轨迹;
- 所有工具调用的历史记录均被持续保留,支持多步推理连贯性。
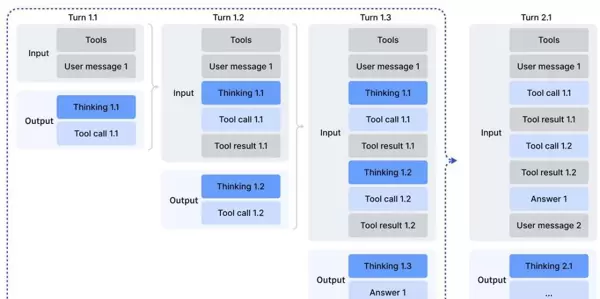
(2)冷启动机制
通过精心构造的提示词模板,将模型的推理能力与工具调用能力自然融合。根据不同任务类型配置专属系统提示词,引导模型在单次交互中完成多次工具调用(详见附录表6-8)。
(3)大规模智能体任务合成
构建了四类典型智能体任务,用于训练和评估模型的综合能力:
| 任务类型 | 任务数量 | 环境类型 | 提示词来源 |
|---|---|---|---|
| 代码智能体 | 24,667 | 真实 | 提取 |
| 搜索智能体 | 50,275 | 真实 | 合成 |
| 通用智能体 | 4,417 | 合成 | 合成 |
| 代码解释器 | 5,908 | 真实 | 提取 |
上述任务覆盖多样化的应用场景,其中“通用智能体”示例展示了复杂任务下的多步推理与工具协同能力。
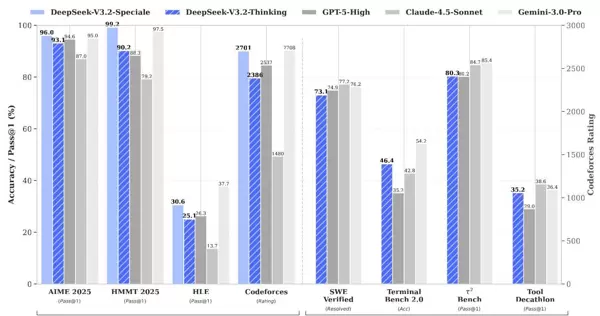
四、实验效果
4.1 核心基准测试表现
在涵盖推理、代码、数学及智能体能力的32项基准测试中,DeepSeek-V3.2展现出与GPT-5相当的整体性能:
推理能力
- MMLU-Pro: 85.0(GPT-5: 87.5)
- GPQA Diamond: 82.4(GPT-5: 85.7)
- HLE文本题: 25.1(GPT-5: 26.3)
编程能力
- LiveCodeBench: 83.3(GPT-5: 84.5)
- Codeforces评分: 2386(GPT-5: 2537)
数学任务
- AIME 2025: 93.1%(GPT-5: 94.6%)
- HMMT Feb 2025: 92.5%(GPT-5: 88.3%)
- HMMT Nov 2025: 90.2%(GPT-5: 89.2%)
代码智能体
- SWE-Verified解决率: 73.1%(优于多数开源模型)
- Terminal Bench 2.0: 46.4%(当前开源最佳)
搜索智能体
- BrowseComp: 从无上下文管理时的51.4%提升至有管理时的67.6%
- BrowseCompZh: 达到65.0%
工具调用能力
- τ?-Bench: 80.3(显著领先其他开源模型)
- MCP-Universe成功率: 45.9%
- Tool-Decathlon: 35.2
4.2 DeepSeek-V3.2-Speciale:竞赛金牌突破
通过放宽长度限制并增加计算资源,Speciale版本在多项顶级赛事中达到金牌水平:
| 竞赛 | 成绩 | 奖牌等级 |
|---|---|---|
| IMO 2025 | 35/42 | 金牌 |
| CMO 2025 | 102/126 | 金牌 |
| IOI 2025 | 492/600(第10名) | 金牌 |
| ICPC World Final 2025 | 10/12(第2名) | 金牌 |
在部分指标上,Speciale甚至超越Gemini-3.0-Pro:
- HMMT Feb 2025: 99.2% vs 97.5%
- LiveCodeBench: 88.7% vs 90.7%
- Codeforces: 2701 vs 2708
然而,其token使用效率较低。例如在AIME任务中,Speciale需23k tokens,而Gemini仅需15k。
![表3:推理模型性能与效率对比]4.4 上下文管理的有效性
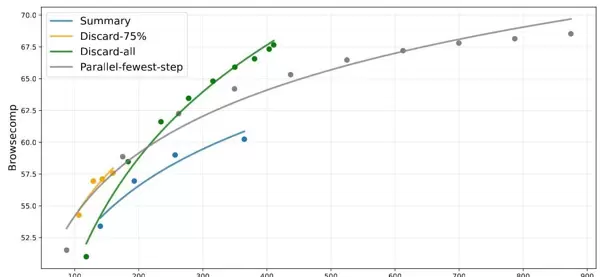
针对搜索智能体常超出128K上下文的问题,提出了三种应对策略:
- Summary:对溢出轨迹进行总结后重启
- Discard-75%:舍弃前75%的工具调用记录
- Discard-all:完全重置上下文(类似Anthropic的new context机制)
实验表明,最简单的Discard-all策略即可将BrowseComp性能从53.4%提升至67.6%,效果接近并行扩展方法,但所需步数更少。
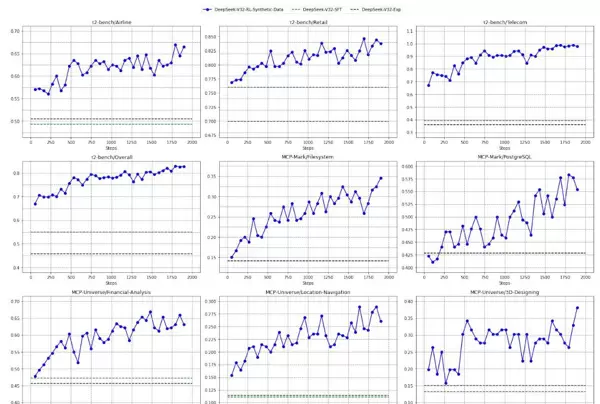
4.3 合成任务的挑战性与泛化验证
为评估合成数据质量,随机抽取50个由自动环境合成智能体生成的任务进行测试,该智能体共创建了1,827个面向任务导向的环境(如旅行规划),这类任务具有大组合空间、复杂约束但易于验证的特点。
测试结果如下:
- DeepSeek-V3.2-Exp: 12% Pass@1
- Claude-4.5-Sonnet: 34% Pass@1
- GPT-5: 62% Pass@1
结果显示,这些合成任务具备真实挑战性。进一步地,在仅使用合成任务进行强化学习训练的情况下,模型在真实基准测试中仍表现出显著性能提升,证明其具备良好泛化能力。
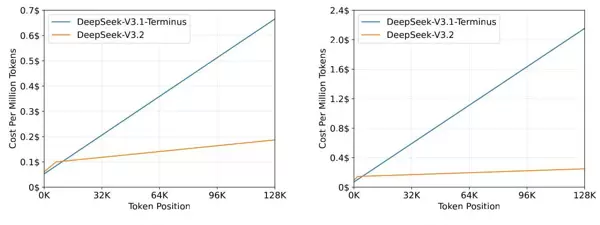
4.5 推理成本效率分析
DSA架构显著降低了长文本推理的成本。在H800集群(租赁价2美元/GPU小时)上的测试显示,随着token位置增长,DeepSeek-V3.2的成本上升速度远低于V3.1-Terminus。
五、论文总结:开源追赶闭源的新范式
DeepSeek-V3.2的成果揭示了开源模型实现突破的关键路径:
- 架构效率决定竞争力:DSA证明稀疏注意力可在不牺牲性能的前提下大幅提升效率。
- 后训练投入值得扩大:即使仅增加10%的训练预算,也可能带来质的飞跃,且仍有扩展潜力。
- 合成数据潜力巨大:精心设计的合成任务能有效驱动智能体能力进化。
- 测试阶段计算不可忽视:上下文管理等运行时策略可显著增强实际表现。
这项工作不仅缩小了开源与闭源模型之间的性能差距,更重要的是为社区提供了一条清晰可行的发展路线:通过架构创新控制成本,通过加大后训练投入提升能力,借助数据合成突破瓶颈。DeepSeek-V3.2证明,开源大模型完全有能力在保持成本优势的同时,达到与顶尖闭源模型相匹敌的性能水平。

 京公网安备 11010802022788号
京公网安备 11010802022788号







