


 雷达卡
雷达卡



1. 生成模型的选择与部署策略
1.1 主流生成模型概览
GPT系列(OpenAI):作为大模型发展的引领者,GPT在多项能力上表现卓越,尤其在逻辑推理和指令遵循方面具备明显优势,持续推动技术创新。
Claude 系列(Anthropic):以长上下文处理见长,支持高达200K token的输入,在安全性和低幻觉率方面表现出色,数学与编程测评中已显现出超越GPT的潜力。
Gemini系列(Google):虽未如前两者般广泛瞩目,但其采用统一多模态架构,支持超长文本输入,并在代码生成与推理任务中进行了专项优化。
DeepSeek-V3/R1(深度求索):国产大模型中的代表之作,基于MoE架构设计,重点强化了数学解题与编程能力,支持128K上下文长度。其中R1版本开源且可商用,还推出了基于纯强化学习的推理模型及轻量级蒸馏版,便于部署。
Llama 系列(Meta):开源模型典范,参数范围覆盖8B至70B,以高推理效率和长上下文支持著称,配套工具生态丰富。
Qwen(阿里云):针对中文场景深度优化,提供从1.8B到72B多种尺寸,支持多轮对话与插件扩展,适用于复杂交互任务。
Mixtral 家族(Mistral):采用MoE结构,通过少量激活参数实现高性能输出,兼具开源属性与商业可用性。
豆包 Seed 系列(字节跳动):中文理解能力强,Seed-1.6 Pro支持256K超长文本解析,对30万字合同的解析准确率达91.2%,中文幻觉率仅为4%。具备优秀的多模态生成能力,支持亿级并发,适用于日常对话与长文本处理等通用场景。
文心一言(百度):百度核心大模型,4.5版本在办公自动化领域表现突出,擅长PPT全流程生成,涵盖排版、图表与动画制作,10分钟内可完成30页专业文档,同时在中文语义理解与通用问答中保持稳定输出。
GLM 系列(智谱 AI):以GLM-4.5V为代表,不仅具备良好的通用对话能力,还在3D几何推理与物理公式推导方面有所突破,借助3D-RoPE技术,兼顾STEM学科复杂需求与常规应用场景。
MiniMax Abab 系列(MiniMax):整体能力均衡,Abab6在WPS协同办公场景中适配良好,能高效完成Excel数据透视表构建、Word论文格式调整等任务,也胜任一般性文本生成与问答。
Grok(xAI):风格活泼,具备实时信息获取能力,其编程专用变体表现亮眼;基础版本在逻辑对话与观点表达中展现出独特个性,适合追求差异化人机互动的使用场景。
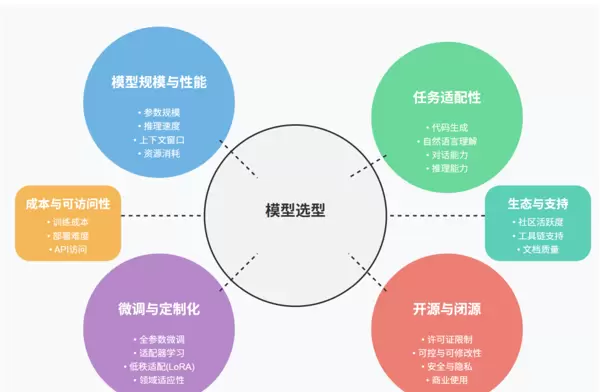
1.2 模型选型关键维度
- 开源与否:决定是否可进行本地化部署与二次开发
- 模型规模与性能:影响响应速度、推理精度与资源消耗
- 任务匹配度:需结合具体应用场景选择最适配的模型
- 微调与定制能力:评估是否支持个性化训练与功能拓展
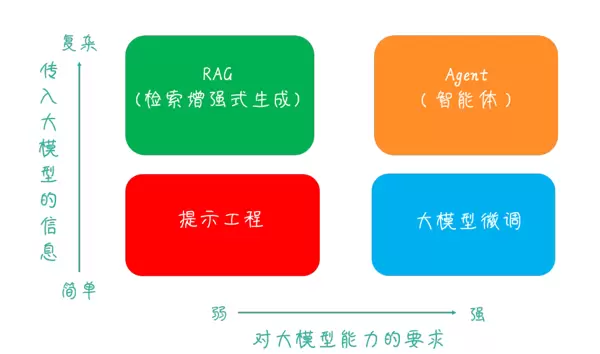
1.3 大模型应用的四大象限划分
信息复杂度越高,对模型能力的要求越强,相应技术门槛与应用价值也随之提升。从“提示工程”向“Agent”演进,体现了大模型应用由“指令优化”迈向“自主决策智能体”的发展路径。
1.4 不同场景下的模型适配建议


1.5 大模型推理模式解析
1.6 模型选型综合建议

2. 提升模型响应质量的有效手段:提示工程
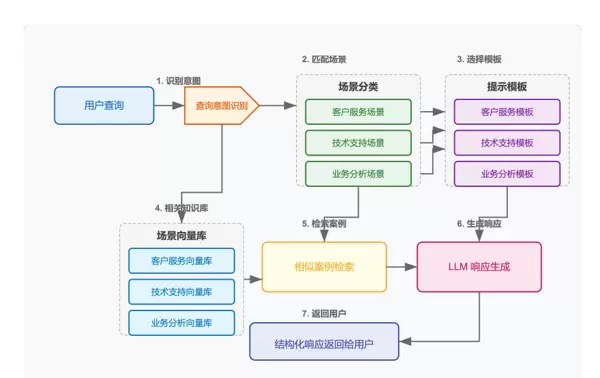
提示工程是一种低成本、高效益的方法,通过精心设计提示词来激发大模型潜能,无需进行模型微调,仅依靠优化输入指令的结构、内容与逻辑,即可显著提升输出的准确性、完整性与实用性。
2.1 构建标准化模板:明确响应边界
核心思想:利用固定结构的模板清晰定义“任务目标、输出形式、限制条件”,防止模型输出偏离预期,同时降低沟通成本。一个有效的模板应包含以下三大要素:
| 模板要素 | 作用说明 |
|---|---|
| 任务描述 | 明确“需要做什么”,例如总结、翻译或分析 |
| 输出格式 | 规定“如何呈现结果”,如分条列出、表格展示或JSON格式 |
| 约束条件 | 设定“禁止行为”,如避免口语化表达、控制字数不超过30字等 |
实际案例对比
无模板时的低质响应:这款耳机降噪效果不错,续航有30小时,蓝牙连接快,佩戴舒适。
使用模板后的优质响应:
- 40dB深度降噪,环境更安静
- 续航长达30小时,外出无需频繁充电
- 半入耳式设计,长时间佩戴不压迫耳朵
【任务】总结以下产品的核心卖点
【输出格式】分3点,每点不超过20字
【约束】避免专业术语
产品:XX无线耳机,降噪深度40dB,续航30小时,支持蓝牙5.3,半入耳设计更舒适2.2 利用Few-Shot示例:通过示范减少理解偏差
核心原理:大模型善于模仿学习。在提示中加入1~3组“输入-输出”示例(即Few-Shot Learning),有助于模型快速掌握任务细节,尤其适用于主观性强或定义模糊的任务(如“幽默表达”)。
示例设计准则
- 示例必须贴近目标应用场景
- 需体现关键要求,如“简洁”“口语化”“带表情符号”等特征
实战案例:抖音文案润色
【任务】把产品功能点润色成抖音风格文案,要求口语化、带情绪
【示例】
功能点:续航24小时
润色后:这续航直接焊在我耳朵上!24小时连播,通勤+摸鱼+健身全搞定,再也不用揣着充电宝找充电仓!
【你的功能点】降噪深度40dB模型输出:这降噪简直是“与世隔绝开关”!40dB深度buff叠满,地铁里听歌就像在私人包厢,同事聊八卦?我耳机里只有爱豆的歌单~
2.3 提升生成内容的全面性:通过“多维度引导”消除信息盲区
核心逻辑:
大模型在默认情况下倾向于简化输出,容易忽略部分关键视角。通过在提示词中明确指定需要覆盖的分析维度(例如:“从用户、商家、成本三个角度展开分析”),可以强制模型切换至多视角思维模式,从而有效避免信息遗漏。
实施方法:
- 列出分析维度清单:在提示中直接设定必须涵盖的角度,如社会、经济、技术等;
- 反向追问机制:加入类似“还有哪些方面未被提及?”的问题,促使模型自我补充缺失内容。
应用实例:奶茶店促销策略分析
对消费者而言:降低单次消费的心理门槛,适合多人拼单,提升性价比感知,激发即时购买行为;
对商家而言:虽然单杯利润下降约50%,但销量可能增长1.5倍,整体利润反而上升,同时带动附加商品销售,提高客单价;
对库存管理而言:需提前储备热销口味原材料,防止因订单激增导致断货风险。
分析“奶茶店第二杯半价”活动的影响,要求覆盖:
1. 对消费者的吸引力
2. 对商家的利润影响
3. 对库存的压力2.4 构建事实核查流程:利用“自我校验”抑制幻觉输出
核心逻辑:
大模型存在虚构信息(即“幻觉”)的风险。若在提示中设计“先作答、再验证”的步骤,要求模型主动检查其回答的真实性(例如判断数据是否有可靠来源),可显著减少错误信息的产生。
核查机制的提示结构示例:
【任务】回答“2024年全球智能手机销量第一的品牌”
【步骤1】先给出答案
【步骤2】核查:
- 数据是否有公开来源(如IDC、Canalys报告)
- 时间是否匹配2024年
【步骤3】若核查不通过,说明“信息待确认”模型响应实录:
- 初步结论:2024年全球智能手机销量排名第一的品牌是三星;
- 核查过程:
- 数据来源:Canalys发布的《2024年第四季度全球智能手机市场报告》显示,三星以21.8%的市场份额位列榜首;
- 时间范围:该统计数据涵盖整个2024年度;
- 最终判定:信息真实有效,具备权威出处。
3. 利用输出解析技术控制响应格式
3.1 LangChain中的OutputParser组件
- StrOutputParser:基础文本解析器,原样返回模型生成的字符串结果;
- JSONOutputParser:确保输出为合法JSON格式,适用于需要结构化数据的场景;
- PydanticOutputParser:基于Pydantic模型进行解析,支持复杂嵌套结构的数据提取;
- RegexParser:使用正则表达式匹配并抽取特定字段内容;
- StructuredOutputParser:依据预定义的JSON Schema进行严格结构化解析。
3.2 LlamaIndex的输出处理机制
LlamaIndex主要通过两个模块实现输出控制:响应合成(response synthesization)与结构化输出解析(structured output parsing)。
在完成检索操作后,系统首先调用retriever获取相关文档片段,随后由response_synthesizer模块整合这些信息,并借助大语言模型生成最终答复。这一过程强调信息召回与逻辑重组的协同作用。
3.3 JSON模式与结构化输出机制
OpenAI提供的传统JSON模式允许设置response_format={ "type": "json_object" }来启用JSON输出限制。启用后,模型仅生成符合JSON语法的字符串内容。然而,此模式仅保证格式正确,无法确保字段名称、类型或枚举值的准确性。
而在最新的Responses API中引入的结构化输出(Structured Outputs)功能,则能强制模型严格按照用户提供的JSON Schema生成响应,确保必填字段不被省略、枚举值合法、数据类型一致。对于能力较弱的模型,仍需配合强约束性提示词以保障效果。
3.4 基于Pydantic的对象解析
Pydantic提供了一套灵活框架,可用于将非结构化文本转换为结构化的Python对象。LlamaIndex在此基础上封装了多种Pydantic程序类型,适配不同应用场景:
- 大模型文本完成Pydantic程序(LLM Text Completion Pydantic Programs):结合文本生成功能和解析逻辑,将输入转化为自定义结构化对象;
- 大模型函数调用Pydantic程序(LLM Function Calling Pydantic Programs):依赖函数调用API,将自然语言请求映射为特定结构化输出;
- 预设的Pydantic程序(Prepackaged Pydantic Programs):面向常见任务提供标准化模板,快速实现文本到结构化数据的转化。
3.5 Function Calling 输出解析
通过Function Calling或Tool Calling机制,可让大模型返回结构化数据。系统会解析返回结果中的function_call字段,动态提取后续应调用的函数名及参数列表,实现流程自动化与决策链延伸。
4. 实现动态优化的生成策略(主动构建)
4.1 Self-RAG:具备自我反思能力的生成架构
Self-RAG(Self-Retrieval-Augmented Generation,自我增强式生成)是在传统RAG(Retrieval-Augmented Generation)基础上发展而来的进阶方法。它不仅从外部知识库中检索信息辅助生成,还引入了“反思-评估”机制,使模型能在输出过程中自主判断内容质量,并决定是否需要重新检索或修正结论,从而提升答案的准确性和完整性。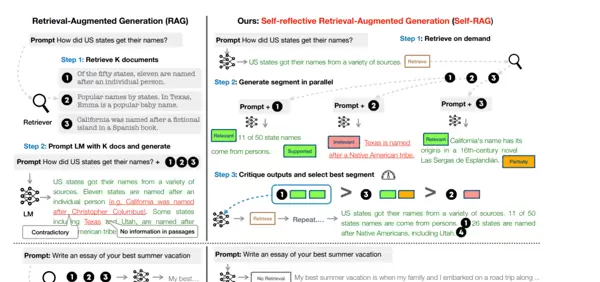
通过大模型的“自主推理能力”,Self-RAG 将检索决策、信息校验与内容修正等环节深度整合至生成流程中,无需人工介入或多模块协同,仅依赖单一模型即可实现从需求分析到结果优化的完整闭环。该机制有效缓解了传统 RAG 中常见的检索冗余、信息失准及幻觉生成等问题,显著提升生成内容的准确性与自治性。
检索需求:2025年中国新能源汽车渗透率
核心关键词:2025年 中国 新能源汽车 渗透率
数据要求:
1. 权威来源:中国汽车工业协会(CAAM)、乘联会(CPCA)2024-2025年发布的官方数据/报告;
2. 包含信息:新能源汽车年度销量、汽车总销量、渗透率具体数值(保留1位小数);
3. 排除信息:非中国地区数据、预测年份早于2025年的报告。4.1.2 核心工作原理
Self-RAG 的本质在于“大模型”与“检索器”的深度融合,借助“反思提示词”引导模型完成多轮推理和动态决策,主要依托以下两大核心机制:
决策机制:模型根据问题类型及其自身知识边界,自主判断是否需要发起检索、应检索哪些关键词或范围,并决定是否需进行二次检索。
校验机制:对返回的检索结果进行相关性、权威性和完整性评估;同时,在生成过程中对输出内容的事实准确性和逻辑连贯性进行自我修正。
4.1.1 核心定位与技术价值
传统 RAG 遵循“模型触发→检索返回→内容生成”的线性流程,存在明显缺陷:面对常识性问题仍盲目发起请求、因指令模糊导致检索结果杂乱、未加验证直接使用信息引发幻觉。而 Self-RAG 引入“自我反思”机制,赋予模型自主决策能力,其核心优势体现在以下几个方面:
检索自治化:能够自主判断是否检索、检索目标及是否重试,大幅减少无效操作。
信息精准化:通过多轮自我校验过滤无关或错误信息,显著降低幻觉发生概率。
流程简化化:无需额外部署校验模块或指令优化组件,全流程由单一模型独立完成。
结果优质化:最终输出兼具事实准确性与逻辑完整性,避免后续人工干预。
4.1.3 完整执行步骤(以“回答2025年中国新能源汽车渗透率”为例)
整个 Self-RAG 流程由模型自主驱动,包含五个关键阶段,每个阶段均嵌入“自我反思”环节,确保每一步操作合理可靠。
4.1.3.1 步骤1:问题分析与检索决策(反思“要不要检索”)
模型首先基于“问题类型 + 知识时效性 + 自身认知边界”进行综合推理,判断是否需要外部数据支持。
推理过程示例:“用户询问‘2025年中国新能源汽车渗透率’,属于未来预测类事实问题,超出训练数据时间范围,且需依赖权威统计口径,无法凭现有知识作答 → 必须检索。”
决策输出:确认“需要检索”,并初步锁定检索方向,如2025年中国新能源汽车销量、总体汽车销量以及渗透率计算方法。
例外情况:若问题为常识性知识(如“新能源汽车的动力来源”)或已有明确掌握的数据(如“2023年渗透率为31.6%”),则判定“无需检索”,直接进入生成阶段。
4.1.3.2 步骤2:检索指令生成(反思“检索什么”)
当确定需要检索后,模型不会仅输出简单关键词,而是生成结构化的检索指令,明确所需信息的具体维度。
生成逻辑:围绕问题核心需求,补充数据来源、时间范围、格式要求等约束条件,防止获取无效或泛化结果。
示例指令:“查询中国汽车工业协会(CAAM)或乘联会(CPCA)发布的2025年度新能源汽车销量预测报告,需包含新能源车销量、总销量数据,并提供官方链接或发布日期。”
4.1.3.3 步骤3:检索结果校验(反思“信息能用吗”)
在接收到检索结果后,模型将自动从多个维度进行评估,判断其是否符合原始指令要求。若不满足,则优化指令并重新发起请求。
假设结果:“乘联会2025年1月预测报告显示,2025年中国新能源汽车销量预计达1300万辆,汽车总销量预计达3800万辆,渗透率约34.2%。”
校验流程:
- 来源校验:乘联会(CPCA)为行业权威机构,可信度高;
- 时间校验:报告发布于2025年1月,针对同年预测,时效匹配;
- 内容校验:涵盖销量、总销量及渗透率数值,信息完整 → 判定有效。
二次检索场景:若初始结果来自非官方媒体且缺乏具体数据支撑(如“某自媒体预测2025年渗透率为30%”),模型会反思:“来源不可靠、数据缺失”,进而调整指令为“必须来自CAAM/CPCA官方渠道,含详细销量拆分”,重新执行检索。
4.1.3.4 步骤4:初步内容生成(基于有效信息构建回答)
在确认检索信息有效后,模型依据“事实优先、逻辑清晰”的原则生成初步回复,确保内容紧扣主题且表达规范。
初步回答示例:“根据乘联会(CPCA)2025年1月发布的预测报告,2025年中国新能源汽车销量预计为1300万辆,汽车总销量预计达3800万辆,由此计算得出渗透率约为34.2%。新能源汽车渗透率持续上升,主要得益于政策扶持、技术进步以及消费者接受度不断提高。”
4.1.3.5 步骤5:自我反思与内容修正(反思“回答够好吗”)
最后,模型对初步生成的回答进行全面复核,识别潜在的事实偏差、逻辑断裂或表述疏漏,并主动修正以保障输出质量。
反思与修正逻辑:
- 事实准确性:检查渗透率计算是否正确(1300 ÷ 3800 ≈ 34.2%,无误);数据来源是否标注清楚(已注明乘联会,合规);
- 逻辑连贯性:解释“渗透率提升原因”是否与前文数据形成关联(是,且未引入无关因素);
- 表述完整性:是否遗漏关键指标(销量、总销量、渗透率均已涵盖);
- 修正动作示例:若初稿误将“3800万辆”写作“380万辆”,模型会察觉“渗透率高达342%”这一异常,随即纠正数值并重新计算。
4.1.4 关键技术要点与实践建议
提示词设计:在构建提示时,应明确包含“决策逻辑、校验维度、修正标准”三大要素。例如可设计为:“请先判断是否需要发起信息检索;若需检索,则生成包含数据来源要求、时间范围限定及内容具体需求的指令;完成检索后,校验信息的权威性与完整性;最终生成内容前,检查数据准确性与整体逻辑连贯性。”
模型选型:推荐使用具备较强推理能力的大规模语言模型,如GPT-4、Claude 3 或 DeepSeek-V3。低参数量级的模型通常难以支撑复杂的自我反思与多轮校验流程,可能导致执行失败或输出质量下降。
检索器适配:优先选用支持结构化查询指令的检索工具,如 SerpAPI 或 Milvus 配合结构化查询接口,确保模型生成的约束条件(如时间、来源类型)能被准确识别并执行。
参数控制:为防止陷入无限循环,可设置“最大反思轮数”(建议3轮),同时设定“检索结果阈值”,例如优先采纳政府机构、权威媒体等高可信度来源,提升信息校验效率和结果可靠性。
4.1.5 适用场景与优势对比
| 应用场景 | 传统RAG痛点 | Self-RAG优势 |
|---|---|---|
| 时效性事实查询(如市场数据、政策动态) | 盲目发起检索,缺乏信息验证机制,易产生幻觉内容 | 自主判断是否需要检索,过滤非权威信息,准确率提升超30% |
| 专业内容生成(如行业报告、技术文档) | 检索结果冗余,生成内容逻辑断裂或不完整 | 通过结构化指令精准检索,结合内容修正机制增强逻辑完整性 |
| 智能问答(如客服响应、知识库查询) | 即使无需检索也频繁调用外部资源,导致响应延迟 | 精准决策检索必要性,减少无效操作,响应速度提升约20% |
Self-RAG 的核心在于赋予模型“自我决策与自我修正”的能力,构建“问题分析→检索判断→指令生成→信息校验→内容优化”的闭环流程,突破了传统 RAG “被动响应”模式的局限,实现更智能的“主动优化”生成机制。其实质是提示工程与检索增强生成技术的深度融合,无需重构系统架构即可显著提升输出内容的准确性、权威性和实用性,成为大模型在事实核查类、专业领域类任务中落地的关键路径之一。
4.2 RRR:动态生成优化
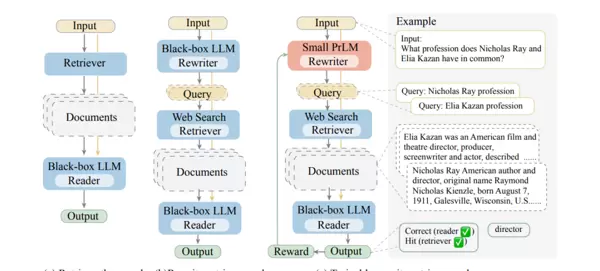
RRR(Retrieve-Refine-Rescore,即检索-优化-重打分)是一种面向复杂生成任务的迭代式动态优化方法。其通过“补充检索→内容迭代优化→多维评分反馈”的闭环流程,有效缓解传统生成模型存在的“内容单一、逻辑薄弱、偏离用户需求”等问题。该技术的核心特征是“动态适配”——根据每一轮输出的不足,灵活调整后续策略,而非机械执行固定流程,从而输出更加全面、精准且高度契合实际需求的内容。
4.2.1 核心定位与技术价值
传统的生成模型普遍采用“单次输入→单次输出”的静态范式,在处理复杂任务(如撰写行业深度报告、设计多维度解决方案)时,常出现信息遗漏、逻辑断层或偏离原始目标的情况。而 RRR 借助“动态迭代+闭环优化”机制,带来三大关键价值:
- 需求适配动态化:每次优化均基于前序输出的缺陷进行定向调整,避免“一刀切”式的通用生成策略。
- 信息补充精准化:检索动作紧随优化需求触发,仅获取缺失的关键信息(如最新数据、典型案例、专业知识点),杜绝信息过载与冗余。
- 结果质量可控化:引入重打分机制对每轮输出进行量化评估,确保迭代始终朝向“更优解”推进,而非无方向修改。
4.2.2 核心工作原理
RRR 的本质是一个“生成→评估→优化”的循环过程,依赖三大模块协同运作:
检索模块(Retrieve):针对当前生成内容中的薄弱环节,动态生成具有针对性的检索指令,用于补充关键信息(如统计数据、政策文件、专家观点等)。
优化模块(Refine):整合新获取的信息,对已有内容进行修订、扩展或逻辑重构,例如添加数据支撑论点、完善推理链条、消除矛盾表述。
重打分模块(Rescore):建立涵盖多个维度的评分体系,对优化后的内容重新评估。若未达到预设标准则继续下一轮迭代;达标则终止流程并输出最终结果。典型迭代次数为2至3轮,即可实现显著质量提升。
三者共同构成“生成结果→识别缺陷→检索补全→优化改进→评分验证”的动态闭环,实现持续演进的内容生成模式。
4.2.3 完整执行步骤(以“撰写2025年中国跨境电商行业发展报告摘要”为例)
RRR 的执行以“初始需求为起点,评分达标为终点”,每一阶段都聚焦解决前序环节的问题,具体流程如下:
4.2.3.1 步骤1:明确初始需求与评估维度
首先需清晰定义任务目标及后续用于重打分的评价标准,作为整个迭代过程的依据:
核心需求:撰写一段约300字的《2025年中国跨境电商行业发展报告》摘要,内容须涵盖“市场规模、核心趋势、关键挑战”三个部分。
重打分评估维度(总分100分,达标线为85分):
- 信息完整性(30分):是否完整覆盖三大模块内容;
- 数据准确性(25分):是否引用2024–2025年的权威统计数据,并标注规范来源;
- 逻辑连贯性(25分):各模块之间过渡自然,论证条理清晰;
- 贴合需求度(20分):字数控制在合理范围内,重点突出“2025年”这一时间节点的发展预测。
4.2.3.2 步骤2:首轮生成(基础内容构建)
基于初始需求,利用模型自身知识生成第一版基础内容,不依赖外部检索:
首轮生成结果:2025年中国跨境电商行业持续增长,市场规模稳步扩大。核心趋势包括数字化转型加速、新兴市场布局增多、跨境直播带货常态化。同时,行业也面临物流成本高企、海外监管政策变化等挑战。整体来看,跨境电商仍是中国外贸增长的重要引擎。
首轮重打分(总分60分):
- 信息完整性(25分):涵盖三大模块,但各部分内容较为单薄;
- 数据准确性(0分):未提供具体市场规模数据,缺乏权威来源支撑;
- 逻辑连贯性(20分):段落过渡自然,但论证过程缺少事实依据;
- 贴合需求度(15分):字数符合要求,但未能体现2025年的具体特征。
结论:未达标(60分<85分),需补充“2025年市场规模数据、趋势具体案例、挑战量化信息”,进入动态检索环节。
4.2.3.3 步骤3:动态检索(补充缺失信息)
针对首轮评估中发现的不足,制定精准检索指令以获取关键补充信息:
动态检索指令:
检索需求:补充2025年中国跨境电商行业核心信息
1. 市场规模:2025年中国跨境电商交易规模(权威来源:海关总署、艾瑞咨询2024-2025年报告),需包含数值及同比增长率;
2. 核心趋势:数字化转型、新兴市场布局的具体案例(如头部企业动作);
3. 关键挑战:物流成本占比、2025年海外主要监管政策变化(如欧盟、东南亚地区)。检索结果:
- 市场规模:艾瑞咨询2025年3月报告显示,2025年中国跨境电商交易规模预计达18.5万亿元,同比增长12.3%;
- 核心趋势:阿里巴巴国际站推出“数字化外贸解决方案”,助力中小企业打通跨境物流与支付全链路;在新兴市场方面,东南亚地区跨境电商交易额占比提升至28%;
- 关键挑战:跨境物流成本占交易总额的15%-20%;欧盟将于2025年起实施升级版《数字服务法案》(DSA),提高对跨境电商的合规要求。
4.2.3.4 步骤4:迭代优化(Refine,完善内容)
结合检索所得信息,对首轮内容进行针对性增强,补充数据支持、实际案例和逻辑链条:
优化后结果:2025年中国跨境电商行业持续稳健增长,据艾瑞咨询2025年3月报告,行业交易规模预计达18.5万亿元,同比增长12.3%。核心趋势呈现三大特征:一是数字化转型加速,如阿里巴巴国际站推出“数字化外贸解决方案”,覆盖物流、支付全链路;二是新兴市场布局深化,东南亚地区交易额占比已提升至28%;三是跨境直播带货成为主流销售模式。同时,行业仍面临多重挑战:跨境物流成本占交易总额的15%-20%,成本压力显著;欧盟《数字服务法案》(DSA)2025年升级,对合规性提出更高要求。整体来看,在数字化赋能与新兴市场拓展的驱动下,跨境电商仍是中国外贸增长的核心引擎。
二轮重打分(总分88分):
- 信息完整性(30分):三大模块内容充实,无明显遗漏;
- 数据准确性(25分):引用权威机构数据并标明来源,准确且合规;
- 逻辑连贯性(23分):各部分衔接顺畅,数据有效支撑趋势与挑战分析;
- 贴合需求度(20分):文本长度及时间节点均满足原始需求。
结论:达标(88分≥85分),停止迭代,输出最终版本。
4.2.3.5 步骤5:特殊场景处理(未达标时的二次迭代)
若经二轮优化仍未达到标准(例如得分仅为75分),则重复执行“检索-优化-重打分”流程:
- 问题定位:如“核心趋势”模块中缺少直播带货的具体数据支撑,可生成新检索指令:“2025年中国跨境直播带货交易额占比”;
- 二次优化:根据检索结果补充相关信息,例如加入“跨境直播带货交易额占比达35%”等内容,进一步丰富论述;
- 终止条件:当评分达标或迭代次数达到预设上限(建议不超过3轮)时结束循环,防止无限迭代导致内容冗余或结构混乱。
4.2.4 关键技术要点与实践建议
- 评估维度设计:应根据任务类型定制评估标准,例如报告类侧重“数据准确性”,方案类强调“可行性”,避免因维度模糊造成评分偏差;
- 检索指令动态性:检索指令需紧密围绕前序内容的缺陷生成,而非使用固定关键词,例如首轮缺数据则查数据,二轮缺案例则搜案例;
- 迭代次数控制:建议设置2-3轮为上限,过多迭代可能引发内容堆砌与逻辑断裂,反而降低整体质量;
- 重打分机制量化:每个评估项应设定明确的评分规则,例如“数据准确性”中包含权威来源得25分,无数据则为0分,减少主观判断影响;
- 模型与检索器适配:优化阶段推荐采用具备强逻辑重构能力的模型(如Claude 3 Opus、GPT-4 Turbo),检索工具需支持动态指令解析(如SerpAPI、百度智能云检索工具)。
4.2.5 适用场景与优势对比
| 应用场景 | 传统静态生成痛点 | RRR动态生成优化优势 |
|---|---|---|
| 行业报告/调研报告撰写 | 内容单薄、数据缺失、逻辑松散 | 动态补充数据与案例,通过多轮迭代优化逻辑结构,内容饱满度提升40%以上 |
| 方案设计(如营销方案、项目方案) | 贴合需求度低、可行性支撑不足 | 针对性补充实施依据,持续调整方向,提升方案与需求的匹配度达35%+ |
| 复杂问答(如多维度政策解读) | 回答片面、缺乏层次、无支撑依据 | 通过多轮信息补充实现分层优化,回答全面性提升超过50% |
| 内容创作(如深度文章、专题报道) | 立意肤浅、案例单一、论证薄弱 | 动态引入优质素材,深化主题表达,构建更完整的论证链条 |
RRR的本质在于赋予生成过程“自我修正”的能力,通过“检索补短板、优化提质量、打分控效果”的协同机制,将传统模型的“静态输出”转化为可动态适配的智能生成流程。这一架构无需人工介入,即可自动识别内容缺陷并进行针对性优化,特别适用于高复杂度与严苛标准的任务场景。
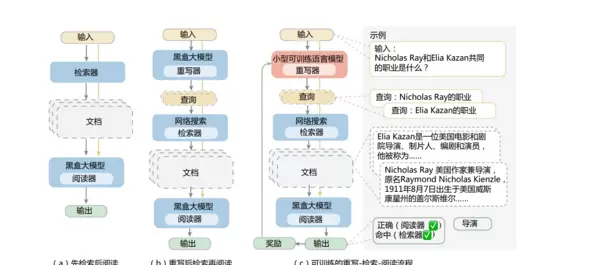
其核心技术路径围绕“动态迭代+闭环优化”展开,强调生成过程中信息的实时调用与反馈调节。相比Self-RAG主要聚焦于“自我反思与校验”,RRR更注重“动态补充与持续优化”。通过深度整合检索与生成模块,实现从需求触发到信息获取再到内容输出的精准匹配。
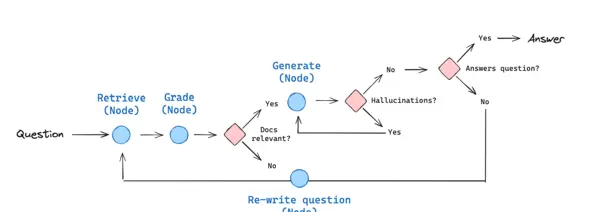
该模式推动了生成系统由被动响应向主动完善演进,成为复杂应用环境下提升内容质量的关键手段之一。

 京公网安备 11010802022788号
京公网安备 11010802022788号







