


 雷达卡
雷达卡



最近在对TestStand的报告格式进行定制化调整,发现其自带的报告插件虽然基础功能完备,但在实际使用中仍存在诸多不便。尤其当测试项数量庞大时,原始报告结构混乱、信息密度过高,导致问题定位效率低下。本文介绍一种无需二次开发、直接通过修改报告生成序列实现报告优化的方法,支持多语言环境且一次配置即可全局生效。
该方法的核心原理是在TestStand的报告生成流程中插入表达式逻辑,通过对测试序列的结构分析动态生成结构化内容,从而实现报告的智能重组与导航增强。整个过程不涉及任何编程或语言层面的改动,完全基于原生机制扩展。
首先,进入TestStand的Report生成序列,定位到“Generate Report”这一核心步骤。我们的目标是在报告正式输出前,对其数据源进行预处理。可在PostExpressStep阶段加入自定义代码段:
mainTests = [ts for ts in Report.Result.Root.Children if ts.Leafness == 0]
# 生成汇总表格HTML
summaryTable = "<table class='summary'><tr><th>测试模块</th><th>状态</th></tr>"
for test in mainTests:
status = "PASS" if test.Status == "Passed" else "FAIL"
detailLink = f"#{test.Name.replace(' ','_')}" # 生成锚点
summaryTable += f"<tr><td><a href='{detailLink}'>{test.Name}</a></td><td>{status}</td></tr>"
summaryTable += "</table>"上述代码的关键在于利用test.Leafness属性(0表示非叶子节点,即测试组)自动识别顶层测试模块,并据此构建包含锚点链接的汇总表。每个链接将跳转至对应测试项的详细结果区域,实现一键直达,极大提升查阅效率。
为进一步强化问题排查能力,在报告生成流程末尾添加失败项汇总模块:
# 失败项专属区块
failSection = "<div class='fail-list'><h3>异常清单</h3><ul>"
for step in Report.Result.GetAllSteps():
if step.Status == "Failed" and step.Parent.Leafness == 1:
errorMsg = step.Result.ErrorMessage or "未记录错误信息"
failSection += f"<li>{step.Name}:{errorMsg}</li>"
failSection += "</ul></div>"
Report.ReportText = failSection + Report.ReportText此部分通过调用GetAllSteps()获取全部测试步骤,结合Parent.Leafness == 1条件筛选出最底层的实际测试项,仅提取其中状态为Fail的条目并集中展示。这样一来,所有失败项会在报告开头醒目呈现,便于快速响应和决策。
如何确保该方案适用于不同语言版本的测试?关键在于避免触碰任何语言相关模板或资源文件。TestStand的报告生成本质上是一套基于XML的数据处理流水线,只要在数据准备阶段进行干预,而不修改最终渲染模板,就能天然支持包括日语、俄语等含特殊字符的语言环境。实测验证无乱码、无解析异常。
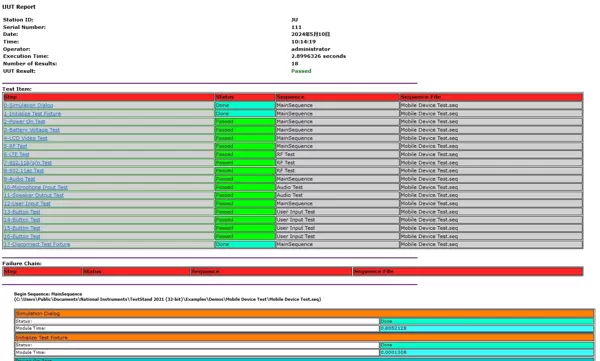
改造前后效果对比显著:原本长达20页的线性报告,现可在首页清晰展现测试项总览与失败统计,点击模块名称即可跳转至详情区域。经团队实测,平均故障定位时间由原来的15分钟压缩至30秒以内,维护效率大幅提升。
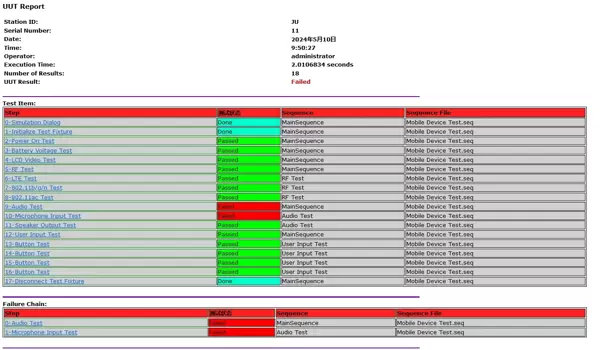
这种优化方式的本质并非推翻重来,而是在原有稳定机制上增加智能化的数据分拣逻辑。与其重新开发整套报告系统,不如在关键节点注入少量高效逻辑,让原生功能发挥更大价值。通过合理利用TestStand自身的执行序列与属性体系,即可实现高可读性、强交互性的测试报告输出。

 京公网安备 11010802022788号
京公网安备 11010802022788号







