


 雷达卡
雷达卡



在人工智能快速发展的今天,医疗领域作为关键应用场景之一,面临着数据规模庞大、信息维度复杂以及对准确性极高要求的多重挑战。如何在确保输出精准的同时,充分发挥大模型的语言理解与生成能力,成为行业关注的核心问题。
众所周知,当前主流生成式AI模型参数量可达数百B级别,但由于向量空间中语义相似性难以完全区分,导致“幻觉”现象不可避免。然而,这种幻觉也正是推动AI从符号逻辑迈向类人思维的重要契机。我们认同Hinton和Ilya所代表的技术路线——通过具象化语言与世界的关系,使机器逐步具备真正的认知能力。
基于此理念,我们提出并实现了一套面向医疗场景的大模型“零幻觉”解决方案。该方案聚焦于对精确度要求极高的应用方向,如临床诊断评估、疾病入组判定等,具体对应国家卫健委发布的《卫生健康行业人工智能应用场景参考指引》中的第三项“人工智能+医保服务”(医保智能审核)和第五项“人工智能+医院管理”(医疗文书质控)。这些涉及资金流转与政策执行的环节,绝不允许出现事实性错误。
经过与暨南大学第一附属医院长达半年的实际协作与场景验证,我们在真实工作流程中成功实现了无幻觉内容输出,达成了医保精准入组等多项核心目标。
项目成果《基于大模型与MCP和Agent结合的病历全内涵质控系统》已入选广东省“人工智能+医疗卫生”典型应用场景案例。
那么,这套系统是如何实现“零幻觉”的?以下是核心技术路径:
一、RAG:重构知识库构建方式
传统RAG多采用短文本切分、嵌入后重排序的方式构建知识库。我们的方法不同——引入MCP长上下文协议,突破常规分割限制。利用段落级与语义级联合分割策略,单次输入可接近4096 token上限,并通过MCP协议将多个语义块串联,实现跨片段的统一语义理解,显著提升上下文连贯性与信息完整性。
二、MCP协议:优化长文本传输机制
MCP是由Anthropic提出的开放协议。我们在实际应用中对其进行了深度适配,结合可调长度机制与压缩打包技术,确保超长上下文在传输过程中不丢失关键信息,有效避免因截断或稀释造成的语义偏差,从而保障最终生成结果的质量与稳定性。
三、Agent架构:以提示工程驱动逻辑控制
尽管目前对Agent的定义多样,但我们更关注其在真实场景中的问题解决能力。为此,我们主要依赖高度结构化的提示词设计来实现任务调度、推理链条控制与输出规范约束。
提示词并非简单指令,而是融合了逻辑结构、思维方式、时空维度、范围限定与扩展机制的复杂系统。通常每条提示词长度达数千token,在兼顾表达充分性的同时,我们也加入了信号隔离与处理机制,防止过长输入引发的信息混淆问题。
此外,针对真实病历数据的多样性与非标准化特征,我们还集成了多项数据清洗与结构化处理技术。一份完整的病历通常包含患者主诉、体格检查记录、各类检验检查报告、医生诊断意见、医患沟通纪要、诊疗流程日志(用于责任追溯)、手术记录及出院总结等内容。通过对这些异构信息进行系统整合与语义对齐,最终实现了在效率与准确率之间取得良好平衡。
上述多种技术协同作用,使得AI在病案内涵质控与医保费用控制等高风险场景中,能够稳定输出无幻觉、可信赖的结果。
虽然具体的分析过程不便公开展示,但我们可以分享一组实践成果:我们参与了《中国医院协会病案管理专业委员会国际疾病分类技能水平考试》的练习题测试,全部判断题轻松满分。为进一步体现系统在复杂情境下的分析能力,我们选取其中最具挑战性的5道综合分析题进行演示。
以下为题目解析部分:



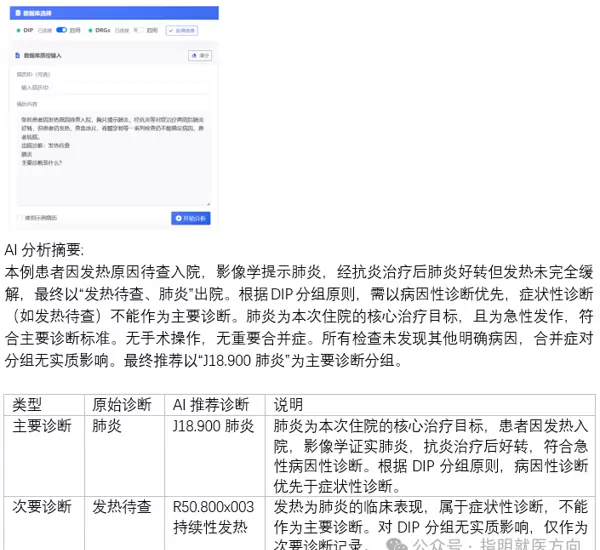





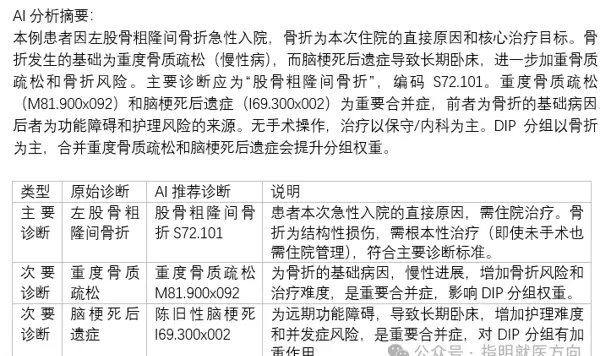


值此医师节之际,谨向广大医务工作者致敬。医生对患者的准确诊断是医学实践的金标准,也是人工智能理解现实世界的桥梁。正是临床专家的专业判断,为AI提供了最可靠的知识锚点,其贡献不可替代。
附录:

 京公网安备 11010802022788号
京公网安备 11010802022788号







