


 雷达卡
雷达卡



分布式搜索中的核心挑战与优化路径
在构建大规模搜索系统时,Elasticsearch凭借其分片(Shard)机制实现了良好的水平扩展能力。然而,这种分布式的架构也带来了两个关键性问题:
- 查询流程复杂化:由于数据被分散存储于多个节点,一次完整的检索需要跨节点协同完成。
- 相关性评分失真:局部统计信息(如文档频率DF)导致全局排序结果出现偏差,影响搜索质量。
基础概念说明
协调节点(Coordinating Node):负责接收客户端请求、分发查询任务,并对各分片返回的结果进行汇总和排序的临时处理节点。
BM25算法:Elasticsearch默认使用的相关性评分模型,基于TF-IDF改进而来,引入了词频饱和机制与文档长度归一化,提升长文档的排序合理性。
Query-Then-Fetch 执行机制详解
1)Query 阶段:分布式初步筛选
该阶段的核心目标是在不掌握全局数据的前提下,尽可能准确地定位候选文档集。
执行流程如下:
- 协调节点从索引的所有主分片或副本中,随机选取一组完整覆盖所有分片ID的实例。
- 每个分片独立执行本地查询,返回匹配文档的ID及其局部排序分值(例如:
)。_score - 协调节点将来自各个分片的结果进行合并,并进行全局排序。
- 根据用户指定的翻页范围(如取第10至第19条),截取最终需拉取的文档列表(例如:
)。from=10, size=10
此设计的根本原因在于:在分布式环境下无法预知某文档在整个索引中的真实排名位置,因此必须通过冗余获取一定量的数据来保障准确性。
from+size2)Fetch 阶段:完整文档聚合
在确定目标文档ID后,进入第二阶段的数据补全过程。
主要操作包括:
- 依据Query阶段生成的文档ID列表,向对应分片发起请求以获取完整文档内容。
- 协调节点不对Fetch回的数据重新排序,直接组装并返回给客户端。
关键要点总结
- 分片选择必须确保涵盖所有分片ID(如 shard0/shard1/shard2),防止遗漏数据。
- 在深分页场景下(如 from=10000),需调高
参数配置,避免因内存溢出引发异常。index.max_result_window
案例分析:相关性算分偏差及其应对策略
1)问题再现:分片本地统计引发评分误差
相关性评分(如 BM25)依赖以下三项核心统计指标:
- TF(Term Frequency):词项在单个文档中出现的次数。
- DF(Document Frequency):包含该词项的文档数量。
- IDF(Inverse Document Frequency):
,用于衡量词项的稀有程度与重要性。log(总文档数/DF)
核心症结:当前DF与IDF仅基于各分片本地数据计算,导致跨分片统计不一致。举例说明:
假设词项“倒排索引”在 Shard A 中 DF=10,而在 Shard B 中 DF=1,则两者计算出的 IDF 值不同,进而造成同一文档在不同分片中得分不一致,破坏全局排序一致性。
实验验证步骤
// 创建多分片索引(默认5个分片)
PUT /test_search_relevance
{
"mappings": {
"properties": {
"name": { "type": "text" }
}
}
}
// 批量插入测试文档
POST /test_search_relevance/_bulk
{"index":{}}
{"name":"hello"}
{"index":{}}
{"name":"hello world"}
{"index":{}}
{"name":"hello world beautiful world"}
// 发起查询并开启解释模式查看评分细节
GET /test_search_relevance/_search
{
"query": { "match": { "name": "hello" } },
"explain": true
}
异常现象观察
预期应呈现递减趋势:
> "hello"
> "hello world"
,但实际所有文档得分相同。"hello world beautiful world"
根本原因剖析
| 分片 | 文档频率(DF) | 计算依据 |
|---|---|---|
| Shard0 | 1 | 仅基于当前分片统计数据 |
| Shard1 | 1 | 非全局数据参与计算 |
| Shard2 | 1 | 导致IDF估值错误 |
2)解决方案对比与实践建议
| 方案 | 实施方式 | 适用场景 | 性能影响 |
|---|---|---|---|
| 单分片模式 | |
文档量<1000万 | 扩展性差,大数据量下性能显著下降 |
| DFS查询模式 | |
对算分精度要求高的场景 | 内存消耗增加30%以上,响应延迟上升 |
| 混合方案 | 高频词搜索使用 |
大数据量且兼顾实时性的需求 | 在精准度与性能之间取得平衡 |
方案一:单分片部署模式
适用条件:适用于数据规模较小的情况(通常低于百万级文档)。
实现方法:
# 创建索引时强制设置为1个分片
PUT /test_search_relevance
{
"settings": {
"number_of_shards": 1
}
}
优势:DF 和 IDF 统计基于全局数据,确保相关性评分的一致性和准确性。
局限:丧失横向扩展能力,在数据增长后易成为性能瓶颈。
方案二:启用 DFS Query Then Fetch 模式
工作原理:
- 预查询阶段:协调节点先向所有分片发起探测请求,收集全局的文档频率(DF)信息。
- 正式查询阶段:利用统一的全局统计量重新计算BM25得分,保证排序公正性。
调用方式:
GET /test_search_relevance/_search?search_type=dfs_query_then_fetch
{
"query": {
"match": {
"name": "hello"
}
}
}
效果验证:可正确返回符合预期的评分顺序:
> "hello"
> "hello world"
。"hello world beautiful world"
潜在缺陷:
- 额外的预查询带来更高的CPU与内存开销。
- 不适合超大规模数据集,可能触发OOM(内存溢出)风险。
代码示例:NestJS 中实现 DFS 查询
// NestJS 实现 DFS 查询(对应方案二)
import { ElasticsearchService } from '@nestjs/elasticsearch';
@Injectable()
export class SearchService {
async dfsSearch(index: string, query: any) {
return this.esService.search({
index,
body: { query },
search_type: 'dfs_query_then_fetch' // 启用全局统计
});
}
3)算分算法原理深度解析:BM25 公式详解
Elasticsearch 的相关性算分核心依赖于 BM25 算法,其数学表达式如下:
score(D, Q) = Σ [ IDF(qi) * (f(qi,D) * (k1 + 1)) / (f(qi,D) + k1 * (1 - b + b * |D|/avgdl)) ]
该公式用于计算文档 D 对查询 Q 的相关性得分,综合考虑了词频、逆文档频率以及文档长度归一化等因素。
关键参数说明:
:表示词项在目标文档 D 中的出现频率(即 TF,Term Frequency)f(qi,D)
:未标注具体含义,需结合上下文理解IDF(qi)
:用于计算 IDF 值,其中 N 为总文档数量,n 为包含当前查询词项的文档数log(1 + (N - n(qi) + 0.5) / (n(qi) + 0.5))
/k1
:分别为调节词频增长饱和度的 k1 参数与控制文档长度影响的 b 参数,属于模型超参b
核心要点摘要:
在默认检索模式下,各分片独立完成本地统计量(如文档频率、平均长度等)的计算。这种机制可能导致 IDF 和 avgdl 的局部估算偏差。
Nn(qi)DFS 模式(即 dfs_query_then_fetch)通过引入预查询阶段,先从所有分片收集全局统计信息(如全局文档频率、整体平均文档长度),再执行正式检索与算分,有效修正此类偏差。
工程实践:NestJS 集成与集群优化策略
1)基础检索功能实现
使用 NestJS 框架集成 Elasticsearch 客户端,构建 RESTful 接口处理搜索请求:
import { Controller, Get, Query } from '@nestjs/common';
import { Client } from '@elastic/elasticsearch';
@Controller('search')
export class SearchController {
private esClient: Client;
constructor() {
this.esClient = new Client({ node: 'http://localhost:9200' });
}
@Get()
async search(
@Query('keyword') keyword: string,
@Query('from') from: number = 0,
@Query('size') size: number = 10,
) {
const { body } = await this.esClient.search({
index: 'test_index',
body: {
query: { match: { content: keyword } },
from,
size
}
});
return body.hits.hits;
}
}
2)启用 DFS 模式以提升算分准确性
通过设置 search_type 参数为 dfs_query_then_fetch,确保相关性评分基于全局统计量进行计算:
import { Search } from '@elastic/elasticsearch/api/requestParams';
@Get('dfs')
async dfsSearch(@Query('keyword') keyword: string) {
const params: Search = {
index: 'test_index',
search_type: 'dfs_query_then_fetch', // 启用全局算分机制
body: { query: { match: { content: keyword } } }
};
const { body } = await this.esClient.search(params);
return body.hits.hits;
}
3)动态分片策略管理
根据实际数据规模动态调整索引分片数量,优化写入与查询性能:
// 根据数据总量决定主分片数目
import { IndicesPutSettingsRequest } from '@elastic/elasticsearch/lib/api/types';
@Post('update-shards')
async updateShards() {
const params: IndicesPutSettingsRequest = {
index: 'logs',
body: {
settings: {
number_of_shards: dataSize > 1e8 ? 6 : 3, // 数据量超亿级时扩容至6个分片
number_of_replicas: 1
}
}
};
await this.esService.indices.putSettings(params);
}
4)集群健康状态监控
集成健康检查模块,实时掌握 Elasticsearch 集群运行状况:
import { HealthCheckService, HealthCheck } from '@nestjs/terminus';
@Controller('health')
export class HealthController {
constructor(
private health: HealthCheckService
) {}
}
分布式搜索的权衡艺术
Query-Then-Fetch 采用两阶段查询机制,旨在平衡分布式环境下的检索效率与资源消耗。分片作为系统横向扩展的核心手段,虽提升了性能潜力,但也带来了相关性算分一致性方面的挑战。
选型决策树:
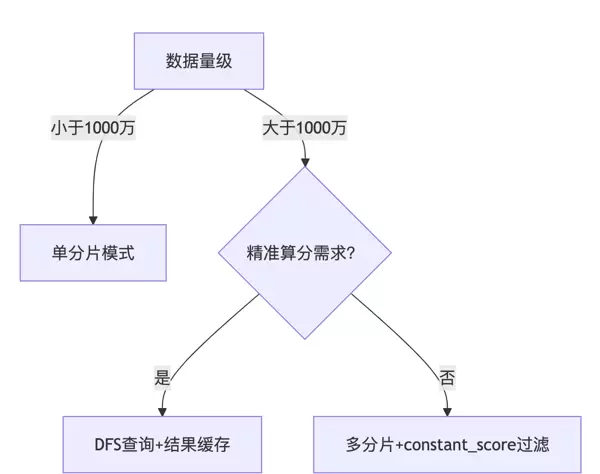
分片策略建议矩阵
| 数据类型 | 分片数公式 | 补充策略 |
|---|---|---|
| 日志流数据 | 按天分片(例如:log-2023.08.01) | 结合 ILM 策略实现索引自动滚动创建 |
| 千万级业务数据 | 节点数 × 1.5 | 利用 routing 实现请求定向,减少跨分片查询开销 |
| 高频查询索引 | 固定为 1-2 个分片 | 增加副本数量以提升读取并发能力 |
ES 配置优化与关键注意事项
1)分片策略优化
| 场景 | 分片数建议 | 原因说明 |
|---|---|---|
| 日志类数据 | 每日创建独立分片 | 便于管理维护,支持高效的时间范围查询操作 |
| 千万级业务数据 | 分片数量设置为集群节点数的 1.5 倍 | 实现负载均衡,防止出现热点分片问题 |
2)算分一致性保障措施
在以下情况下应避免使用 DFS 查询:
- 文档总量超过 1000 万条
- 查询频率较高(QPS 超过 100)
推荐替代方案:
- 采用
预先计算全局评分指标runtime_mappings - 定期更新
缓存内容,降低实时计算压力index.stats
3)分片调优与监控配置
限制单次搜索所涉及的分片数量(默认无上限):
action.search.shard_count.limit: 100监控 Query-Then-Fetch 阶段的响应延迟:
indices.search.query_time: 10s4)性能优化核心参数设置
elasticsearch.yml 中的关键配置项:
# 防止深分页引发性能问题
index.max_result_window: 10000
# 控制查询涉及的分片数,预防内存溢出
action.search.shard_count.limit: 100
执行强制合并以清理已删除文档并释放存储空间:
curl -XPOST 'http://localhost:9200/index/_forcemerge?only_expunge_deletes=true'5)分片健康监控体系构建
建立分片状态检测服务,确保集群稳定性:
// 分片状态检查服务
import { HealthCheckService, HealthCheck } from '@nestjs/terminus';
@Get('health/shards')
@HealthCheck()
async checkShards() {
const { body } = await esClient.cat.shards({ format: 'json' });
const unhealthyShards = body.filter(s => s.state !== 'STARTED');
return {
status: unhealthyShards.length ? 'down' : 'up',
details: { total: body.length, unhealthy: unhealthyShards }
};
}
6)生产环境实践建议
- 冷热分离架构:对高频访问的索引设置 1-2 个分片;历史归档数据可适当增加分片数以提高并行处理能力。
- 混合查询策略:针对标题等关键字段实施
聚合至单一分片索引,提升检索效率。copy_to - 性能警戒线设定:禁止对文档量超过 5000 万的索引使用 DFS 查询,建议改用预聚合方式维护全局统计指标。
终极认知总结
相关性评分本质上是一种概率模型,在分布式架构中必须在查询精准度与系统性能之间做出合理取舍。通过科学的分片规划、选择性启用 DFS 查询以及构建完善的监控机制,能够有效支撑工业级规模的搜索应用场景。
最佳实践配置模板
PUT /business_data
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"index.max_result_window": 10000
},
"mappings": {
"properties": {
"critical_field": {
"type": "text",
"copy_to": "global_score_field"
},
"global_score_field": {
"type": "text",
"norms": false
}
}
}
}
优化配置示意:
elasticsearch.yml2)算分一致性保障 为了确保搜索算分在分布式环境下的稳定性,需关注分片中文档的分布情况。 定期执行文档清理操作,可有效减少因文档删除带来的算分偏差。执行以下命令以清理已删除文档并优化段合并:GET /_cat/shards/my_index?v_forcemergecurl -XPOST 'http://localhost:9200/my_index/_forcemerge?only_expunge_deletes=true'该操作有助于提升查询效率,并增强算分结果的一致性。 3)混合方案建议 根据不同业务场景,推荐采用相应的搜索策略组合:
| 场景 | 推荐方案 |
| 实时精准搜索 | DFS查询 + 缓存结果 |
| 大数据量搜索 | 单分片索引 + 垂直拆分 |
| 高频词搜索 | 设置 过滤 |
GET /_nodes/hot_threads?type=cpu
- 检查指定索引的分片分布情况:
GET /_cat/shards/test_linux?v
- 监控DFS查询过程中的内存使用:
GET /_nodes/stats/indices/search?human
结语
Query-Then-Fetch机制通过两阶段查询实现了分布式搜索效率的平衡,但也引入了算分不一致的风险。
开发人员应结合实际业务需求,选择合适的解决方案——如使用单分片、启用DFS查询或实施混合策略,并利用NestJS的模块化特性实现灵活集成。
特别提醒:当索引中文档数量超过5000万时,DFS查询可能引起集群性能波动。建议通过分片路由机制预先分配文档,优化数据分布结构,从而提升整体稳定性与响应效率。

 京公网安备 11010802022788号
京公网安备 11010802022788号







