


 雷达卡
雷达卡



AI 计算模式(下)
理解 AI 计算模式对于指导 AI 芯片的设计与优化方向具有重要意义。本节将围绕轻量化网络模型和大模型的分布式并行计算两个方面,深入探讨当前 AI 算法的发展趋势,并引发对 AI 计算模式更深层次的思考。
轻量化网络模型
随着深度神经网络在实际场景中的广泛应用,越来越多的模型需要部署在资源受限的硬件平台上,例如移动端或嵌入式设备。这类平台通常具备内存容量小、处理器性能有限以及功耗敏感等特性。因此,学术界和工业界逐渐发展出一种专注于模型轻量化的研究方向——即在尽可能保持模型精度的前提下,显著降低参数规模和计算开销的网络结构设计方法。
模型轻量化的衡量指标
评估一个网络是否“轻量”,主要依赖两个核心指标:一是网络的参数量(Params),二是浮点运算次数(FLOPs),即整体计算量。
1. 参数量(Params)
对于一个卷积操作,假设输入特征图尺寸为 w × h × Ci,卷积核大小为 k × k,输出特征图通道数为 Co,且输出尺寸为 W × H × Co,则该层的参数量可表示为:
Params = (k × k × Ci + 1) × Co
2. 浮点运算数(FLOPs)
在同一设定下,完成一次前向传播所需的浮点运算总量为:
FLOPs = W × H × (k × k × Ci + 1) × Co
虽然参数量和 FLOPs 是衡量效率的重要依据,但模型的实际运行速度还受到内存访问频率的影响,这与网络的整体架构密切相关。接下来我们将从 AI 计算模式的角度,分析几种典型的轻量化设计策略。
减少内存占用的设计
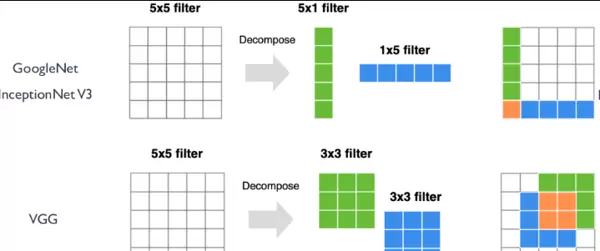
为了有效压缩模型体积,在 VGG 和 InceptionNet 系列网络中,研究人员提出使用多个小尺寸卷积核替代大尺寸卷积核的方法。例如,用两个连续的 3×3 卷积代替一个 5×5 卷积,或者采用 5×1 与 1×5 的分离式卷积组合来模拟 5×5 卷积的效果。
这种设计不仅能够在保持相同感受野的同时增加网络深度,从而提升表达能力,还能显著减少参数数量。以两个 3×3 卷积替代单个 5×5 卷积为例,原始参数为 5×5×Ci×Co,而新结构变为 2×(3×3×Ci×Co)。当输入输出通道相等时(Ci = Co),参数总量可降至原来的 18/25,实现约 28% 的压缩率。
减少通道维度的设计
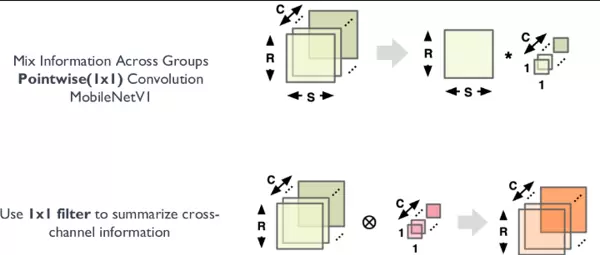
MobileNet 系列网络引入了深度可分离卷积(Depthwise Separable Convolution)的概念,通过将标准卷积分解为 Depthwise 卷积和 Pointwise 卷积两步操作,大幅削减计算负担。
其中,Depthwise 操作对每个输入通道独立进行空间卷积,而 Pointwise 卷积(即 1×1 卷积)则负责跨通道的信息融合与通道数调整,实现降维或升维。
举例说明:若有一个标准卷积层,卷积核为 3×3,输入通道为 16,输出为 32,则参数量为:
3 × 3 × 16 × 32 = 4608
若改用深度可分离结构:先执行 3×3 Depthwise 卷积(参数量为 3×3×16 = 144),再接 1×1 Pointwise 卷积(参数量为 1×1×16×32 = 512),总参数量仅为 144 + 512 = 656,相比原结构减少了超过 85%。
减少卷积核数量的设计
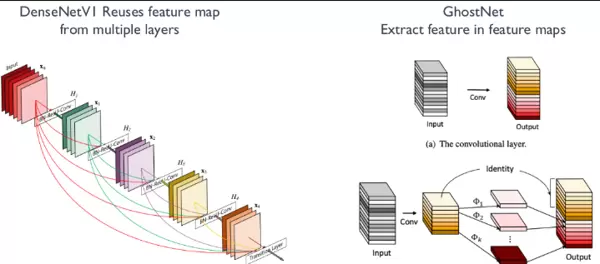
DenseNet 与 GhostNet 提出了基于特征图复用(Feature Map Reuse)的创新机制,旨在减少冗余计算与参数重复。
以 DenseNetV1 为例,第 n 层的输入整合了前 n1 层的所有输出特征图。设前 n1 层累计输出通道数为 C1,当前层新增输出为 C2,卷积核大小为 k,则传统卷积需参数量为:
k × k × Ci × (C1 + C2)
而在 DenseNet 中,由于部分输入已来自之前层的输出,实际参与变换的输入通道仍为 C2,因此参数量简化为:
k × k × Ci × C2
即仅占原方案的 C2 / (C1 + C2)。由于 C2 远小于 C1,参数节省效果十分明显。
关于 AI 计算模式的进一步思考
通过对轻量化模型的分析可以看出,现代神经网络设计越来越注重计算效率与资源利用之间的平衡。无论是通过结构重排降低参数量,还是借助分解策略减少运算复杂度,这些方法本质上都是对 AI 计算模式的持续优化。
未来,随着边缘计算需求的增长和大模型落地场景的拓展,如何在保证性能的同时实现高效推理,将成为 AI 架构演进的核心驱动力。这也反过来推动芯片设计向更加专用化、异构化的方向发展,以匹配多样化的计算模式。
AI 模型网络的轻量化设计中,卷积层的多样化结构是影响芯片计算模式支持的关键因素。通过对卷积操作的不同优化策略,可以在保持模型性能的同时显著降低计算与参数开销,这些特性在 AI 芯片架构设计中必须被充分考虑。
卷积核设计优化
- 小卷积核替代:使用多个小型卷积核(如 3×3)堆叠来代替单一的大尺寸卷积核(如 5×5 或 7×7),在维持感受野的同时减少参数量和计算复杂度。
- 多尺寸卷积核:结合不同尺度的卷积核进行特征提取,以增强模型对多尺度信息的捕捉能力,提升识别精度。
- 可变形卷积核:引入可学习的偏移机制,使卷积采样位置不再局限于规则网格,从而更灵活地适应不规则或复杂形状的特征分布。
- 1×1 卷积核:广泛应用于 bottleneck 结构中,通过压缩通道维度有效降低计算负担,同时实现跨通道的信息融合。
卷积层运算优化
- Depthwise 卷积:将标准卷积分解为逐通道卷积与逐点卷积,大幅削减参数数量,同时保留基本特征表达能力。
- Group 卷积:将输入通道划分为若干组,每组独立进行卷积运算,降低模型复杂度并提升并行计算效率。
- Channel Shuffle:在分组卷积后引入通道混洗操作,促进不同组之间的信息交互,增强特征融合效果。
- 通道加权:采用类似 Squeeze-and-Excitation 的机制,动态调整各通道的重要性权重,优化整体特征表示能力。
卷积层连接方式改进
- Skip Connection(跳跃连接):通过跨层直连路径缓解深层网络中的梯度消失问题,支持构建更深的网络结构。
- Dense Connection(密集连接):每一层输出都与其他后续层相连,形成密集的信息流动路径,强化特征复用与梯度传播。
大模型的分布式并行技术
随着大模型算法的发展,其庞大的参数规模和计算需求已远超单个芯片或加速卡的承载能力。因此,在 AI 芯片系统层面支持高效的分布式并行处理成为关键技术方向。当单设备无法满足算力与内存要求时,采用分布式架构进行模型训练尤为关键。
常见的分布式并行策略主要包括数据并行和模型并行两大类,其中模型并行进一步细分为张量并行和流水线并行。为了实现这些并行模式,底层依赖于一系列基础的集合通信原语。
常用集合通信原语
在分布式训练过程中,节点间的协同依赖于高效的通信机制。以下是一些核心的集合通信操作:
- All-reduce:收集所有节点的数据,执行归约操作(如求和、平均),并将结果广播回每个节点,常用于全局梯度同步。
- All-gather:将每个节点的局部数据发送至所有其他节点,使得每个节点最终获得完整的数据集合,适用于特征拼接或全局聚合场景。
- Broadcast:将某一节点上的数据复制并发送到其余所有节点,常用于初始化参数或分发共享信息。
- Reduce:对各节点数据执行归约操作,并将结果汇总至指定目标节点,适合局部聚合任务。
- Scatter:将一个节点上的数据分割后分发给其他节点,便于负载均衡和并行处理。
- Gather:将多个节点的数据集中到一个指定节点上,常用于结果汇总或集中分析。
数据并行技术分类
根据设备间通信粒度和参数存储策略的不同,数据并行可分为以下三种主要形式:
Data Parallelism (DP) —— 基础数据并行
该方法将训练数据划分为多个小批次,分配至不同的计算设备(如 NPU)。每个设备保存完整模型副本,独立完成前向与反向计算,生成本地梯度。随后通过 All-reduce 操作同步梯度并更新模型参数,确保各副本一致性。虽然实现简单,但存在较高的显存冗余和通信开销。
Distributed Data Parallel (DDP) —— 分布式数据并行
DDP 是一种更高效的分布式训练方案,适用于多节点环境。每个节点拥有独立的模型副本和数据子集,分别进行前向与反向传播。梯度通过 All-reduce 在所有节点间同步并取平均,从而实现全局参数更新。
相较于 DP,DDP 支持更高的扩展性,能有效降低单节点内存占用,因其仅需维护一份模型拷贝。此外,主流深度学习框架(如 PyTorch)提供了原生支持。
torch.nn.parallel.DistributedDataParallel例如,在 PyTorch 中,torch.nn.parallel.DistributedDataParallel 模块封装了 DDP 的完整逻辑,自动处理模型分发、梯度同步及通信调度,极大简化了分布式训练的开发流程。
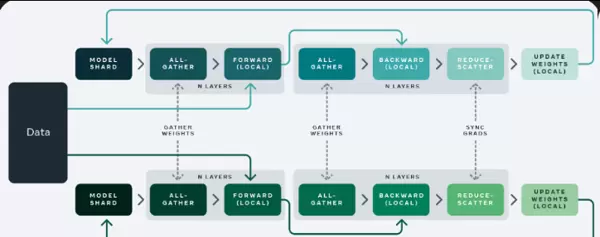
Fully Sharded Data Parallel (FSDP) —— 全分片数据并行
FSDP 进一步优化了内存使用效率,通过对模型参数、梯度和优化器状态进行分片管理,将它们分散存储在多个设备上。这种方式显著降低了单卡内存压力,尤其适合超大规模模型的训练部署。FSDP 结合了数据并行与模型并行的优势,在保证高吞吐的同时实现了良好的可扩展性。
Fully Sharded Data Parallelism(FSDP)是一种融合了数据并行(DP)与分布式数据并行(DDP)优势的并行训练技术,具备更高的训练效率和更强的横向扩展能力。其核心机制在于将模型的权重、梯度以及优化器状态进行分片处理,并将这些分片分布到多个计算设备或节点上执行并行运算。由于所有参数、梯度和优化状态都被分摊共享,因此在各个计算节点之间需要频繁进行通信,以完成数据的同步与聚合。
模型并行的主要形式
模型并行通常可分为张量并行与流水并行两种主要策略,二者从不同维度对模型结构进行拆分,以实现高效的分布式计算。
1. 张量并行
该方法通过对模型中的张量操作进行切分,将大型矩阵运算分解为多个子任务,在不同设备上并行执行。例如,在一个矩阵乘法运算中,输入激活X保持完整,而权重矩阵A按列方向被分割,每个计算节点持有完整的X和部分A。各节点独立完成局部计算后,通过All Gather等通信原语将中间结果拼接,生成完整的输出Y,供后续层使用。
这种策略有效缓解了单个设备的内存压力,同时提升了整体计算吞吐量。但需设计高效的通信机制,确保跨设备的数据交换与参数同步能够快速完成,常用的技术包括All-reduce用于梯度聚合。

2. 流水并行
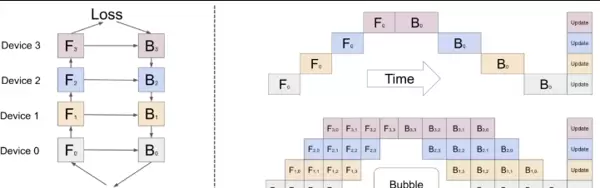
流水并行则是将整个神经网络模型划分为若干阶段,每个阶段部署在不同的计算设备上,形成类似流水线的执行结构。前向传播(Forward)与反向传播(Backward)操作按照时间顺序在各阶段间传递,从而实现计算资源的时间复用。
如图所示,假设一个包含四层网络的模型分布在四个设备上运行,每个设备依次处理对应层的前向与反向计算。在时间轴上可以观察到存在“气泡”(Bubble)区域,即设备空闲等待的状态。为了提升设备利用率,可通过引入数据并行机制,将输入批次进一步细分,使更多微批次(micro-batch)重叠执行,减少等待时间,提高整体并行效率。
AI 计算模式的硬件映射思考
基于上述并行策略的应用实践,可以看出大模型的计算范式正深刻影响着底层硬件架构的设计方向。在AI芯片开发过程中,应重点考虑以下几个方面:
支持模型与数据并行的双重能力
理想的AI芯片需同时兼容模型并行与数据并行策略。对于模型并行,要求芯片具备灵活的资源划分能力和低开销的片内/片间通信路径;而对于数据并行,则需提供高带宽、低延迟的同步机制,保障多节点间梯度聚合与参数更新的高效性。
异构计算资源整合
现代AI芯片往往集成了多种类型的计算单元,如CPU、GPU、TPU或其他专用加速器。为了充分发挥系统性能,必须构建统一的异构资源调度框架,实现不同类型计算核心之间的协同工作与动态负载均衡。
高效通信与同步机制
在分布式训练场景下,频繁的参数同步与数据传输成为性能瓶颈之一。因此,芯片层面应集成高性能互连结构(如NoC、高速总线)和优化的通信协议栈,以降低延迟、提升带宽,支撑大规模并行下的稳定通信。
端到端协同优化能力
从模型设计到硬件执行的全链路优化至关重要。例如,针对Transformer类模型广泛使用的现状,可在芯片中集成专用的高速Transformer引擎,针对自注意力、FFN等模块进行深度定制化加速,从而实现算法-架构-实现的联合优化。
总结与展望
未来的AI芯片设计需具备以下关键特性:
- 灵活支持多样化的神经网络架构,能够高效执行特定类型的计算逻辑,满足不同应用场景的需求;
- 集成对模型压缩技术(如量化、剪枝)的原生支持,提升终端部署时的推理效率,并实现软硬件协同优化;
- 面向轻量化网络结构进行优化,增强对复杂卷积操作和数据流控制的支持,适应算力与带宽受限的边缘环境;
- 强化对大模型分布式训练的支持能力,包括高容量片上内存、高速互联接口以及可扩展的片上网络设计,以应对多芯片堆叠与集群训练带来的挑战。

 京公网安备 11010802022788号
京公网安备 11010802022788号







