


 雷达卡
雷达卡







有了 scikit-learn,训练任何模型都非常简单。而且训练过程总是用看似相同的方法进行。所以我们习惯了训练任何模型都是相似且简单的。
借助自动机器学习、网格搜索和生成式人工智能,“训练”机器学习模型只需一个简单的“提示”即可完成。
但现实是,当我们做model.fit时,每个模型背后的流程可能非常不同。而且每个模型对数据的处理方式也非常不同。
我们可以观察到两种截然不同的趋势,几乎是两个相反方向:
一方面,我们用越来越复杂的模型(如生成模型)进行训练、使用、作和预测。 另一方面,我们并不总能解释简单模型(如线性回归、线性判别分类器),并手动重新计算结果。
了解我们所使用的模型非常重要。理解它们的最好方式是自己去实施。有些人用Python、R或其他编程语言来实现。但对于不编程的人来说,仍然存在障碍。而如今,理解人工智能对每个人都至关重要。此外,使用编程语言还可以将一些作隐藏在已有函数后面。而且没有可视化说明,意味着每个作都没有清晰展示,因为函数是编码后运行的,只给出结果。
所以我认为最好的工具是Excel。公式清晰地展示了计算的每一步。
事实上,当我们收到数据集时,大多数非程序员会用Excel打开它来了解里面的内容。这在商业世界中非常常见。
甚至许多数据科学家,包括我自己,也会用Excel快速浏览一下。当需要解释结果时,直接用Excel展示往往是最有效的方式,尤其是在高管面前。
在Excel里,所有内容都是可见的。没有“黑匣子”。你可以看到每一个公式、每一个数字、每一个计算。
这对理解模型的真实工作原理非常有帮助,无需偷工减料。
另外,你不需要安装任何东西。只是个电子表格。
我将发表一系列关于如何在Excel中理解和实现机器学习及深度学习模型的文章。
关于“降临节日历”,我每天会发布一篇文章。

这个系列是给谁看的?
对于正在学习的学生来说,我认为这些文章提供了实用的视角。它是为了理解复杂的公式。
对于机器学习或人工智能开发者来说,他们有时没有学习过理论——但现在,没有复杂的代数、概率或统计学,你可以打开 model.fit 背后的黑盒子。因为所有模型都用 model.fit。但实际上,这些模型可能非常不同。
这也适用于那些可能没有全部技术背景的管理者,但Excel会给他们模型背后所有直观的想法。因此,结合你的商业经验,你可以更好地判断机器学习是否真的必要,以及哪种模型更合适。
总结来说,就是更好地理解模型、模型的训练过程、模型的可解释性以及不同模型之间的联系。
文章结构
从从业者的角度来看,我们通常将模型分为两类:监督式学习和非监督式学习。
然后在监督学习中,我们有回归和分类。对于无监督学习,我们有聚类和降维。
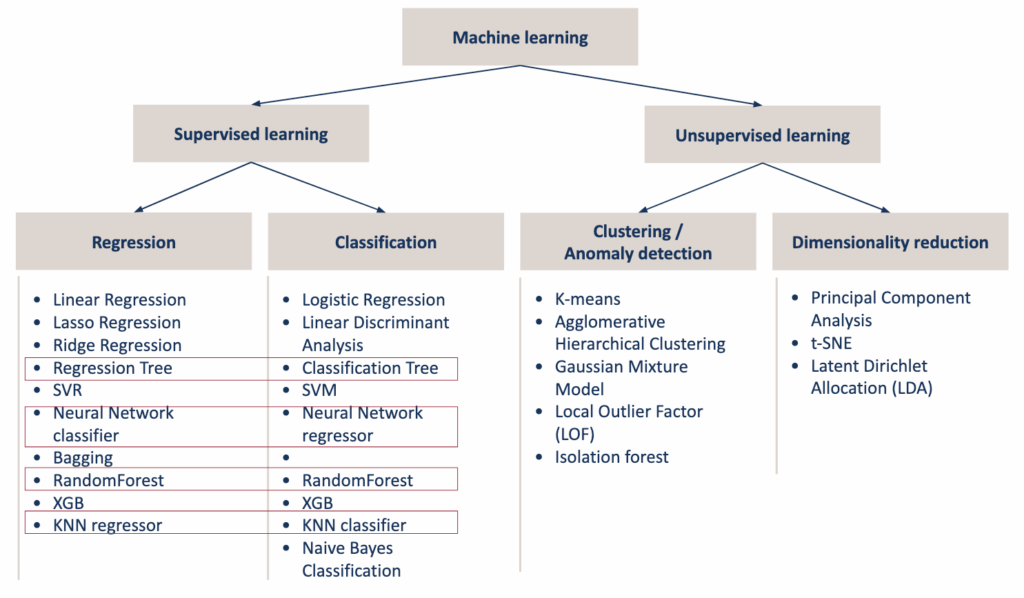
但你肯定已经注意到,有些算法可能共享相同或相似的方法,比如KNN分类器和KNN回归器,决策树分类器和决策树回归器,线性回归和“线性分类器”。
回归树和线性回归的目标相同,即完成回归任务。但当你尝试在Excel中实现它们时,你会发现回归树和分类树非常接近。线性回归更接近神经网络。
有时候人们会把K-NN和K-means混淆。有人可能会说他们的目标完全不同,混淆他们是初学者的错误。但我们也必须承认,它们在计算数据点之间距离的方式上有相同的方法。所以他们之间确实有关系。
隔离森林也是如此,我们可以看到在随机森林中也存在“森林”。
所以我将从理论角度组织所有模型。主要有三种方法,我们将清楚地看到这些方法在Excel中以截然不同的方式实现。
这个概述将帮助我们浏览所有不同的模型,并连接它们之间的点。
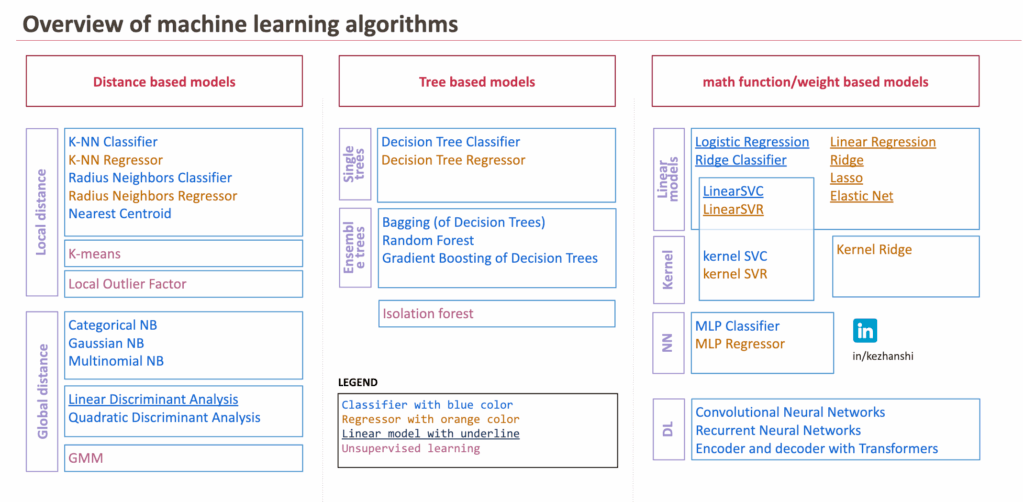
对于基于距离的模型,我们将计算新观测数据与训练数据集之间的局部或全局距离。 对于基于树的模型,我们必须定义用于划分特征类别的规则。 对于数学函数,思路是对特征施加权重。而主要用于训练模型,采用梯度下降法。 对于深度学习模型,我们认为主要关注特征工程,以创造数据的充分表示。 对于每个模型,我们都会尝试回答这些问题。
关于该模型的一般问题:
该模型的性质是什么? 模型是如何训练的? 模型的超参数是什么? 同样的模型方法如何用于回归、分类,甚至聚类? 特征建模方式:
类别特征是如何处理的? 缺失值是如何管理的? 对于连续特征,缩放会有影响吗? 我们如何衡量一个特征的重要性?
我们如何限定这些功能的重要性?这个问题也将被讨论。你可能知道像LIME和SHAP这样的软件包非常流行,而且它们对模型无关。但事实是,每个模型的行为都非常不同,直接用模型来解释也很有趣且重要。
不同模型之间的关系
每个模型都会单独写一篇文章,但我们会讨论与其他模型的链接。
我们还将讨论不同模型之间的关系。既然我们真正打开了每个“黑箱”,我们也知道如何对某些模型进行理论改进。
KNN和线性判别分析(LDA)非常接近。前者使用局部距离,后者使用全局距离。 梯度提升和梯度下降是一样的,只是向量空间不同。 线性回归也是一种分类工具。 标签编码可以某种程度上用于类别特征,它非常有用、非常强大,但你必须明智地选择“标签”。 SVM非常接近线性回归,甚至更接近脊回归。 LASSO 和 SVM 采用类似原理来选择特征或数据点。你知道LASSO的第二个S代表选择吗?
对于每个模型,我们还会讨论一个大多数传统课程容易忽略的点。我称之为机器学习模型的未被教导的教训。
模型训练与超参数调优
在这些文章中,我们将仅聚焦于模型的工作原理及其训练方式。我们不讨论超参数调优,因为每个模型的过程基本相同。我们通常使用网格搜索。


 京公网安备 11010802022788号
京公网安备 11010802022788号







