


 雷达卡
雷达卡



摘要
CFG-Bench构建了一种四层递进的认知框架,借助极细粒度的标注机制与反事实推理测试,系统化评估并增强AI对物理动作的深层理解能力,为具身智能体在真实复杂环境中的任务执行提供坚实基础。

引言
在具身智能(Embodied AI)的发展进程中,一个核心难题始终存在:如何使机器真正理解物理世界中动态交互的本质。尽管当前多模态大模型(MLLMs)在内容识别方面取得了显著突破,能够准确为视频片段打上诸如“一个人正在切西瓜”之类的标签,但这种能力本质上仍停留在分类或描述层面。它解决了“是什么”的问题,却难以触及更深层次的认知维度。 人类在观察动作时的认知过程远比简单的识别复杂得多。我们不仅能识别出“切西瓜”这一行为,还能迅速解析出手法细节——比如左手如何固定瓜体、右手如何控制刀具;理解背后的因果逻辑——为何要先稳定物体再下刀以防止滑动;推断潜在意图——是准备即食还是进行艺术雕刻;甚至能对动作质量做出判断——切割是否精准、安全和高效。这种涵盖“如何做”、“为何做”以及“做得好不好”的精细化认知体系,正是当前人工智能与人类智能之间存在的巨大差距。 这一认知鸿沟直接导致了机器人在现实世界中表现出“眼高手低”的现象。虽然AI在虚拟环境中可以生成流畅的文本或图像,但在驱动机械臂完成精细操作时往往表现不佳。这背后反映的是人工智能领域一个经典悖论——莫拉维克悖论(Moravec's Paradox):对人类而言轻而易举的感知与运动技能,对AI来说却异常困难;而需要高度抽象思维的任务(如下棋),AI反而能轻易超越人类。 为系统性攻克这一根本挑战,浙江大学刘大勇教授团队联合三一重工、香港理工大学及伦敦帝国理工学院等机构,共同提出了一套全新的评测基准——CFG-Bench。该基准不仅是一个数据集,更是一种完整的动作理解评测与训练范式。其目标在于推动AI从表层的动作识别迈向深度的动作理解,为构建能在物理世界中高效、安全执行任务的智能体提供一把精确的“标尺”和一本实用的“教科书”。一、具身智能的认知瓶颈:跨越“识别”到“理解”的鸿沟

具身智能的核心在于让智能体通过与物理环境的持续交互来学习和完成任务。实现这一目标的关键,在于智能体能否精准感知并深入理解周围环境,尤其是人类执行的各种动作。目前主流技术依赖大规模预训练模型,但在精细动作的理解上普遍存在结构性缺陷。
1.1 多模态大模型的“认知浅表化”
当前主流的多模态大模型,如GPT-4V、Gemini等,其强大性能主要源于在海量互联网图文数据上的训练。这种方式使其擅长建立宏观层面的语义关联。
优势:模型能够快速识别视频中的主体、客体及基本行为。例如,看到某人手持网球拍在球场挥动,模型可准确判断为“打网球”。
局限:此类识别基于模式匹配,而非对物理规律与动作机理的深层掌握。模型虽知“打网球”这一标签,却不真正“理解”其中的关键要素:
- 动力学细节:正手击球过程中身体重心转移、腰部旋转角度、手臂挥拍轨迹等,模型无法解析。
- 因果关系:为何需先侧身引拍再向前发力?因为这样可最大化力量传递效率和击球稳定性。模型缺乏对动作步骤间因果链的理解。
- 意图差异:同样是挥拍动作,可能是大力抽杀、削球或放小球,每种动作对应不同的战术目的,模型难以区分。
这种“认知浅表化”使得模型在面对需精确物理交互的任务时,所生成的规划或指令往往过于模糊且不具备可执行性。例如,它可能指示机器人“拿起杯子倒水”,却无法说明“应施加多大握力”、“杯口倾斜多少度合适”、“何时减缓水流以防溢出”等关键控制参数。
1.2 莫拉维克悖论在大模型时代的重现
莫拉维克悖论最早出现在早期机器人研究中:机器人难以完成行走或抓取等简单动作,而计算机程序却能在国际象棋比赛中击败世界冠军。如今,在大模型时代,这一悖论以新的形式再次显现:
| 能力维度 | 人类表现 | 当前AI大模型表现 | 悖论体现 |
|---|---|---|---|
| 抽象推理 | 需长期学习与训练(如编程、数学、写作) | 表现优异,常超越人类平均水平 | 对人类困难的任务,对AI相对容易 |
| 感知-运动 | 天生具备,无需刻意学习(如走路、开门、用筷子) | 表现笨拙,难以复现精细动作 | 对人类简单的任务,对AI极其困难 |
CFG-Bench的研究通过量化实验,为这一悖论提供了新的实证支持。研究表明,即使模型规模与训练数据量达到空前水平,AI在物理直觉(Physical Intuition)与具身认知(Embodied Cognition)方面的短板依然明显。模型或许能创作一部关于烹饪的小说,但却无法准确描述“如何打出一个不破黄的鸡蛋”。这种能力上的割裂,成为制约通用人工智能(AGI)走向现实物理世界的主要障碍。
1.3 现有评测基准的局限性
在CFG-Bench问世之前,视频理解领域的主流评测基准大多聚焦于以下方向:
行为分类(Action Classification):以Kinetics、Something-Something等数据集为代表,任务是为视频分配一个明确的行为类别标签。
时序定位(Temporal Localization):目标是在较长的视频流中精确定位某一行为发生的起始与结束时间点。
视频问答(Video QA):例如MSRVTT-QA这类任务,问题通常聚焦于视频内容的高层语义理解,较少深入探讨具体的物理交互过程或动作执行细节。
尽管这些基准推动了视频理解技术的进步,但它们普遍存在一个关键缺陷——评测粒度过粗。它们难以有效评估模型对动作执行细节、因果关系以及行为质量的深层理解能力。因此,即便某个模型在上述标准上表现优异,当应用于真实机器人任务时,仍可能只是一个“纸上谈兵”的理论模型,而非具备实际操作能力的“实践者”。行业迫切需要一种面向真实物理交互、能够填补理论与实践鸿沟的新一代评测体系。
二、CFG-Bench 技术范式深度解析
CFG-Bench 的构建标志着对现有评测机制的根本性突破。它不仅是一个数据集合,更是一套融合认知科学理念的完整评测框架。其设计思想、数据生成方式及评估机制共同构成了一种全新的技术范式。
2.1 设计哲学与核心定位:机器人的“动作教科书”
CFG-Bench 的定位清晰而深远——致力于成为机器人和具身智能体的“动作理解教科书”与“标准化考试卷”。
作为“教科书”:它提供结构化的学习资源。通过高精度标注的视频片段与多层级问答对,模型可以系统掌握人类执行复杂动作的方式,理解背后蕴含的物理规律与行为意图。这种高质量、有监督的数据为模型训练提供了强有力的支持。
作为“考试卷”:它建立了一套统一且可复现的评测流程。研究者可通过该平台客观比较不同模型在精细动作理解方面的能力差异,识别短板,指导后续优化方向。这使得原本模糊的“动作理解”概念变得可量化、可比较。
这一双重角色使其超越传统数据集的功能边界,演变为支撑领域长期发展的基础性设施。
2.2 数据集构建:规模、粒度与场景多样性
评测基准的有效性首先依赖于数据本身的质量。CFG-Bench 在数据采集与处理阶段投入大量人力,确保在规模、标注细粒度和应用场景覆盖上的全面性。
2.2.1 核心数据参数
| 参数项 | 具体数值/描述 | 说明 |
|---|---|---|
| 视频片段数量 | 1,368 | 经过严格筛选,保证动作清晰、完整且具有代表性 |
| 问答对数量 | 19,562 | 平均每段视频配套约14组问答,实现多角度、深层次考察 |
| 场景覆盖 | 日常生活、家务劳动、户外活动、工业操作等 | 涵盖机器人未来可能面对的多种典型现实情境 |
| 标注团队 | 10位专业标注员 | 均接受系统培训,保障标注标准一致性和结果可靠性 |
| 标注周期 | 超过1个月 | 采用逐帧分析与细致描述,确保标注达到极高粒度水平 |
2.2.2 超高精细度的标注体系
CFG-Bench 的核心竞争力在于其前所未有的标注精度,要求标注人员如同运动分析专家一般拆解每一个动作单元:
- 身体部位:精确到具体肢体乃至手指。例如,并非简单标注“用手拿起螺丝刀”,而是“用右手拇指与食指捏住螺丝刀握柄中上部”。
- 物理交互:需描述施力方向、强度和类型。如“用指尖轻压西瓜表面试探硬度”,而非笼统的“触摸西瓜”。
- 时序与节奏:记录动作的速度变化与节律特征。例如,“快速连续切丁并保持均匀节奏”,而不是简单的“切菜”。
- 工具使用:详细刻画工具与物体、身体之间的协作关系。例如,“刀刃与砧板呈约30度角,以推拉方式切割”。
这种超越常规语义表达的物理级标注,为模型学习真实世界中的交互细节提供了极为稀缺的高质量训练资源。
2.3 核心创新:四层递进式认知评测架构
CFG-Bench 最具突破性的贡献在于提出了一套模拟人类认知过程的四层递进式评测框架。这四个层次由具体感知逐步上升至抽象推理,系统覆盖动作理解的全部维度。
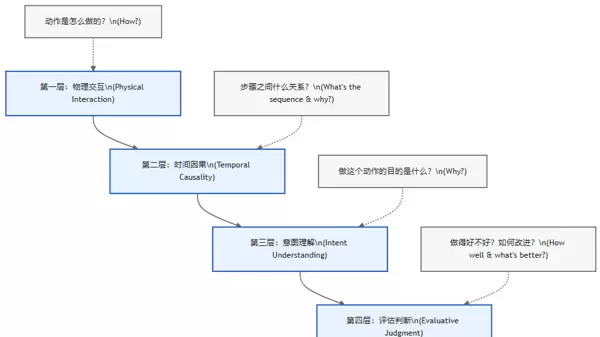
2.4 评测机制的鲁棒性设计:反事实问题引入
为防止模型仅靠模式匹配“蒙混过关”,CFG-Bench 引入大量反事实问题(Counterfactual Questions),即在问题陈述中故意嵌入与视频事实相悖的信息。
示例对比:
- 常规问题:“请描述视频中如何用手转动踏板来清洁自行车链条。”
- 反事实问题:“你是如何用脚踩踏板来刷链条的?”
面对此类问题,仅依赖表层关联的模型容易被误导,基于错误前提作答;而真正理解视频内容的模型则会首先识别并纠正题干中的错误,再给出准确回应。
理想回答示例:“问题描述有误。视频中并非用脚踩踏板,而是用右手手动转动踏板,同时左手持刷子对链条进行清洁。”
该机制显著增强了评测的信度与效度,确保最终得分能真实反映模型的逻辑推理与事实核查能力,而非单纯的文本生成技巧。
2.5 数据标注流程与质量控制机制
为了支撑四层级的深度评测需求,CFG-Bench 建立了一套高度严谨的数据生产流程,以保障数据的一致性与权威性。
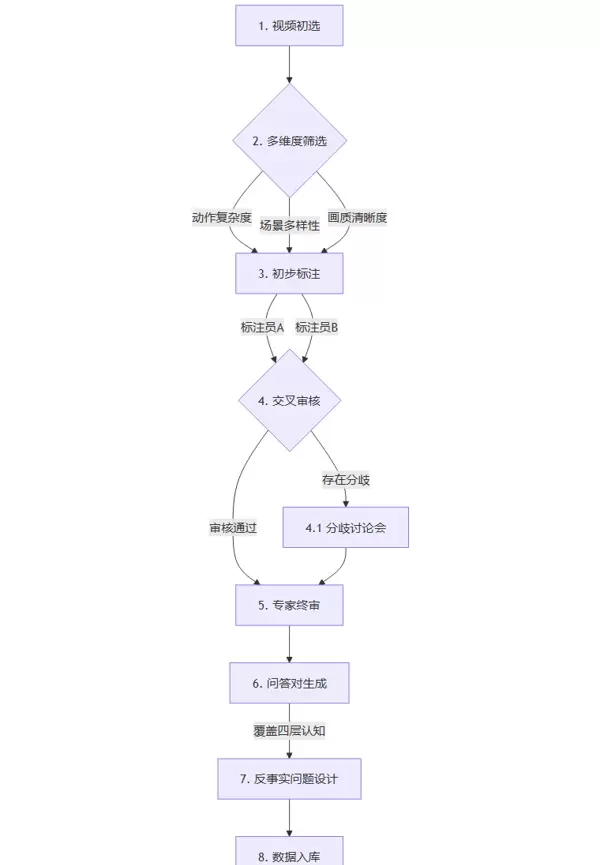
交叉审核机制:每个视频由至少两名标注员独立完成标注与问题设计。若两者输出存在分歧,则进入仲裁环节,由资深专家进行裁决,从而确保最终结果的客观性与一致性。
迭代式优化机制
在数据标注的实施过程中,团队会周期性地对已完成标注的数据进行抽样评估。基于评估反馈,持续完善标注规范与培训资料,从而构建一个动态循环、不断优化的改进体系。
三、实证研究:主流大模型的动作理解边界与发展路径

CFG-Bench不仅构建了一个理论分析框架,更通过系统性的实验验证,深入揭示了当前最先进的(SOTA)多模态大模型在精细动作理解方面的真实能力水平,并证实了该数据集作为训练资源的有效性。
3.1 能力差距:SOTA 模型与人类表现对比
研究团队利用 CFG-Bench 对包括 Gemini-2.5-Pro 在内的多个前沿多模态模型进行了全面测评。同时,为建立可靠参照,也组织人类受试者完成相同任务。测试结果清晰呈现出 AI 与人类之间显著的性能鸿沟。
3.1.1 开放式问题得分对比(满分10分)
| 评测对象 | 平均得分 | 核心结论 |
|---|---|---|
| 人类平均水平 | 9.05 | 人类能够准确且完整地捕捉和描述动作中的各个细节维度 |
| Gemini-2.5-Pro(最优模型) | 5.40 | 即便表现最佳的AI模型,其得分仅达及格线,远低于人类水平 |
| 其他开源/商业模型 | 普遍低于5.0 | 多数模型在复杂动作解析上存在严重缺陷 |
这一结果有力说明,当前AI在精细动作理解领域仍处于初级阶段,尚未达到实际可用的标准。“5.4分”成为衡量现有技术水平的一个关键指标——它意味着模型或许能应对基础性问题,但在面对复杂、细致的情境时极易出错。
3.2 主要错误类型分析
通过对模型输出错误的系统归类,研究人员识别出若干典型且深层的认知偏差模式,这些模式反映了模型在推理机制上的根本局限。
3.2.1 细节缺失(Detail Omission)
现象:模型可识别整体动作,但忽略执行过程中的关键物理细节。
示例输出:“机械臂拿起瓶子,将液体倒入杯子。”
真实情况:需先以特定夹爪姿态固定瓶柄,抬升后精确旋转并倾斜实现倾倒。
根源分析:模型缺乏对物理交互常识的理解,无法意识到“拿起”或“倾倒”是由一系列微观操作构成的复合行为。
3.2.2 多部位协同理解障碍(Difficulty with Coordination)
场景示例:一人左手压住木板,右手使用电钻打孔。
模型表现:能分别识别“手按木板”和“电钻工作”,但无法表达两者间的协同关系——即左手施压是为了抵抗钻头反作用力,防止滑动,属于动态力学平衡过程。
根源分析:注意力机制难以同步处理视频中多个运动焦点及其潜在物理关联,导致割裂式理解。
3.2.3 启发式推断偏差(Over-simplified Heuristics)
场景示例:某人手持锤子靠近钉子。
模型判断:直接推断“他要用锤子敲钉子”。
实际情况可能:此人意图是用锤子的羊角部分拔出钉子。
根源分析:源于训练数据中的统计偏见。由于“锤子+钉子”常与“敲击”共现,模型形成刻板联想,而非依据视觉证据进行因果推理。
3.2.4 积极性偏见(Positivity Bias)
场景示例:个体成功举起重物,但采用弯腰而非屈膝的危险姿势。
模型评价:“操作者完成了任务。”
问题所在:忽略了动作过程的安全性与规范性。
根源分析:模型缺少对“过程质量”的评判标准,其价值取向偏向结果导向。这种倾向在强调安全规程的实际应用中可能带来严重风险。
3.3 从评估到提升:微调驱动的能力跃迁
CFG-Bench 的意义不仅在于暴露问题,更在于提供解决方案。研究团队使用其高质量标注数据对 Qwen2.5-VL 等多模态模型进行微调,实验结果显示,针对性训练可显著增强模型在机器人控制任务中的实际表现。
3.3.1 机器人任务性能提升数据
| 任务类型 | 性能提升幅度 | 能力解读 |
|---|---|---|
| 高层规划任务 | +106% | 生成的任务步骤更合理、详尽,具备更强的可执行性 |
| 低层控制任务 | +59% | 输出指令能更精准映射到底层机器人动作,如抓取角度与运动轨迹 |
这些提升具有突破性意义,明确表明:精细动作理解是机器人规划与控制能力的前提。唯有真正“读懂”人类的操作方式,AI 才能有效“教会”机器人模仿与执行。
3.3.2 视频描述能力的质变
微调前描述:“机械臂接近玻璃和瓶子。机械臂拿起瓶子。机械臂倾斜瓶子并将液体倒入玻璃。”
评价:典型的流水账式叙述,仅罗列事件顺序,缺乏物理状态与动作细节。
微调后描述:(内容未提供,但指代模型已能输出包含姿态、力度、轨迹等信息的精细化描述)
机械手从画面左侧开始定位,缓慢向桌面上的玻璃瓶移动。接近后,手指精准夹住瓶身把手部位,轻柔地将瓶子抬离桌面。随后,瓶子被逆时针旋转,使瓶口对准下方的玻璃器皿,接着倾斜瓶身完成液体倾倒动作。
评价:该描述涵盖了多个关键物理细节,包括初始定位、运动轨迹、抓取位置、微操作(如抬起与旋转)、以及物体间的相对空间关系。此类高密度信息具备转化为机器人可执行指令的潜力,显示出较强的可操作性基础。
3.4 性能提升的内在机制
在使用CFG-Bench数据对模型进行微调后,机器人任务表现显著增强。这一提升可从三个层面解析:动作表征的精细化、推理链的显式化构建,以及策略生成的上下文适应能力。
3.4.1 动作表征空间的精细化
传统动作识别数据集通常引导模型学习较为粗略的动作表示,导致相似行为(例如“推动”与“轻抚”)在特征空间中距离相近。而CFG-Bench通过精细标注和多维度问答,促使模型关注动作中的细微差异,如施力程度、速度变化及接触方式。
解耦表征(Disentangled Representation):模型被驱动将复杂动作分解为多个独立语义维度,例如:
动作主体作用对象使用工具施力方式目标
这种结构化的表征方式增强了模型对新任务的泛化能力,使其能够灵活组合已有动作知识以应对未知场景。
3.4.2 显式推理链的形成
开放式问答任务,尤其是涉及因果逻辑与行为意图的问题,要求模型输出连贯且合乎逻辑的语言解释。这一过程实质上训练了模型建立一条从“视觉输入”到“语义结论”的显式推理路径。
从感知到理解:当模型被问及“为何需先摇晃瓶子再开启?”时,必须激活内部知识库,并关联至“混合液体”等功能性概念。这种训练强化了其跨模态、多步骤推理的能力,可直接迁移至机器人高层任务规划中,实现更智能的决策支持。
3.4.3 上下文感知的策略生成能力
机器人低层控制的核心在于根据当前环境状态生成最优动作策略。CFG-Bench所提供的丰富上下文训练样本,显著提升了模型对情境的理解深度。
精准的状态评估:通过学习判断人类动作的优劣,模型掌握了如何评价特定状态的好坏。例如,它能识别“不稳定的抓握”属于应立即修正的不良状态。这使得机器人在实际执行过程中具备更强的实时反馈与动态调整能力。
四、从评测到实践:构建精细动作理解模型的关键路径
CFG-Bench的研究成果为开发者与科研人员提供了清晰方向。要打造真正具备精细动作理解能力的系统,必须在数据构建、模型架构、训练方法与评估体系四个环节进行系统性革新。
4.1 数据驱动:突破标签局限,聚焦物理细节
高质量数据是模型能力的基础。未来数据采集需超越简单的类别标签,深入捕捉动作背后的物理属性。
- 采集多模态物理信号:除视频外,还应整合动作捕捉(MoCap)、力觉反馈、物体三维建模等信息,为模型提供更全面的物理世界监督。
- 利用合成数据补充真实数据:借助物理仿真引擎生成大规模、多样化并带有精确物理标注的虚拟数据,有效缓解真实场景中数据获取成本高、标注困难的问题。
4.2 模型设计:融合结构化先验知识
纯端到端模型在处理复杂物理推理时存在瓶颈。引入结构性先验知识是突破性能天花板的关键。
- 嵌入可微分物理仿真模块:在模型中集成物理引擎,使其能够预测动作后果并进行反事实推理。
- 采用图神经网络(GNNs):用图结构表达场景中物体及其相互作用关系,有助于模型理解协同操作与动态交互过程。
4.3 训练策略:多任务与课程式学习结合
精细动作理解是一项多层次复合能力,需要精心设计的训练流程来逐步培养。
- 实施课程学习(Curriculum Learning):依据CFG-Bench提出的四层认知框架设计递进式训练课程——先掌握“物理交互”,再依次引入“时间因果”、“行为意图”和“动作评估”,遵循由简入繁的认知规律。
- 推行多任务联合训练:同步训练动作分类、物理属性预测、因果问答等任务,促进模型提取更具通用性和鲁棒性的特征表示。
4.4 评估范式:迈向闭环与仿真实验
传统的离线问答评估已不足以衡量真实应用能力。
- 推行“在环”评估(In-the-Loop Evaluation):将模型输出(如动作规划或控制指令)直接接入物理模拟器或实体机器人,通过任务执行的实际效果反向评估模型性能,形成“感知—决策—执行—反馈”的完整闭环。
五、行业应用与长远意义

CFG-Bench的意义不仅限于学术探索,更为机器人技术在关键产业的落地提供了坚实支撑。
5.1 家庭与服务型机器人
细腻的动作理解是家用机器人安全、高效协助人类完成日常事务的前提。
- 家务任务执行:在烹饪、清洁等场景中,机器人需理解不同食材的处理方式、各类工具的正确使用方法。CFG-Bench为训练此类“生活技能”设立了新的标准。
- 养老照护辅助:在帮助老人起居、进食等敏感场景中,动作的安全性与柔和度至关重要。只有具备精细动作理解能力的机器人,才能成为值得信赖的生活助手,而非潜在的安全隐患。
5.2 工业自动化与柔性制造
现代工业,尤其是在柔性产线和人机协作环境中,对机器人的智能化水平提出更高要求。
- 替代固定程序作业:传统工业机器人依赖预设路径,难以适应动态变化。基于CFG-Bench训练的模型可使机器人具备更强的情境适应能力,实现真正的智能作业。
传统的工业机器人通常只能执行预先编程的固定动作,缺乏对动态环境的适应能力。而通过CFG-Bench这类数据集训练的AI系统,则能够使机器人具备理解并模仿人类工人复杂操作的能力,从而胜任更加多样化和灵活的生产任务。

人机协作:迈向深度交互的新阶段
在协作型工业机器人应用场景中,机器人必须能够实时感知并准确理解人类同事的动作与意图,以确保协同作业的安全性与效率。CFG-Bench为此类高阶人机交互提供了有效的评估框架与训练基础,推动机器人从被动执行向主动配合演进。
六、对多模态模型架构发展的关键启示
CFG-Bench的提出不仅是一项评测工具的创新,更对下一代多模态大模型——尤其是面向具身智能的系统架构——指明了重要的技术发展方向。
6.1 从感知到结构化认知的跃迁
当前主流的多模态模型(如基于ViT+LLM的架构)本质上仍属于“感知-语言”映射系统,擅长识别但弱于推理。未来的发展方向应聚焦于实现更高层次的认知能力。这意味着模型需要超越简单的特征匹配,转向具备逻辑推导与因果分析能力的结构化理解体系。
模块化与神经符号融合架构
未来的模型可能采用更加模块化的设计思路,例如引入独立的物理仿真模块、因果推理模块以及意图规划模块。这些功能模块可与端到端神经网络结合,形成神经符号混合系统,在保留深度学习强大感知能力的同时,增强模型的可解释性与逻辑推理水平。
6.2 隐式构建物理世界模型
一个能够在CFG-Bench上表现优异的模型,必然在其内部隐式地建立了一个关于物理规律运作的“世界模型”。这种内在模型使其能预测物体运动、判断力的作用效果,并理解动作背后的物理约束。
强化自监督学习机制
未来的训练策略将更依赖自监督学习方式,例如通过预测视频下一帧内容、推断动作引发的物理结果等任务,驱动模型自主学习现实世界的运行规则。CFG-Bench可作为强监督信号,用于校准和微调由自监督过程初步构建的世界模型,提升其准确性与泛化能力。
6.3 实现深度时空融合与细粒度跨模态对齐
要真正理解精细动作,模型必须在时间和空间维度上实现视频与语言信息的高度精确对齐。
革新时空注意力机制
需发展更为先进的时空注意力结构,使其既能捕捉瞬时动态(如敲击或捏合的瞬间),也能建模长期依赖关系(如多步骤装配流程的整体逻辑)。这要求模型具备多层次的时间感知能力。
推进跨模态层次化对齐
模型应能将文本中的动词(如“拧”、“压”)精准对应到视频中特定区域和时间片段,实现从局部肢体动作到整体行为意图的逐层解析,完成从像素到语义的无缝衔接。
6.4 引入记忆机制应对长程依赖挑战
对于涉及多个步骤、持续时间较长的任务,模型的记忆能力成为决定成败的关键因素。
外部记忆模块的集成
未来的具身智能体架构有望明确引入外部记忆单元,模拟人类工作记忆的功能。模型可将关键观察、中间状态或子目标存储其中,并在后续决策过程中读取使用,有效解决长序列任务中的时间因果断裂问题。
七、局限性分析与未来展望
尽管CFG-Bench具有开创意义,但仍存在若干局限,正视这些问题有助于推动其持续进化。
7.1 当前存在的主要局限
模型覆盖范围有限:受资源及API访问权限限制,研究未能涵盖所有领先的商业闭源大模型,因此尚无法全面评估当前AI在精细动作理解方面的性能上限。
专业领域覆盖不足:现有数据集主要集中于日常生活与通用场景,在外科手术、精密仪器组装等高度专业化领域的样本较为稀缺,制约了其在特定行业中的应用深度。
评估方式相对单一:目前主要依赖语言问答形式进行测评,难以区分模型是“未理解”还是“理解但表达受限”,可能存在误判风险。
7.2 未来发展方向
持续扩展数据集规模与广度:未来可通过社区协作,逐步将CFG-Bench拓展至医疗、航空航天、微电子制造等专业领域,构建覆盖更广、粒度更细的动作理解知识库。
构建多模态综合评估范式:探索将语言理解测试与物理仿真环境、真实机器人执行任务相结合的联合评估机制,从认知、决策到执行全链路衡量智能体的实际能力。
促进开放研究生态建设:随着更多研究团队采纳CFG-Bench,有望形成围绕精细动作理解的活跃学术共同体,共同推进机器人认知能力的技术突破。
结论
CFG-Bench的推出远不止是一个新数据集或评测基准的发布,而是通过一套系统化、层级化的构建方法,深刻揭示了当前人工智能在具身认知层面的核心短板,并为突破这些瓶颈提供了清晰的技术路径。
它成功地将研究焦点从宏观的“行为识别”引导至微观的“动作理解”,突出了物理交互、因果推理、意图识别与评估判断在打造真正智能体过程中的核心地位。
实证研究表明,提升精细动作的理解能力,可以直接增强机器人在高层任务规划与底层动作控制方面的综合表现,验证了“认知驱动执行”这一技术路线的可行性与高效性。
更重要的是,CFG-Bench对未来AI模型架构提出了明确要求:未来的系统必须超越简单的感知映射,发展出结构化推理能力,建立对物理世界的深层理解,并具备长时记忆与精准时空对齐机制。这预示着一种融合模块化设计、自监督学习与神经符号思想的新一代具身智能架构正在成型。
综上所述,CFG-Bench既是检验当前AI能力的一面“照妖镜”,也是指引未来技术演进的一座“灯塔”。它为衡量和推动机器人从“看得见”到“做得来”,再到“做得好”的演进过程,提供了一项不可或缺的量化标尺。

 京公网安备 11010802022788号
京公网安备 11010802022788号







